1. Einleitung
Unter dem Begriff „verteiltes Monitoring“ (distributed monitoring) versteht wahrscheinlich nicht jeder das Gleiche. Und eigentlich ist Monitoring ja immer über viele Rechner verteilt — solange das Monitoring-System nicht nur sich selbst überwacht, was schließlich wenig nützlich wäre.
In diesem Handbuch sprechen wir immer dann von einem verteilten Monitoring, wenn das gesamte Monitoring-System aus mehr als einer Checkmk-Instanz besteht. Dabei gibt es verschiedene Gründe für das Aufteilen in mehrere Instanzen:
Performance: Die Rechenlast des Monitorings soll oder muss auf mehrere Maschinen verteilt werden.
Organisation: Die Instanzen sollen von unterschiedlichen Personenkreisen eigenverantwortlich administriert werden.
Verfügbarkeit: Das Monitoring an einem Standort soll unabhängig von anderen Standorten funktionieren.
Sicherheit: Datenströme zwischen zwei Sicherheitsbereichen sollen getrennt und genau kontrolliert werden (DMZ etc.).
Netzwerk: Standorte, die nur schmalbandig oder unzuverlässig angebunden sind, können nicht zuverlässig von der Ferne aus überwacht werden.
Checkmk unterstützt mehrere Verfahren für den Aufbau eines verteilten
Monitorings. Manche davon beherrscht Checkmk, weil es mit Nagios weitgehend
kompatibel ist bzw. darauf aufbaut (falls Nagios als Kern eingestellt
wurde). Dazu gehören z.B. das alte Verfahren mit NSCA und das etwas modernere
mit mod_gearman. Diese bieten gegenüber den Checkmk-eigenen
Verfahren keine Vorteile und sind noch dazu umständlicher einzurichten.
Wir empfehlen sie daher nicht.
Das von Checkmk bevorzugte Verfahren basiert auf Livestatus und einer automatischen Konfigurationsverteilung. Für Situationen mit stark abgeschotteten Netzen oder sogar einer strikt unidirektionalen Datenübertragung von der Peripherie in die Zentrale gibt es eine Methode mit Livedump bzw. CMCDump. Beide Methoden können kombiniert werden.
2. Verteiltes Monitoring mit Livestatus
2.1. Grundprinzip
Zentraler Status
Livestatus ist eine in den Monitoring-Kern integrierte Schnittstelle, mit der andere Programme von außen Statusdaten abfragen und Kommandos ausführen können. Livestatus kann über das Netzwerk verfügbar gemacht werden, so dass eine entfernte Checkmk-Instanz (Remote-Instanz) zugreifen kann. Die Benutzeroberfläche von Checkmk nutzt Livestatus, um alle angebundenen Instanzen zu einer Gesamtsicht zusammenzuführen. Das fühlt sich dann „wie ein großes" Monitoring-System an.
Folgende Skizze zeigt schematisch den Aufbau eines verteilten Monitorings mit Livestatus über drei Standorte. In der Zentrale befindet sich die Checkmk-Instanz Central Site. Von dieser aus werden zentrale Systeme direkt überwacht. Außerdem gibt es die Instanzen Remote Site 1 und Remote Site 2, welche sich in anderen Netzen befinden und die dortigen Systeme überwachen:
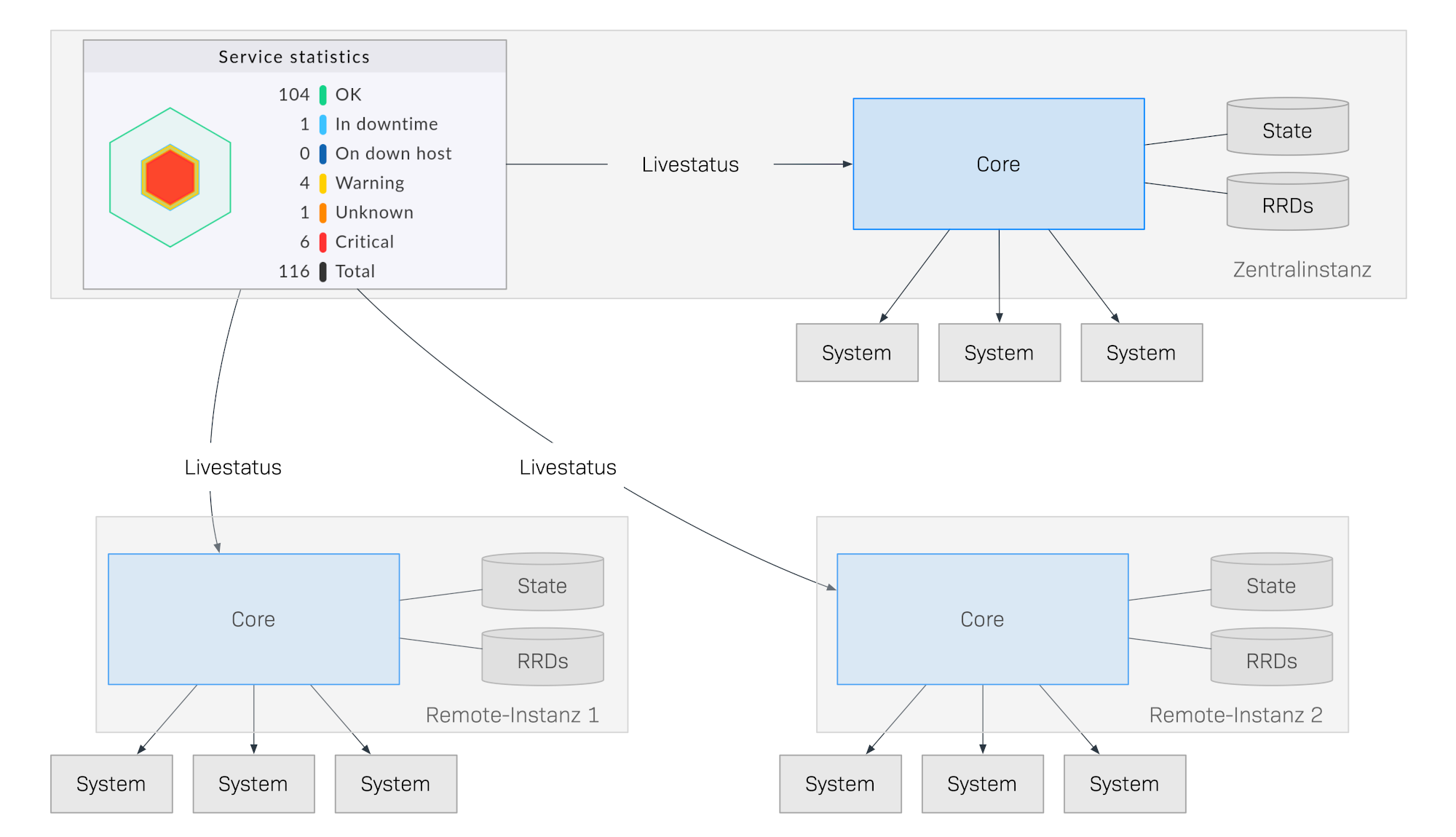
Das Besondere an dieser Methode ist, dass der Monitoring-Status der entfernten Instanzen nicht ständig an die Zentrale übertragen wird. Die GUI ruft von den entfernten Instanzen immer nur live diejenigen Daten ab, die ein Benutzer in der Zentrale haben will. Die Daten werden dann in einer kombinierten Ansicht zusammengeführt. Es gibt also keine zentrale Datenhaltung, was riesige Vorteile für die Skalierung bedeutet!
Hier sind einige der Vorteile dieser Methode:
Skalierung: Das Monitoring selbst erzeugt keinerlei Netzwerkverkehr zwischen der Zentralinstanz und Remote-Instanz. Dadurch können hundert und mehr Standorte angebunden werden.
Zuverlässigkeit: Fällt die Netzwerkverbindung zu einer Remote-Instanz aus, so geht das Monitoring dort trotzdem völlig normal weiter. Es gibt keine Lücke in der Datenaufzeichnung und auch keinen Datenstau. Lokale Benachrichtigungen funktionieren weiterhin.
Einfachheit: Instanzen können sehr einfach eingebunden und wieder entfernt werden.
Flexibilität: Die Remote-Instanzen sind weiterhin eigenständig und können an dem jeweiligen Standort für das Operating genutzt werden. Das ist insbesondere dann interessant, wenn der „Standort“ auf keinen Fall Zugriff auf den Rest des Monitorings haben darf.
Zentrale Konfiguration
Bei einem verteilten System via Livestatus wie oben beschrieben, ist es durchaus möglich, dass die einzelnen Instanzen von unterschiedlichen Teams eigenverantwortlich gepflegt werden und die Zentralinstanz lediglich die Aufgabe hat, ein zentrales Dashboard bereitzustellen.
Falls aber mehrere oder alle Instanzen von den gleichen Menschen administriert werden sollen, ist eine zentrale Konfiguration viel komfortabler. Checkmk unterstützt dies und wir sprechen dann von einer verteilten Konfigurationsumgebung. Dabei werden alle Hosts und Services, Benutzer und Rechte, Zeitperioden, Benachrichtigungen u.s.w. im Setup der Zentralinstanz zentral gepflegt und dann automatisch nach Ihren Vorgaben auf die Remote-Instanzen verteilt.
So ein System hat nicht nur eine gemeinsame Statusoberfläche, sondern auch eine gemeinsame Konfiguration und fühlt sich dann endgültig wie „ein großes System“ an.
Sie können solch ein System sogar noch um reine Viewer-Instanzen erweitern, die nur als Statusoberflächen dienen, etwa für Teilbereiche oder bestimmte Nutzergruppen.
2.2. Verteiltes Monitoring aufsetzen
Das Aufsetzen eines verteilten Monitorings via Livestatus und verteilter Konfigurationsumgebung geschieht in folgenden Schritten:
Zentralinstanz zunächst ganz normal wie eine Einzelinstanz aufsetzen
Remote-Instanzen aufsetzen und Livestatus per Netzwerk freigeben
Auf der Zentralinstanz die Remote-Instanzen über Setup > General > Distributed monitoring einbinden
Bei Hosts und Ordnern festlegen, von welcher Instanz aus diese überwacht werden sollen
Serviceerkennung für umgezogene Hosts neu durchführen und Änderungen aktivieren
Zentralinstanz aufsetzen
An die Zentrale werden keine speziellen Anforderungen gestellt. Das bedeutet, dass Sie auch eine schon länger bestehende Instanz ohne weitere Anpassungen zu einem verteilten Monitoring ausbauen können.
Remote-Instanzen aufsetzen und Livestatus per Netzwerk freigeben
Die Remote-Instanzen werden zunächst als neue Instanzen wie üblich mit omd create erzeugt.
Dies geschieht dann natürlich auf dem (entfernten) Server, der für die jeweilige Remote-Instanz vorgesehen ist.
Hinweise:
Verwenden Sie für die Remote-Instanzen IDs, die in Ihrem verteilten Monitoring eindeutig sind.
Die Checkmk-Version (z.B. 2.0.0) der Remote- und Zentralinstanz ist dieselbe – ein Mischbetrieb wird nicht unterstützt. Die Patchlevel (z.B. p11) können zwar in den meisten Fällen unterschiedlich sein. In seltenen Fällen sind aber auch diese untereinander inkompatibel, so dass Sie den exakten Versionsstand (z.B. 2.0.0p11) auf allen Seiten einhalten müssen, damit eine fehlerfreie Zusammenarbeit der Instanzen möglich ist. Beachten Sie daher immer die inkompatiblen Änderungen zu jeder Patchversion in den Werks.
Da Checkmk mehrere Instanzen auf einem Server unterstützt, kann die Remote-Instanz auch auf dem gleichen Server laufen.
Hier ist ein Beispiel für das Anlegen einer Remote-Instanz mit dem Namen remote1:
root@linux# omd create remote1
Adding /opt/omd/sites/remote1/tmp to /etc/fstab.
Creating temporary filesystem /omd/sites/remote1/tmp...OK
Updating core configuration...
Generating configuration for core (type cmc)...
Starting full compilation for all hosts Creating global helper config...OK
Creating cmc protobuf configuration...OK
Executing post-create script "01_create-sample-config.py"...OK
Restarting Apache...OK
Created new site remote1 with version 2.1.0p17.cee.
The site can be started with omd start remote1.
The default web UI is available at http://myserver/remote1/
The admin user for the web applications is cmkadmin with password: lEnM8dUV
For command line administration of the site, log in with 'omd su remote1'
After logging in, you can change the password for cmkadmin with 'cmk-passwd cmkadmin'.Der wichtigste Schritt ist jetzt, dass Sie Livestatus via TCP auf dem Netzwerk
freigeben. Bitte beachten Sie dabei, dass Livestatus per se kein abgesichertes
Protokoll ist und nur in einem sicheren Netzwerk (abgesichertes LAN, VPN
etc.) verwendet werden darf. Das Freigeben geschieht als Instanzbenutzer
bei noch gestoppter Instanz per omd config:
root@linux# su - remote1
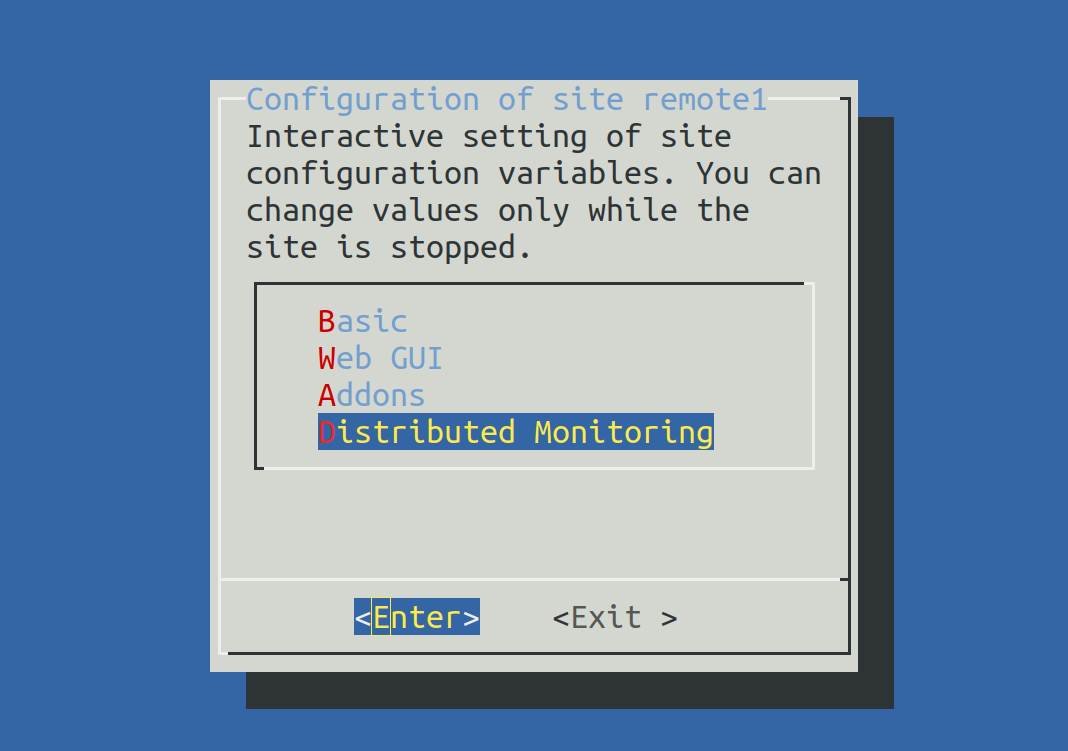
OMD[remote1]:~$ omd configWählen Sie jetzt Distributed Monitoring:
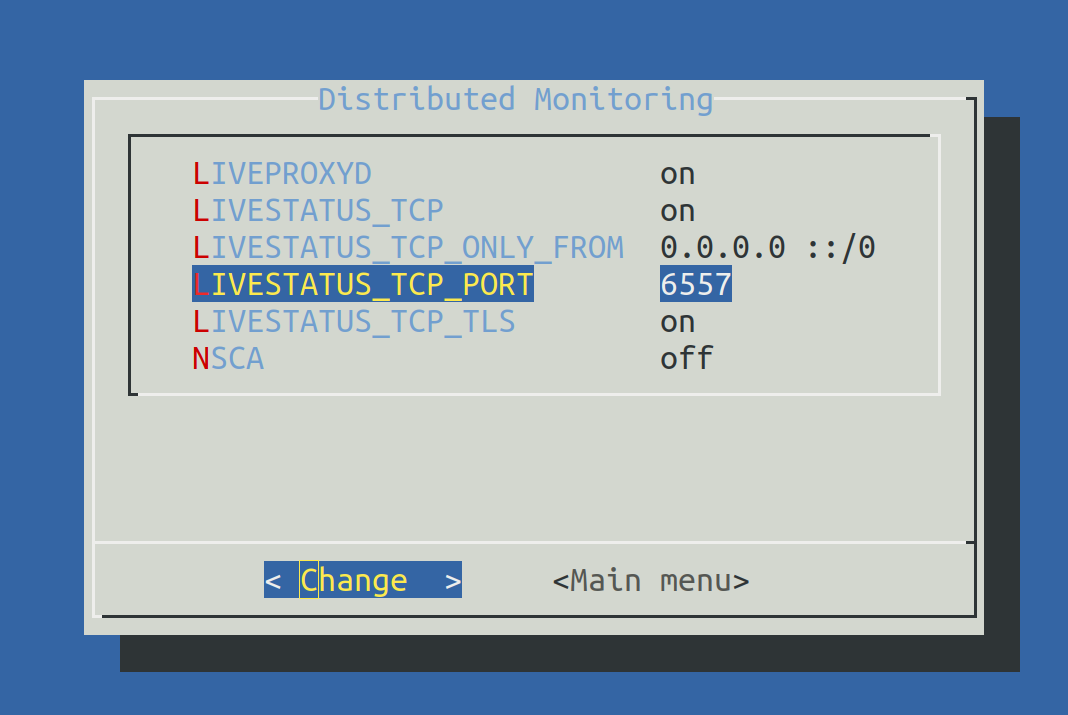
Setzen Sie LIVESTATUS_TCP auf on und tragen Sie für LIVESTATUS_TCP_PORT eine freie Portnummer ein, die auf diesem Server eindeutig ist. Der Default dafür ist 6557:
Nach dem Speichern starten Sie die Instanz wie gewohnt mit omd start:
OMD[remote1]:~$ omd start
Temporary filesystem already mounted
Starting mkeventd...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
Starting xinetd...OK
Initializing Crontab...OKMerken Sie sich das Passwort für cmkadmin. Sobald die Remote-Instanz der Zentralinstanz untergeordnet wurde,
werden sowieso alle Benutzer durch die von der Zentralinstanz ausgetauscht.
Die Instanz ist jetzt bereit. Eine Kontrolle mit netstat zeigt, dass
Port 6557 geöffnet ist. Die Bindung an diesen Port geschieht mit einer
Instanz des Hilfsdaemons xinetd, welcher direkt in der Instanz läuft:
root@linux# netstat -lnp | grep 6557
tcp6 0 0 :::6557 :::* LISTEN 10719/xinetdRemote-Instanzen in die Zentralinstanz einbinden
Die Konfiguration des verteilten Monitorings wird ausschließlich auf der Zentralinstanz im Menü Setup > General > Distributed Monitoring vorgenommen. Hier verwalten Sie die Verbindungen zu den einzelnen Instanzen. Dabei zählt die Zentrale selbst auch als Instanz und ist bereits in der Liste eingetragen:

Legen Sie jetzt mit ![]() Add connection die Verbindung zur ersten Remote-Instanz an:
Add connection die Verbindung zur ersten Remote-Instanz an:

Bei den Basic settings ist es wichtig, dass Sie als Site ID exakt den Namen der Remote-Instanz verwenden, so wie diese mit omd create erzeugt wurde.
Den Alias können Sie wie immer frei vergeben und auch später ändern.
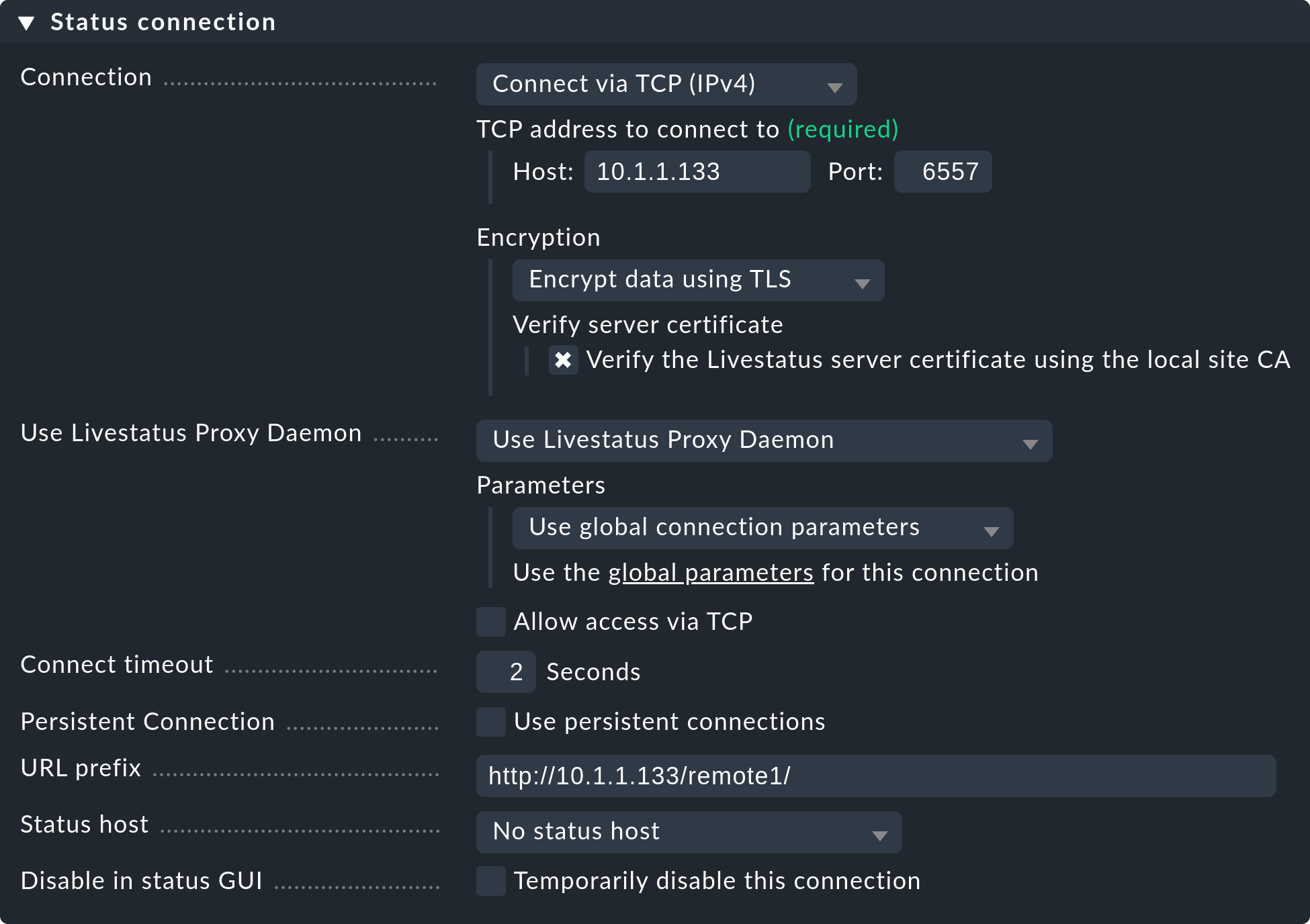
Bei den Einstellungen der Status connection geht es darum, wie die Zentralinstanz den Status der Remote-Instanzen per Livestatus abfragt. Das Beispiel im Screenshot zeigt eine Verbindung mit der Methode Connect via TCP(IPv4). Diese ist für stabile Verbindungen mit kurzen Latenzzeiten optimal (wie z.B. in einem LAN). Optimale Einstellungen bei WAN-Verbindungen besprechen wir weiter unten.
Tragen Sie hier die HTTP-URL zu der Weboberfläche der Remote-Instanz ein und zwar nur den Teil bis vor dem check_mk/.
Wenn Sie grundsätzlich per HTTPS auf Checkmk zugreifen, dann ersetzen Sie das http hier durch https.
Weitere Details erfahren Sie wie immer in der ![]() Onlinehilfe oder dem Handbuchartikel zu HTTPS mit Checkmk.
Onlinehilfe oder dem Handbuchartikel zu HTTPS mit Checkmk.
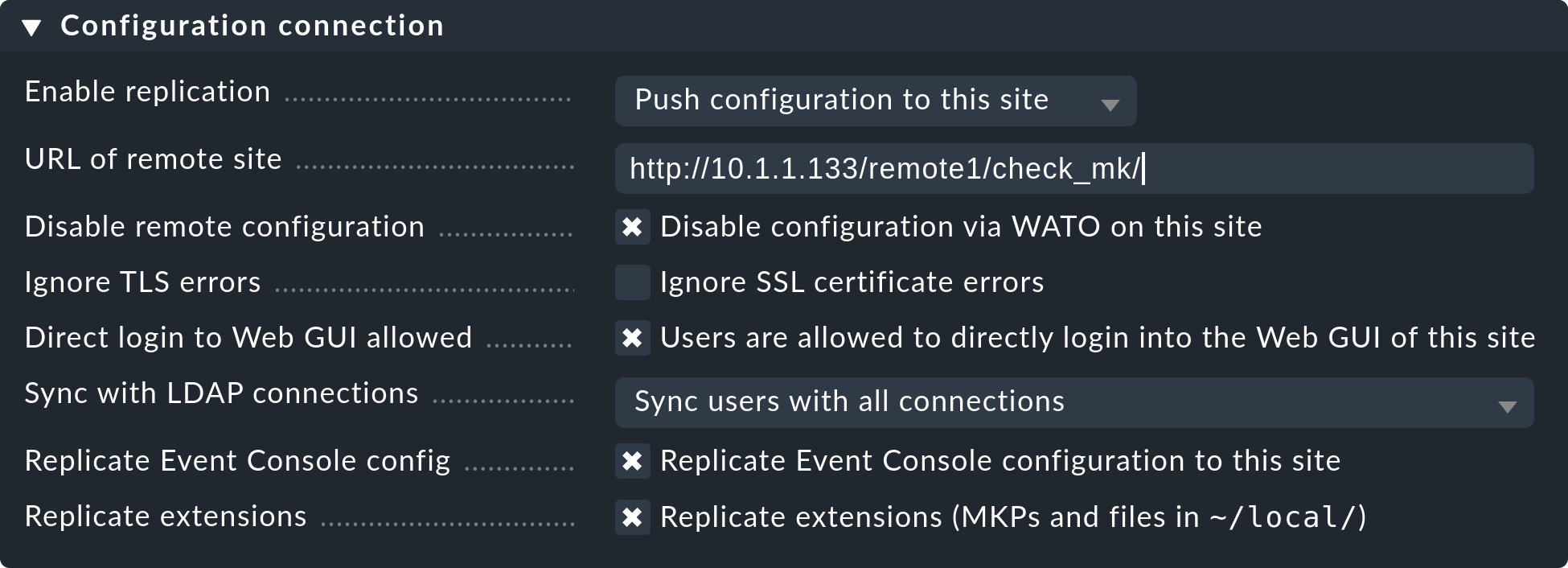
Das Replizieren der Konfiguration und somit die Verwendung der verteilten Konfigurationsumgebung ist, wie eingangs besprochen, optional. Aktivieren Sie die Replikation, wenn Sie die Remote-Instanz von der Zentralinstanz aus mitkonfigurieren möchten. In diesem Fall wählen Sie genau die Einstellungen, die Sie in obiger Abbildung sehen.
Sehr wichtig ist eine korrekte Einstellung für URL of remote site.
Die URL muss immer mit /check_mk/ enden.
Eine Verbindung mit HTTPS ist empfehlenswert, setzt aber voraus, dass der Apache der Remote-Instanz HTTPS unterstützt.
Dies muss auf Linux-Ebene des entfernten Servers von Hand aufgesetzt werden.
Bei der Checkmk Appliance kann HTTPS über die webbasierte Konfigurationsoberfläche eingerichtet werden.
Falls Sie ein selbstsigniertes Zertifikat verwenden, benötigen Sie die Checkbox Ignore SSL certificate errors.
Nachdem Sie die Maske gespeichert haben, sehen Sie in der Übersicht eine zweite Instanz:

Der Monitoring-Status der (noch leeren) Remote-Instanz ist jetzt schon korrekt
eingebunden. Für eine verteilte Konfigurationsumgebung benötigen Sie noch einen Login auf die entfernte Instanz von Checkmk.
Dabei tauscht die Zentralinstanz mit der Remote-Instanz ein Anmeldegeheimnis aus, über das dann in Zukunft alle weitere Kommunikation abläuft.
Der Zugang cmkadmin auf der Instanz wird dann nicht mehr verwendet.
Verwenden Sie als Login credentials cmkadmin und das generierte Passwort der Remote-Instanz. Bestätigen Sie an dieser Stelle noch per Confirm overwrite, dass Sie mit die Einstellungen überschreiben wollen.

Ein erfolgreicher Login wird so quittiert:

Sollte es zu einem Fehler bei der Anmeldung kommen, kann dies verschiedene Gründe haben, z.B.:
Die Remote-Instanz ist gerade gestoppt.
Die Multisite-URL of remote site ist nicht korrekt eingestellt.
Die Remote-Instanz ist unter dem in der URL eingestellten Hostnamen von der Zentralinstanz aus nicht erreichbar.
Zentralinstanz und Remote-Instanz haben (zu) unterschiedliche Checkmk-Versionen.
Benutzer und/oder Passwort sind falsch.
Die Punkte eins und zwei können Sie einfach testen, indem Sie die URL der Remote-Instanz von Hand in Ihrem Browser aufrufen.
Wenn alles geklappt hat, führen Sie nun ein Activate pending changes aus. Auf der Übersichtsseite der noch nicht aktivierten Änderungen sehen Sie auch eine Übersicht der Status der Livestatus-Verbindungen sowie des Synchronisationszustands der verteilten Konfigurationsumgebung der einzelnen Instanzen:
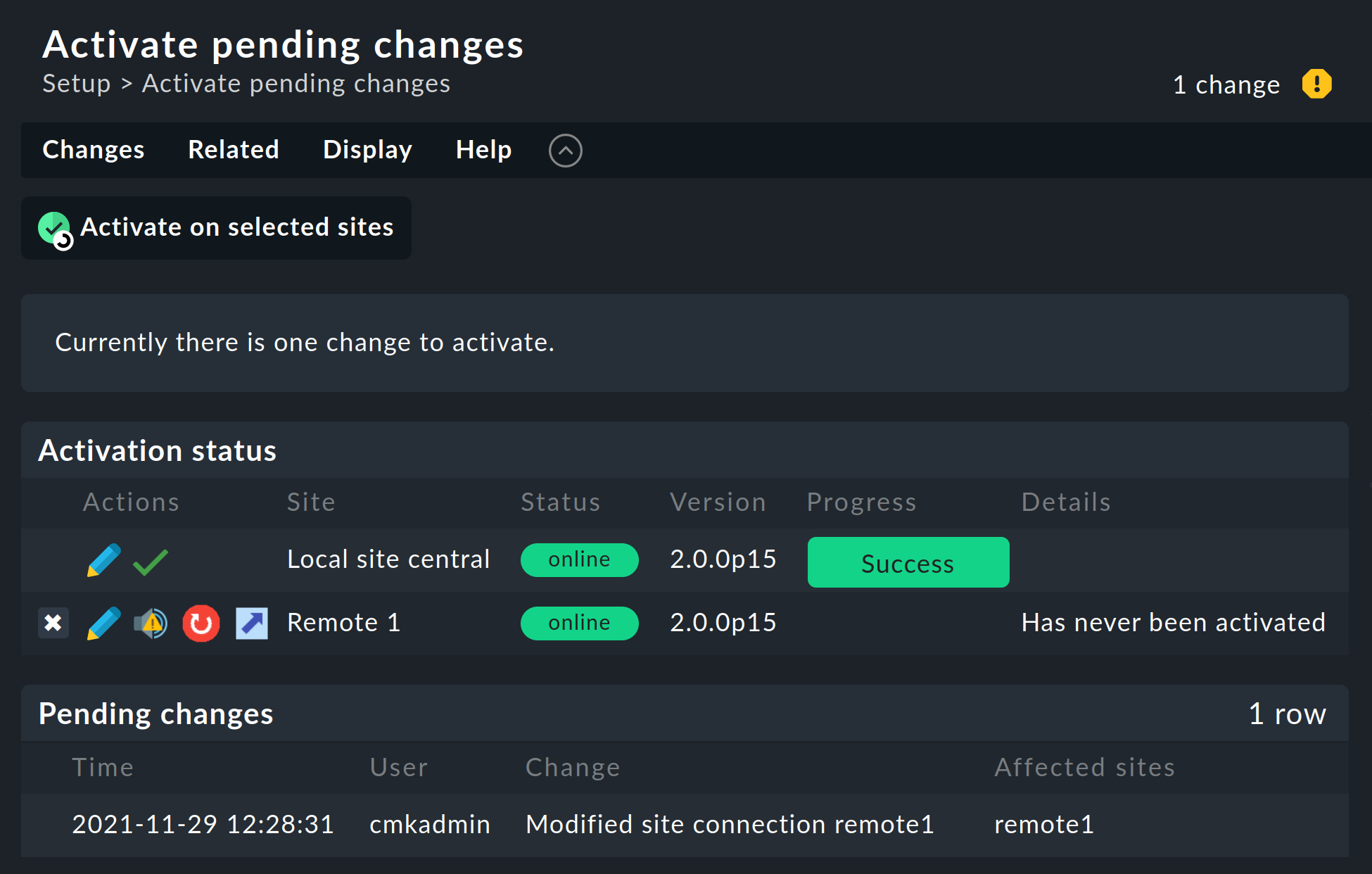
Die Spalte Version zeigt die Livestatus-Version der jeweiligen Instanz an.
Bei der Verwendung des CMC als Checkmk-Kern (Enterprise Editions) ist die Versionsnummer des Kerns
(Spalte Core) identisch mit der Livestatus-Version.
Falls Sie Nagios als Kern verwenden (![]() Checkmk Raw Edition), sehen Sie hier die Versionsnummer von Nagios.
Checkmk Raw Edition), sehen Sie hier die Versionsnummer von Nagios.
Folgende Symbole zeigen Ihnen den Replikationsstatus der Konfigurationsumgebung:
|
Diese Instanz hat ausstehende Änderungen und muss neu gestartet werden. Mit einem Klick auf den Knopf dem Knopf |
|
Die Konfigurationsumgebung dieser Instanz ist nicht synchron und muss übertragen werden. Danach ist dann natürlich auch ein Neustart notwendig, um die Konfiguration zu aktiveren. Beides zusammen erreichen Sie mit mit einem Klick auf den Knopf |
In der Spalte Status sehen Sie den Zustand der Livestatus-Verbindung zur jeweiligen Instanz. Dieser wird rein informativ angezeigt, da die Konfiguration ja nicht per Livestatus, sondern per HTTP übertragen wird. Folgende Werte sind möglich:
|
Die Instanz ist per Livestatus erreichbar. |
|
Die Instanz ist gerade nicht erreichbar. Livestatus-Anfragen laufen in einen Timeout. Dies verzögert den Seitenaufbau. Statusdaten dieser Instanz sind in der GUI nicht sichtbar. |
|
Die Instanz ist gerade nicht erreichbar, aber das ist aufgrund der Einrichtung eines Statushosts oder durch den Livestatus-Proxy bekannt (siehe unten). Die Nichterreichbarkeit führt nicht zu Timeouts. Statusdaten dieser Instanz sind in der GUI nicht sichtbar. |
|
Die Livestatus-Verbindung zu dieser Instanz ist vorübergehend durch den Administrator (der Zentralinstanz) deaktiviert worden. Die Einstellung entspricht der Checkbox Temporarily disable this connection in der Einstellung dieser Verbindung. |
Ein Klick auf ![]() Activate on selected sites synchronisiert nun alle Instanzen und aktiviert die Änderungen.
Dies geschieht parallel, so dass sich die Gesamtzeit nach der Dauer bei der langsamsten Instanz richtet.In der Zeit enthalten sind die Erstellung eines Konfigurationssnapshots für die jeweilige Instanz, das Übertragen per HTTP, das Auspacken des Snapshots auf der Instanz und das Aktivieren der Änderungen.
Activate on selected sites synchronisiert nun alle Instanzen und aktiviert die Änderungen.
Dies geschieht parallel, so dass sich die Gesamtzeit nach der Dauer bei der langsamsten Instanz richtet.In der Zeit enthalten sind die Erstellung eines Konfigurationssnapshots für die jeweilige Instanz, das Übertragen per HTTP, das Auspacken des Snapshots auf der Instanz und das Aktivieren der Änderungen.
Wichtig: Verlassen Sie die Seite nicht, bevor die Synchronisation auf alle Instanzen abgeschlossen wurde. Ein Verlassen der Seite unterbricht die Synchronisation.
Bei Hosts und Ordnern festlegen, von welcher Instanz aus diese überwacht werden sollen
Nachdem Ihre verteilte Umgebung eingerichtet ist, können Sie beginnen, diese zu nutzen. Eigentlich müssen Sie jetzt nur noch bei jedem Host sagen, von welcher Instanz aus dieser überwacht werden soll. Per Default ist die Zentralinstanz eingestellt.
Das nötige Attribut dazu heißt „Monitored on site“. Sie können das für jeden einzelnen Host individuell einstellen. Aber natürlich bietet es sich an, das auf Ordnerebene zu konfigurieren:
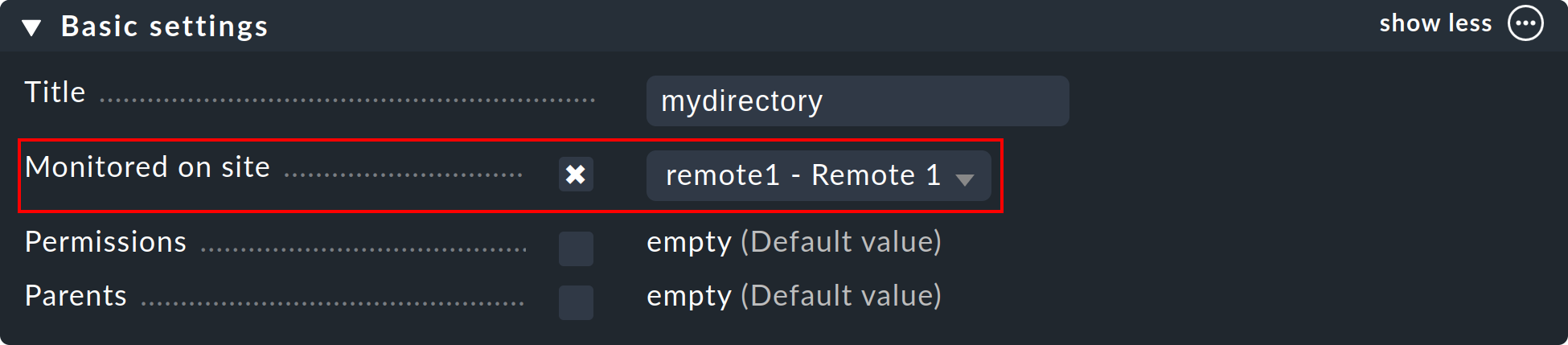
Serviceerkennung für umgezogene Hosts neu durchführen und Änderungen aktivieren
Das Aufnehmen von Hosts funktioniert wie gewohnt. Bis auf die Tatsache, dass die Überwachung und auch die Serviceerkennung von der jeweiligen Remote-Instanz durchgeführt wird, gibt es nichts Spezielles zu beachten.
Beim Umziehen von Hosts von einer zu einer anderen Instanz gibt es einige Dinge zu beachten. Denn es werden weder aktuelle noch historische Statusdaten dieser Hosts übernommen. Lediglich die Konfiguration des Hosts bleibt erhalten. Es ist quasi, als würden Sie den Host auf einer Instanz entfernen und auf der anderen neu anlegen. Das bedeutet unter anderem:
Automatisch erkannte Services werden nicht übernommen. Führen Sie daher nach dem Umziehen eine Serviceerkennung durch.
Host und Services beginnen wieder bei PEND. Zu eventuell aktuell vorhandenen Problemen werden neue Benachrichtigungen erzeugt und gegebenenfalls versendet.
Historische Metriken gehen verloren. Dies können Sie vermeiden, indem Sie betroffene RRD-Dateien von Hand kopieren. Die Lage der Dateien finden Sie unter Dateien und Verzeichnisse.
Daten zur Verfügbarkeit und zu historischen Ereignissen gehen verloren. Diese sind leider nicht so einfach zu migrieren, da diese Daten sich in einzelnen Zeilen im Monitoring-Log befinden.
Wenn die Kontinuität der Historie für Sie wichtig ist, sollten Sie schon beim Aufbau des Monitorings genau planen, welcher Host von wo aus überwacht werden soll.
2.3. Livestatus verschlüsselt anbinden
Livestatus-Verbindungen können zwischen der Zentralinstanz und einer Remote-Instanz verschlüsselt werden.
Bei neu erzeugten Instanzen müssen nichts weiter tun.
Checkmk kümmert sich automatisch um die nötigen Schritte.
Sobald Sie dann mittels omd config Livestatus aktivieren, ist die Verschlüsselung durch TLS automatisch aktiviert:
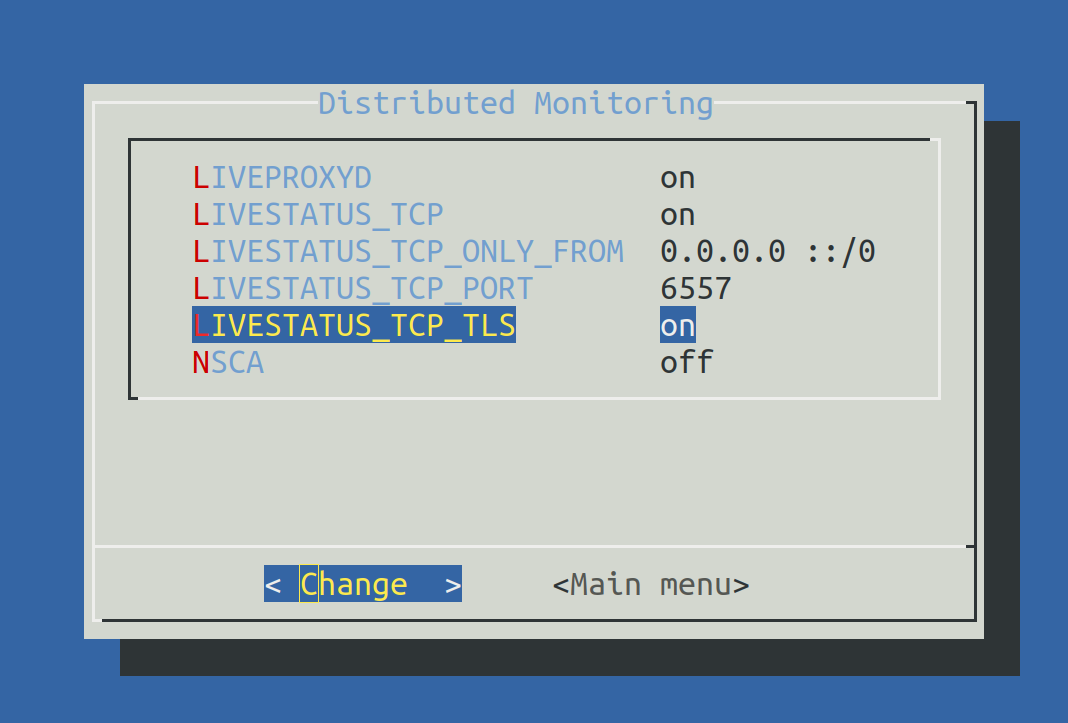
Die Konfiguration des verteilten Monitoring bleibt daher so einfach, wie bisher. Bei neuen Verbindungen zu anderen Instanzen ist dann die Option Encryption automatisch aktiviert.
Nachdem Sie die Remote-Instanz hinzugefügt haben, werden Sie zwei Dinge
bemerken: Zum einen wird die Verbindung durch das neue Icon ![]() als verschlüsselt markiert. Und zum anderen wird Checkmk Ihnen anzeigen,
dass der CA der Remote-Instanz nicht vertraut wird. Mit einem Klick
auf
als verschlüsselt markiert. Und zum anderen wird Checkmk Ihnen anzeigen,
dass der CA der Remote-Instanz nicht vertraut wird. Mit einem Klick
auf ![]() gelangen Sie in die Details der benutzten
Zertifikate. Mit einem Klick auf
gelangen Sie in die Details der benutzten
Zertifikate. Mit einem Klick auf ![]() können Sie die CA
bequem über die Weboberfläche hinzufügen. Danach werden beide Zertifikate
als vertrauenswürdig gelistet:
können Sie die CA
bequem über die Weboberfläche hinzufügen. Danach werden beide Zertifikate
als vertrauenswürdig gelistet:
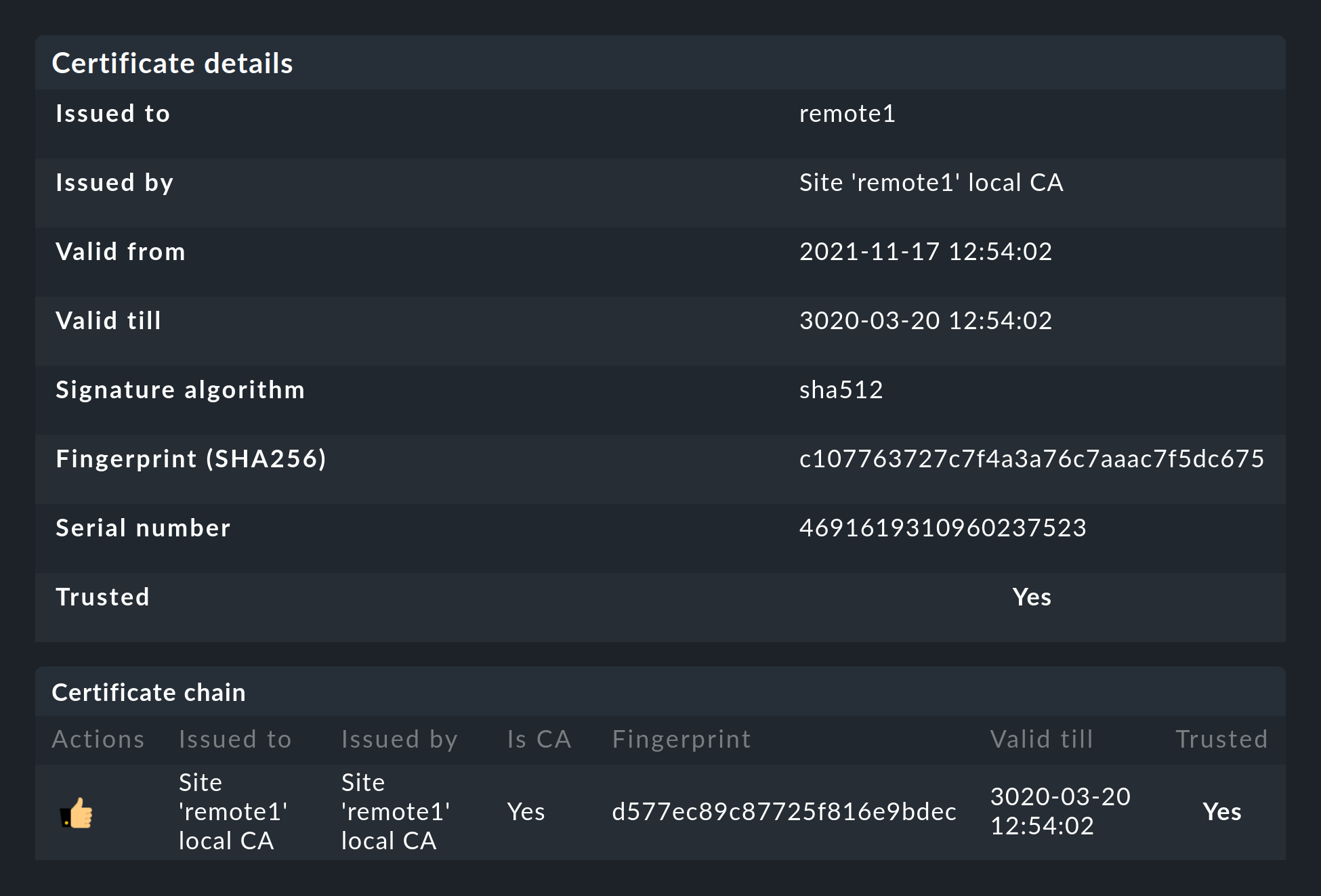
Details zu den eingesetzten Technologien
Um die Verschlüsselung zu realisieren, nutzt Checkmk das Programm
stunnel zusammen mit einem eigenen Zertifikat und einer eigenen
Certificate Authority (CA), mit der das Zertifikat signiert wird. Sie
werden bei einer neuen Instanz automatisch zusammen mit dieser individuell
erzeugt und sind daher keine vordefinierten, statischen CAs oder
Zertifikate. Das ist ein sehr wichtiger Sicherheitsfaktor, um zu verhindern,
dass gefälschte Zertifikate von Angreifern benutzt werden können, weil sie
Zugriff auf eine allgemein zugängliche CA bekommen konnten. Die erzeugten
Zertifikate haben zusätzlich folgende Eigenschaften:
Beide Zertifikate liegen in dem PEM-Format vor. Das signierte Zertifikate der Instanz enthält außerdem die komplette Zertifikatskette.
Die Schlüssel verwenden 2048-bit RSA und das Zertifikat wird mit SHA512 signiert.
Das Zertifikat der Instanz ist 999 Jahre gültig.
Dass das Standard-Zertifikat so lange gültig ist, verhindert sehr effektiv, dass Sie nach einiger Zeit Verbindungsprobleme bekommen, die Sie nicht einordnen können. Gleichzeitig ist es dadurch natürlich auch möglich ein einmal kompromittiertes Zertifikat auch entsprechend lange zu missbrauchen. Wenn Sie also befürchten, dass ein Angreifer Zugriff auf die CA oder das damit signierte Instanz-Zertifikat bekommen hat, ersetzen Sie immer beide Zertifikate (CA und Instanz)!
Migrieren von älteren Versionen
Die Option LIVESTATUS_TCP_TLS wird bei einem Update von einer älteren Version als 1.6.0 aus Kompatibilitätsgründen nicht automatisch aktiviert, da danach die Verbindung nur noch verschlüsselt möglich ist.
Um nach dem Update das neue Feature in Ihren Monitoring-Instanzen zu nutzen, stoppen Sie die jeweilige Instanz und aktivieren Sie die erwähnte Option:
OMD[mysite]:~$ omd config set LIVESTATUS_TCP_TLS onDa die Zertifikate bei dem Update automatisch erzeugt wurden, wird die Instanz danach sofort die Verschlüsselung nutzen. Damit Sie also von der Zentralinstanz weiterhin auf die Remote-Instanz zugreifen können, muss gewährleistet sein, dass im Menü unter Setup > General > Distributed Monitoring bei der jeweiligen Instanz unter Encryption die Option Encrypt data using TLS ausgewählt ist. Prüfen Sie dies und stellen Sie die Option gegegenenfalls, wie im folgenden Screenshots zu sehen ist, um:
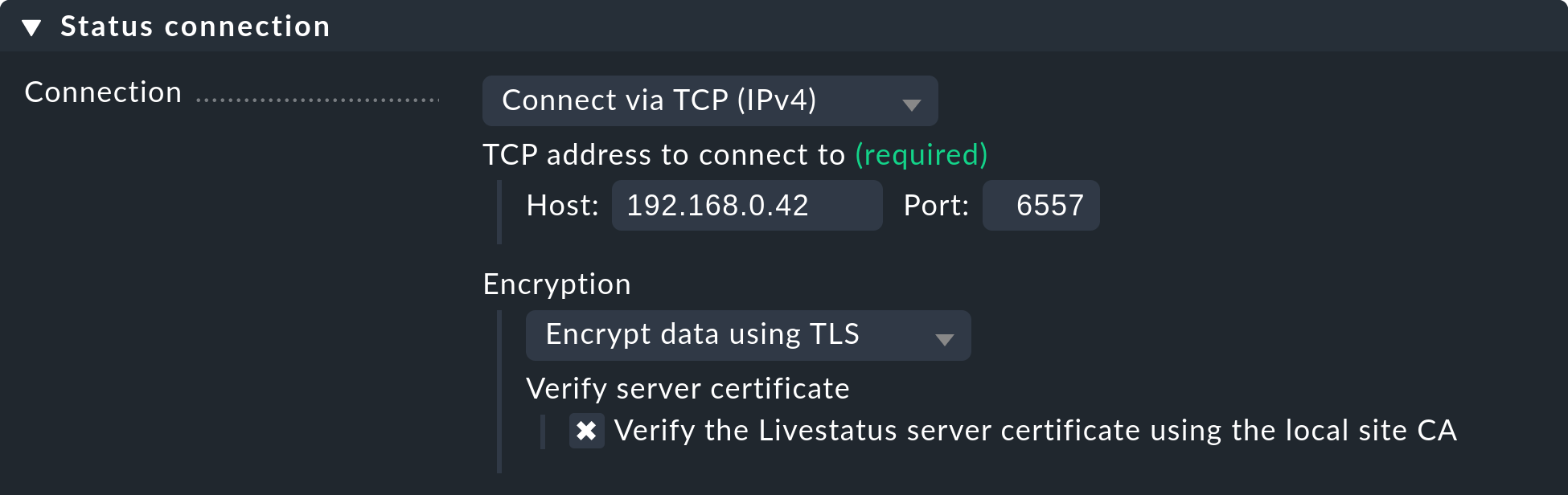
Der letzte Schritt ist wieder derselbe wie oben beschrieben: Auch hier müssen Sie zunächst die CA der Remote-Instanz als vertrauenswürdig markieren.
2.4. Besonderheiten im verteilten Setup
Ein verteiltes Monitoring via Livestatus verhält sich zwar fast wie ein einzelnes System, hat aber dennoch ein paar Besonderheiten:
Zugriff auf die überwachten Hosts
Alle Zugriffe auf einen überwachten Host geschehen konsequent von der Instanz aus, der dieser Host zugeordnet ist. Das betrifft nicht nur die eigentliche Überwachung, sondern auch die Serviceerkennung, die Diagnoseseite, die Benachrichtigungen, Alert Handler und alles andere. Das ist sehr wichtig, denn es ist überhaupt nicht gesagt, dass die Zentralinstanz auf diese Hosts Zugriff hätte.
Angabe der Instanz in den Ansichten
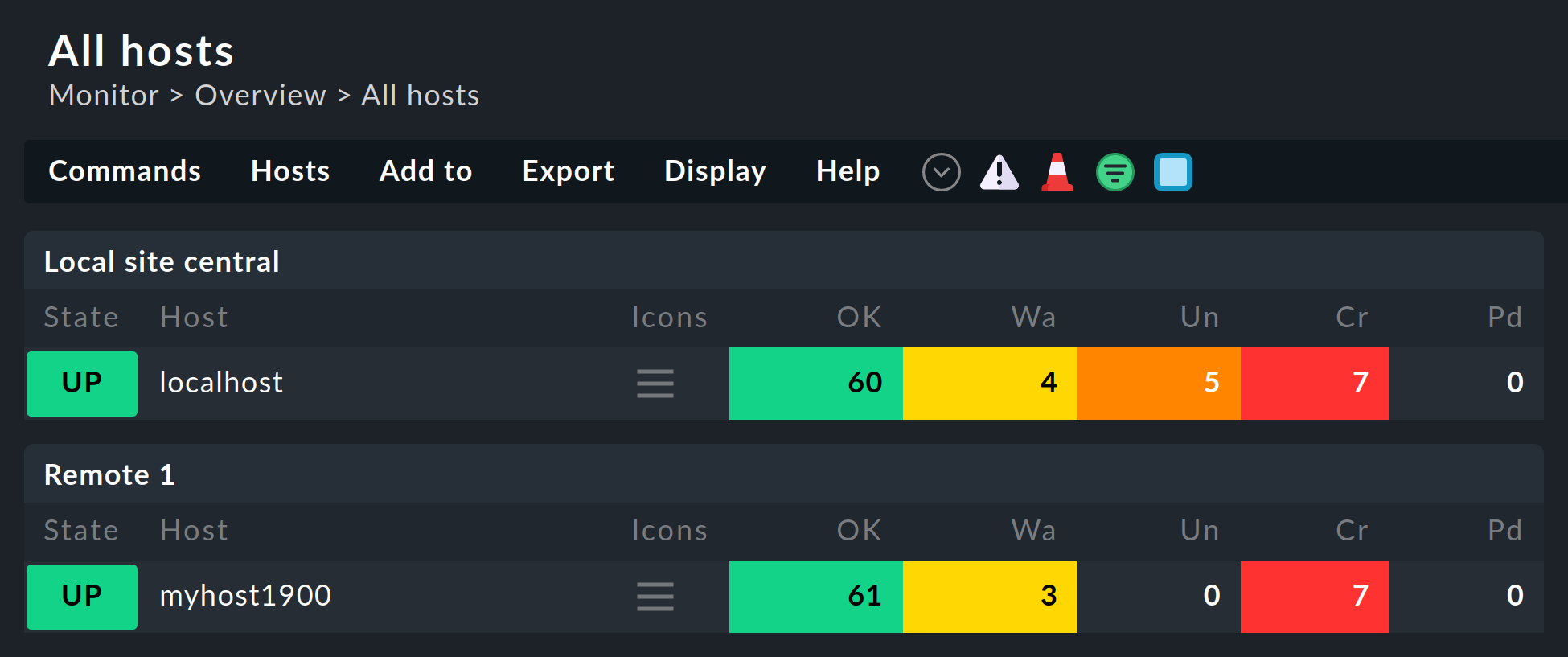
Manche der mitgelieferten Standardansichten sind gruppiert nach der Instanz, von der ein Host überwacht wird. Das gilt z.B. auch für All hosts:
Auch bei den Details eines Hosts oder Services wird die Instanz angezeigt:
Allgemein steht diese Information als Spalte beim Erzeugen von eigenen Ansichten zur Verfügung. Und es gibt einen Filter, mit dem Sie eine Ansicht nach Hosts aus einer bestimmten Instanz filtern können:
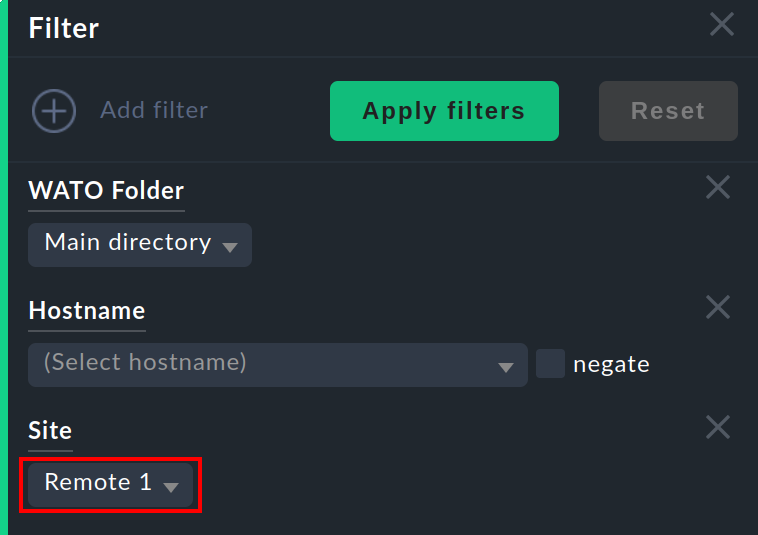
Site status Snapin
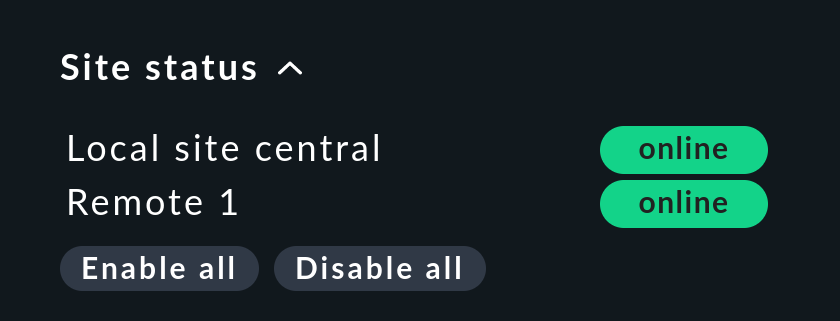
Es gibt für die Seitenleiste das Snapin Site status, welches Sie mit ![]() einbinden können.
Dieses zeigt den Status der einzelnen Instanzen. Außerdem bietet es die Möglichkeit, vorübergehend eine einzelne Instanz durch einen Klick auf den Status zu deaktivieren und wieder zu aktivieren — oder auch gleich alle Instanzen auf einmal durch Klick auf Disable all oder Enable all.
einbinden können.
Dieses zeigt den Status der einzelnen Instanzen. Außerdem bietet es die Möglichkeit, vorübergehend eine einzelne Instanz durch einen Klick auf den Status zu deaktivieren und wieder zu aktivieren — oder auch gleich alle Instanzen auf einmal durch Klick auf Disable all oder Enable all.
Deaktivierte Instanzen werden mit dem Status ![]() angezeigt.
Sie können so auch eine Instanz, die
angezeigt.
Sie können so auch eine Instanz, die ![]() ist und somit Timeouts erzeugt, deaktivieren und die Timeouts damit vermeiden.
Diese Deaktivierung entspricht nicht dem Abschalten der Livestatus-Verbindung über die Verbindungskonfiguration im Setup.
Das Abschalten hier ist lediglich für den aktuell angemeldeten Benutzer wirksam und hat eine rein optische Funktion.
Ein Klick auf den Namen einer Instanz bringt Sie zur Ansicht aller Hosts dieser Instanz.
ist und somit Timeouts erzeugt, deaktivieren und die Timeouts damit vermeiden.
Diese Deaktivierung entspricht nicht dem Abschalten der Livestatus-Verbindung über die Verbindungskonfiguration im Setup.
Das Abschalten hier ist lediglich für den aktuell angemeldeten Benutzer wirksam und hat eine rein optische Funktion.
Ein Klick auf den Namen einer Instanz bringt Sie zur Ansicht aller Hosts dieser Instanz.
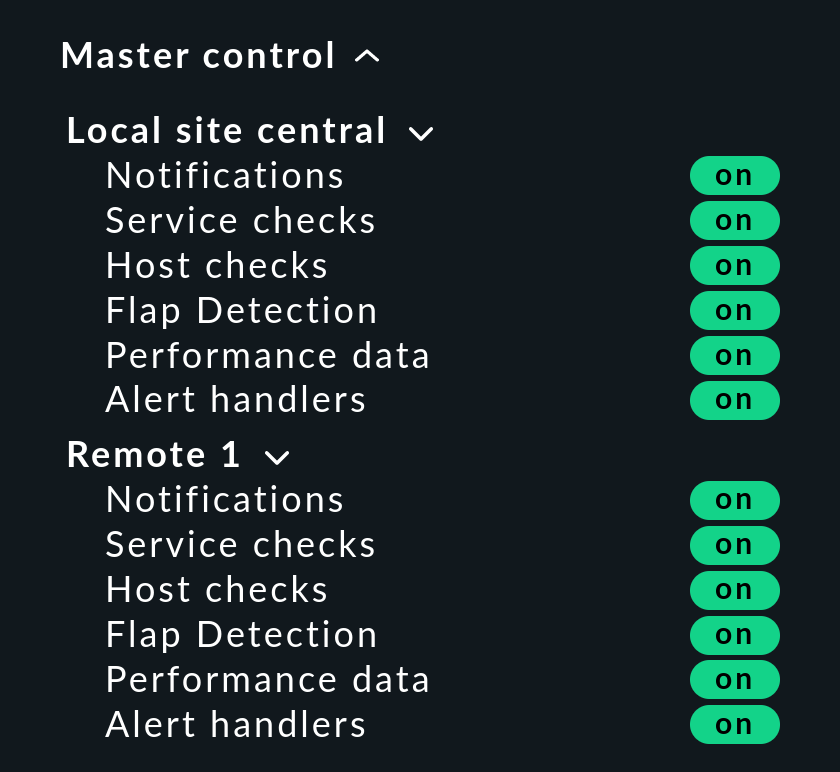
Master control Snapin
Im verteilten Monitoring ändert das Snapin Master control sein Aussehen. Die globalen Schalter gibt es immer pro Instanz:
Checkmk Cluster Hosts
Falls Sie mit Checkmk HA-Cluster überwachen, so müssen die einzelnen Nodes des Clusters alle der gleichen Instanz zugeordnet sein, wie der Cluster selbst. Dies liegt daran, dass bei der Ermittlung des Zustands der geclusterten Services auf Cache-Dateien zugegriffen wird, welche beim Überwachen der Nodes entstehen. Diese liegen lokal auf der jeweiligen Instanz.
Huckepackdaten (z.B. ESXi)
Manche Check-Plugins verwenden „Huckepackdaten“ (Piggyback), um z.B. Überwachungsdaten, die von einem ESXi-Host geholt wurden, den einzelnen virtuellen Maschinen zuzuordnen. Aus den gleichen Gründen wie beim Clustermonitoring müssen im verteilten Monitoring sowohl der Piggyhost als auch die davon abhängigen Hosts von der gleichen Instanz aus überwacht werden. Im Falle von ESXi bedeutet das, dass Sie die virtuellen Maschinen in Checkmk immer der gleichen Instanz zuordnen müssen, wie das ESXi-System, von dem Sie die Überwachungsdaten holen. Das kann dann dazu führen, dass Sie anstelle eines globalen vCenters besser die ESXi-Hostsysteme direkt abfragen. Details dazu finden Sie in der Dokumentation zur ESXi-Überwachung.
Hardware-/Softwareinventur
Die Checkmk-Inventurisierung funktioniert auch in verteilten
Umgebungen. Dabei müssen die Inventurdaten regelmäßig aus dem Verzeichnis
var/check_mk/inventory von den Remote-Instanzen zur Zentralinstanz übertragen werden.
Die Benutzeroberfläche greift aus Performancegründen immer lokal auf dieses
Verzeichnis zu.
In den ![]() Checkmk Enterprise Editions geschieht die Synchronisation automatisch auf allen Instanz, bei
denen Sie den Livestatus-Proxy zur Verbindung einsetzen.
Checkmk Enterprise Editions geschieht die Synchronisation automatisch auf allen Instanz, bei
denen Sie den Livestatus-Proxy zur Verbindung einsetzen.
Falls Sie mit der ![]() Checkmk Raw Edition in einem verteilten System Inventarisierung verwenden,
müssen Sie das Verzeichnis mit eigenen Mitteln regelmäßig zur Zentralinstanz
spiegeln (z.B. mit
Checkmk Raw Edition in einem verteilten System Inventarisierung verwenden,
müssen Sie das Verzeichnis mit eigenen Mitteln regelmäßig zur Zentralinstanz
spiegeln (z.B. mit rsync).
Passwortänderung
Auch wenn alle Instanzen zentral administriert werden, ist eine Anmeldung auf der Oberfläche der einzelnen Instanzen durchaus möglich und oft auch sinnvoll. Deswegen sorgt Checkmk dafür, dass das Passwort eines Benutzers auf allen Instanz immer gleich ist.
Bei einer Änderung durch den Administrator ist das automatisch gegeben, sobald sie per Activate pending changes auf alle Instanzen verteilt wird.
Etwas Anderes ist eine Änderung durch den Benutzer selbst in seinen
![]() persönlichen Einstellungen. Diese darf
natürlich nicht zu einem Activate pending changes führen, denn der Benutzer
hat dazu im Allgemeinen keine Berechtigung. Daher verteilt Checkmk in so einem
Fall das geänderte Passwort automatisch auf alle Instanzen — und zwar direkt
nach dem Speichern.
persönlichen Einstellungen. Diese darf
natürlich nicht zu einem Activate pending changes führen, denn der Benutzer
hat dazu im Allgemeinen keine Berechtigung. Daher verteilt Checkmk in so einem
Fall das geänderte Passwort automatisch auf alle Instanzen — und zwar direkt
nach dem Speichern.
Nun sind aber, wie wir alle wissen, Netzwerke nie zu 100 % verfügbar. Ist eine Instanz zu diesem Zeitpunkt also nicht erreichbar, kann das Passwort auf diese nicht übertragen werden. Bis zum nächsten erfolgreichen Activate pending changes durch einen Administrator bzw. der nächsten erfolgreichen Passwortänderung hat diese Instanz also noch das alte Passwort für den Benutzer. Der Benutzer wird über den Status der Passwortübertragung auf die einzelnen Instanzen durch ein Statussymbol informiert.
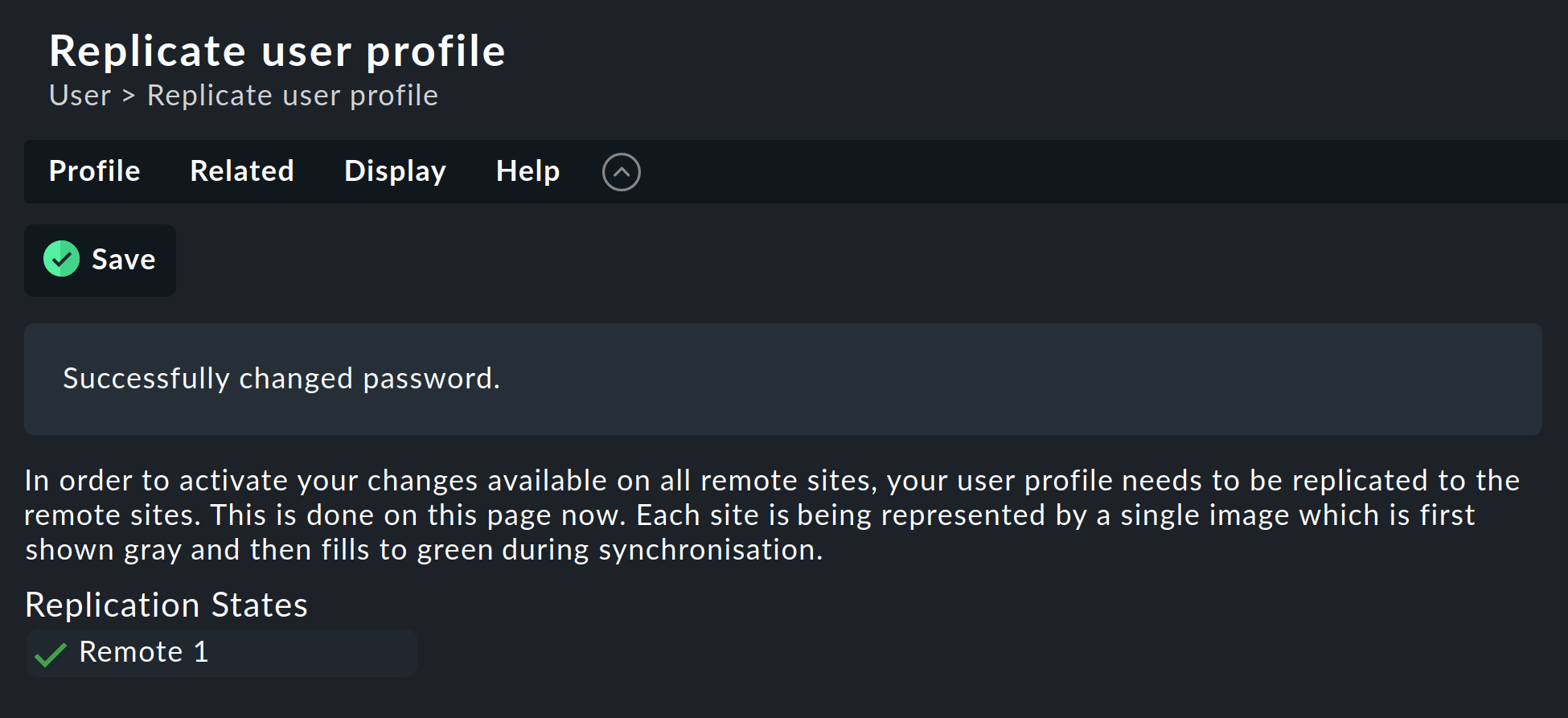
2.5. Anbinden von bestehenden Instanzen
Wie bereits oben erwähnt, können Sie auch bestehende Instanzen nachträglich an ein verteiltes Monitoring anbinden. Sofern die oben beschriebenen Voraussetzungen erfüllt sind (passende Checkmk-Version), geschieht dies genau wie beim Einrichten einer neuen Remote-Instanz. Geben Sie Livestatus per TCP frei, tragen Sie die Instanz unter Setup > General > Distributed monitoring ein — fertig!
Der zweite Schritt, also die Umstellung auf eine zentrale Konfiguration, ist etwas kniffliger. Bevor Sie wie oben beschrieben die Instanz in die verteilte Konfigurationsumgebung einbinden, sollten Sie wissen, dass dabei die komplette lokale Konfiguration der Instanz überschrieben wird!
Wenn Sie also bestehende Hosts und eventuell auch Regeln übernehmen möchten, benötigen Sie drei Schritte:
Schema der Host-Merkmale anpassen
(Host-)Verzeichnisse kopieren
Eigenschaften im Elternordner einmal editieren
1. Host-Merkmale
Es versteht sich von selbst, dass die in der Remote-Instanz verwendeten Host-Merkmale (host tags) auch in der Zentralinstanz bekannt sein müssen, damit diese übernommen werden können. Kontrollieren Sie dies vor dem Umziehen und legen Sie fehlende Tags in der Zentrale von Hand an. Wichtig ist dabei, dass die Tag-ID übereinstimmt — der Titel der Tags spielt keine Rolle.
2. Ordner
Als Zweites ziehen die Hosts und Regeln in die Konfigurationsumgebung auf der Zentralinstanz um. Das funktioniert nur für Hosts und Regeln, die in Unterordnern liegen (also nicht im Ordner Main). Hosts im Hauptordner sollten Sie auf der Remote-Instanz einfach vorher im Menü Setup > Hosts > Hosts in einen Unterordner verschieben.
Das eigentliche Umziehen geht dann recht einfach durch Kopieren der entsprechenden Verzeichnisse.
Jeder Ordner in Checkmk entspricht einem Verzeichnis unterhalb von ~/etc/check_mk/conf.d/wato/.
Dieses können Sie mit einem Werkzeug Ihrer Wahl (z.B. scp) von der angebundenen Instanz an die gleiche Stelle in die Zentralinstanz kopieren.
Falls es dort bereits ein gleichnamiges Verzeichnis gibt, benennen Sie es einfach um.
Bitte achten Sie darauf, dass Linux-Benutzer und -Gruppe von der Zentrale verwendet werden.
Nach dem Kopieren sollten die Hosts in der Konfigurationsumgebung auf der Zentralinstanz auftauchen — und ebenso Regeln, die Sie in diesen Ordnern angelegt haben.
Auch die Eigenschaften der Ordner wurden mit kopiert.
Diese befinden sich im Verzeichnis in der versteckten Datei .wato.
3. Einmal editieren und speichern
Damit die Vererbung von Attributen von Elternordnern der Zentralinstanz korrekt funktioniert, müssen Sie als letzten Schritt nach dem Umziehen einmal die Eigenschaften des Elternordners öffnen und speichern. Damit werden alle Host-Attribute neu berechnet.
2.6. Instanzspezifische globale Einstellungen
Zentrale Konfiguration bedeutet zunächst einmal, dass alle Instanzen eine gemeinsame und (bis auf die Hosts) gleiche Konfiguration haben. Was ist aber, wenn Sie für einzelne Instanzen abweichende globale Einstellungen benötigen? Ein Beispiel könnte z.B. die Einstellung Maximum concurrent Checkmk checks des CMC sein. Vielleicht benötigen Sie für eine besonders kleine oder große Instanz eine angepasste Einstellung.
Für solche Fälle gibt es instanzspezifische globale Einstellungen.
Zu diesen gelangen Sie über das Symbol ![]() im Menü Setup > General > Distributed monitoring:
im Menü Setup > General > Distributed monitoring:

Damit gelangen Sie zur Auswahl aller globalen Einstellungen — allerdings gilt alles, was Sie jetzt einstellen, nur für die ausgewählte Instanz. Die optische Hinterlegung für eine Abweichung vom Standard bezieht sich jetzt nur auf diese Instanz:

2.7. Verteilte Event Console
Die Event Console verarbeitet Syslog-Meldungen, SNMP Traps und andere Arten von Ereignissen asynchroner Natur.
Checkmk bietet die Möglichkeit, die Event Console ebenfalls verteilt laufen zu lassen.
Auf jeder Instanz läuft dann eine eigene Eventverarbeitung, welche die Ereignisse von allen Hosts erfasst, die von dieser Instanz aus überwacht werden.
Die Events werden dann aber nicht alle zum Zentralsystem geschickt, sondern verbleiben auf den Instanzen und werden nur zentral abgefragt.
Dies geschieht analog zu den aktiven Zuständen über Livestatus und funktioniert sowohl mit der ![]() Checkmk Raw Edition als auch mit den
Checkmk Raw Edition als auch mit den ![]() Checkmk Enterprise Editions.
Checkmk Enterprise Editions.
Eine Umstellung auf eine verteilte Event Console nach dem neuen Schema erfordert folgende Schritte:
In den Verbindungseinstellungen die Replikation EC-Konfiguration einschalten (Replicate Event Console configuration to this site).
Syslogziele und SNMP-Trap-Destinations der betroffenen Hosts auf der Remote-Instanz umstellen. Das ist der aufwendigste Teil.
Falls Sie den Regelsatz Check event state in Event Console verwenden, diesen wieder auf Connect to the local Event Console umstellen.
Falls Sie den Regelsatz Logwatch Event Console Forwarding verwenden, diesen ebenfalls auf lokale Event Console umstellen.
In den Settings der Event Console den Access to event status via TCP wieder auf no access via TCP zurückschalten.
2.8. NagVis

Das Open-Source-Programm NagVis visualisiert Statusdaten aus dem Monitoring auf selbsterstellten Landkarten, Diagrammen und anderen Skizzen. NagVis ist in Checkmk integriert und kann sofort genutzt werden. Am einfachsten geht der Zugriff über das Seitenleistenelement NagVis Maps. Die Integration von NagVis in Checkmk beschreibt ein eigener Artikel.
NagVis unterstützt ein verteiltes Monitoring via Livestatus in ziemlich genau der gleichen Weise, wie es auch Checkmk macht. Die Anbindungen der einzelnen Instanzen nennt man Backends (Deutsch: Datenquellen). Die Backends werden von Checkmk automatisch korrekt angelegt, so dass Sie sofort damit loslegen können, NagVis-Karten zu erstellen — auch im verteilten Monitoring.
Wählen Sie bei jedem Objekt, das Sie auf einer Karte platzieren, das richtige Backend aus — also die Checkmk-Instanz, von der aus das Objekt überwacht wird. NagVis kann den Host oder Service nicht automatisch finden, vor allem aus Gründen der Performance. Wenn Sie also Hosts zu einer anderen Remote-Instanz verschieben, müssen Sie danach Ihre NagVis-Karten entsprechend anpassen.
Einzelheiten zu den Backends finden Sie in der Dokumentation von NagVis.
3. Instabile oder langsame Verbindungen
Die gemeinsame Statusansicht in der Benutzeroberfläche erfordert einen ständig verfügbaren und zuverlässigen Zugriff auf alle angebundenen Instanzen. Eine Schwierigkeit dabei ist, dass eine Ansicht immer erst dann dargestellt werden kann, wenn alle Instanzen geantwortet haben. Der Ablauf ist immer so, dass an alle Instanzen eine Livestatus-Anfrage gesendet wird (z.B. „Gib mir alle Services, deren Zustand nicht OK ist."). Erst wenn die letzte Instanz geantwortet hat, kann die Ansicht dargestellt werden.
Ärgerlich wird es, wenn eine Instanz gar nicht antwortet.
Um kurze Ausfälle zu tolerieren (z.B. durch einen Neustart einer Instanz oder verlorengegangene
TCP-Pakete), wartet die GUI einen gewissen Timeout ab, bevor eine Instanz als ![]() deklariert wird und mit den Antworten der übrigen Instanzen fortgefahren wird.
Das führt dann zu einer „hängenden“ GUI.
Der Timeout ist per Default auf 10 Sekunden eingestellt.
deklariert wird und mit den Antworten der übrigen Instanzen fortgefahren wird.
Das führt dann zu einer „hängenden“ GUI.
Der Timeout ist per Default auf 10 Sekunden eingestellt.
Wenn das in Ihrem Netzwerk gelegentlich passiert, sollten Sie entweder Statushosts oder (besser) den Livestatus-Proxy einrichten.
3.1. Statushosts
![]() Die Konfiguration von Statushosts ist der bei der
Die Konfiguration von Statushosts ist der bei der ![]() Checkmk Raw Edition empfohlene Weg, defekte Verbindungen zuverlässig zu erkennen.
Die Idee dazu ist einfach: Die Zentrale überwacht aktiv die Verbindung zu jeder einzelnen entfernten Instanz.
Immerhin haben wir ein Monitoring-System zur Verfügung!
Die GUI kennt dann nicht erreichbare Instanzen und kann diese sofort ausklammern und als
Checkmk Raw Edition empfohlene Weg, defekte Verbindungen zuverlässig zu erkennen.
Die Idee dazu ist einfach: Die Zentrale überwacht aktiv die Verbindung zu jeder einzelnen entfernten Instanz.
Immerhin haben wir ein Monitoring-System zur Verfügung!
Die GUI kennt dann nicht erreichbare Instanzen und kann diese sofort ausklammern und als ![]() werten.
Timeouts werden so vermieden.
werten.
Timeouts werden so vermieden.
So richten Sie für eine Verbindung einen Statushost ein:
Nehmen Sie den Host, auf dem die Remote-Instanz läuft, auf der Zentralinstanz ins Monitoring auf.
Tragen Sie diesen bei der Verbindung zur Remote-Instanz als Statushost ein:
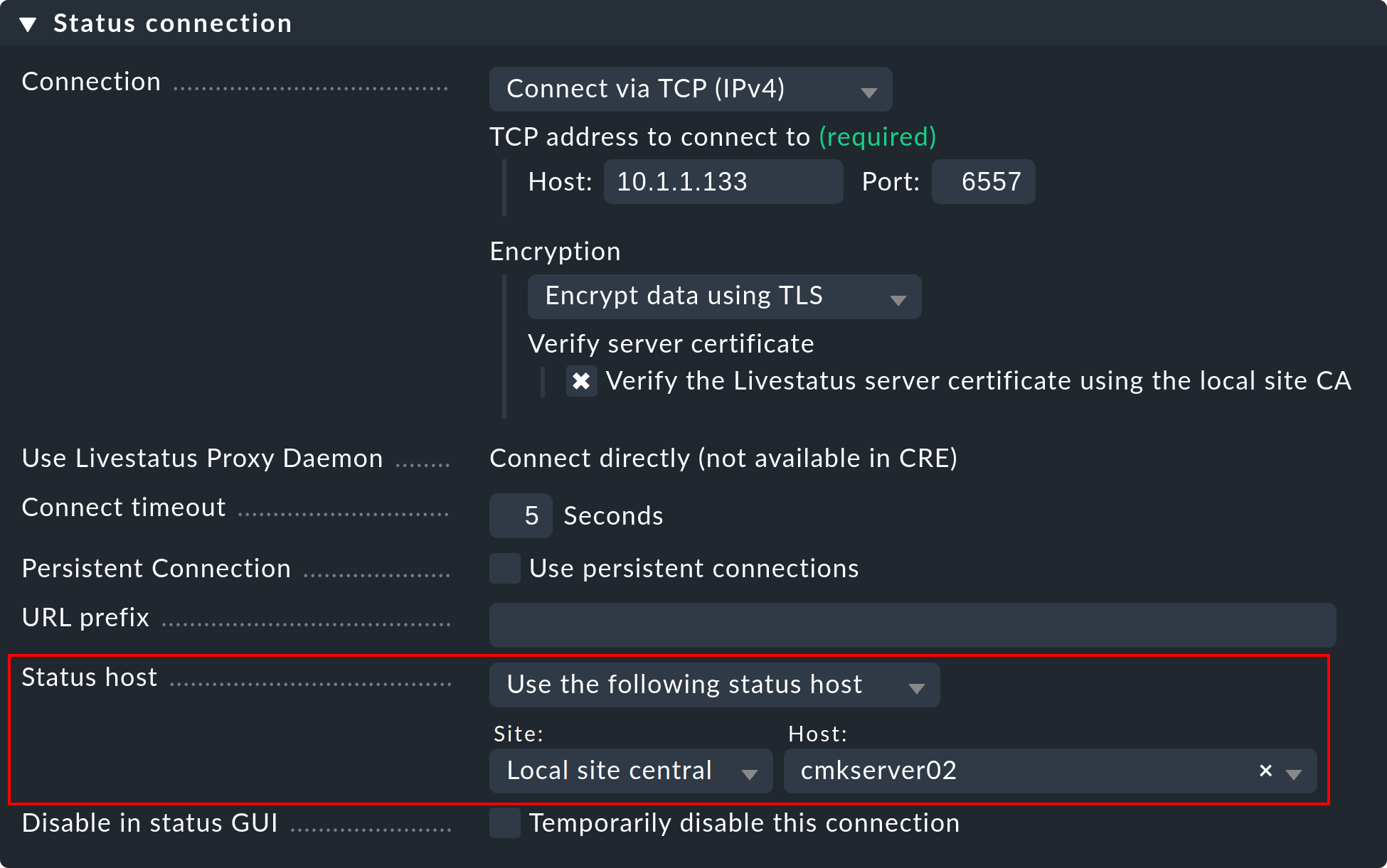
Eine ausgefallene Verbindung zur Remote-Instanz kann jetzt nur noch für kurze Zeit zu einem Hängen der GUI führen — nämlich solange, bis das Monitoring das erkannt hat. Durch ein Reduzieren des Prüfintervalls des Statushosts vom Default von 60 Sekunden auf z.B. 5 Sekunden können Sie dies minimieren.
Falls Sie einen Statushost eingerichtet haben, gibt es weitere mögliche Zustände für Verbindungen:
|
Der Rechner, auf dem die Remote-Instanz läuft, ist für das Monitoring gerade nicht erreichbar, weil ein Router dazwischen down ist (Statushost hat den Zustand UNREACH). |
|
Der Statushost, der die Verbindung zur Remote-Instanz überwacht, wurde noch nicht vom Monitoring geprüft (steht noch auf PEND). |
|
Der Zustand des Statushosts hat einen ungültigen Wert (sollte nie auftreten). |
In allen drei Fällen wird die Verbindung zu der Instanz ausgeklammert, wodurch Timeouts vermieden werden.
3.2. Persistente Verbindungen
![]() Mit der Checkbox Use persistent connections können Sie die GUI
dazu veranlassen, einmal aufgebaute Livestatus-Verbindungen zu Remote-Instanzen
permanent aufrecht zu erhalten und für weitere Anfragen wieder zu verwenden.
Gerade bei Verbindungen mit einer längeren Paketlaufzeit (z.B. interkontinentale)
kann das die GUI deutlich reaktiver machen.
Mit der Checkbox Use persistent connections können Sie die GUI
dazu veranlassen, einmal aufgebaute Livestatus-Verbindungen zu Remote-Instanzen
permanent aufrecht zu erhalten und für weitere Anfragen wieder zu verwenden.
Gerade bei Verbindungen mit einer längeren Paketlaufzeit (z.B. interkontinentale)
kann das die GUI deutlich reaktiver machen.
Da die GUI von Apache auf mehrere unabhängige Prozesse aufgeteilt wird, ist pro gleichzeitig laufendem Apache-Clientprozess eine Verbindung notwendig.
Fall Sie viele gleichzeitige Benutzer haben, sorgen Sie bitte bei der Konfiguration des Nagios-Kerns der Remote-Instanz für eine ausreichende Anzahl von Livestatus-Verbindungen.
Diese werden in der Datei etc/mk-livestatus/nagios.cfg konfiguriert.
Der Default ist 20 (num_client_threads=20).
Per Default ist Apache in Checkmk so konfiguriert, dass er bis zu 128
gleichzeitige Benutzerverbindungen zulässt. Dies wird in der Datei
etc/apache/apache.conf in folgendem Abschnitt konfiguriert:
<IfModule prefork.c>
StartServers 1
MinSpareServers 1
MaxSpareServers 5
ServerLimit 128
MaxClients 128
MaxRequestsPerChild 4000
</IfModule>Das bedeutet, dass unter hoher Last bis zu 128 Apache-Prozesse entstehen
können, welche dann auch bis zu 128 Livestatus-Verbindungen erzeugen und
halten können. Sind die num_client_threads nicht entsprechend hoch
eingestellt, kommt es zu Fehlern oder sehr langsamen Antwortzeiten in der GUI.
Bei Verbindungen im LAN oder in schnellen WAN-Netzen empfehlen wir, die persistenten Verbindungen nicht zu verwenden.
3.3. Der Livestatus-Proxy
![]() Die
Die ![]() Checkmk Enterprise Editions verfügen mit dem Livestatus-Proxy über einen
ausgeklügelten Mechanismus, um tote Verbindungen zu erkennen. Außerdem
optimiert er die Performance vor allem bei Verbindungen mit hohen
Round-Trip-Zeiten. Vorteile des Livestatus-Proxys sind:
Checkmk Enterprise Editions verfügen mit dem Livestatus-Proxy über einen
ausgeklügelten Mechanismus, um tote Verbindungen zu erkennen. Außerdem
optimiert er die Performance vor allem bei Verbindungen mit hohen
Round-Trip-Zeiten. Vorteile des Livestatus-Proxys sind:
Sehr schnelle proaktive Erkennung von nicht antwortenden Instanzen
Lokales Zwischenspeichern von Anfragen, die statische Daten liefern
Stehende TCP-Verbindungen, dadurch weniger Roundtrips notwendig und somit viel schnellere Antworten von weit entfernten Instanzen (z.B. USA ⇄ China)
Genaue Kontrolle der maximal nötigen Livestatus-Verbindungen
Ermöglicht Hardware/Softwareinventur in verteilten Umgebungen
Aufsetzen
Das Aufsetzen des Livestatus-Proxys ist sehr einfach. In der CEE ist dieser per Default aktiviert, wie Sie beim Starten einer Instanz sehen können:
OMD[central]:~$ omd start
Temporary filesystem already mounted
Starting mkeventd...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
Starting stunnel...OK
Starting xinetd...OK
Initializing Crontab...OKWählen Sie nun bei den Verbindungen zu der Remote-Instanz anstelle von „Connect via TCP“ die Einstellung „Use Livestatus Proxy-Daemon“:
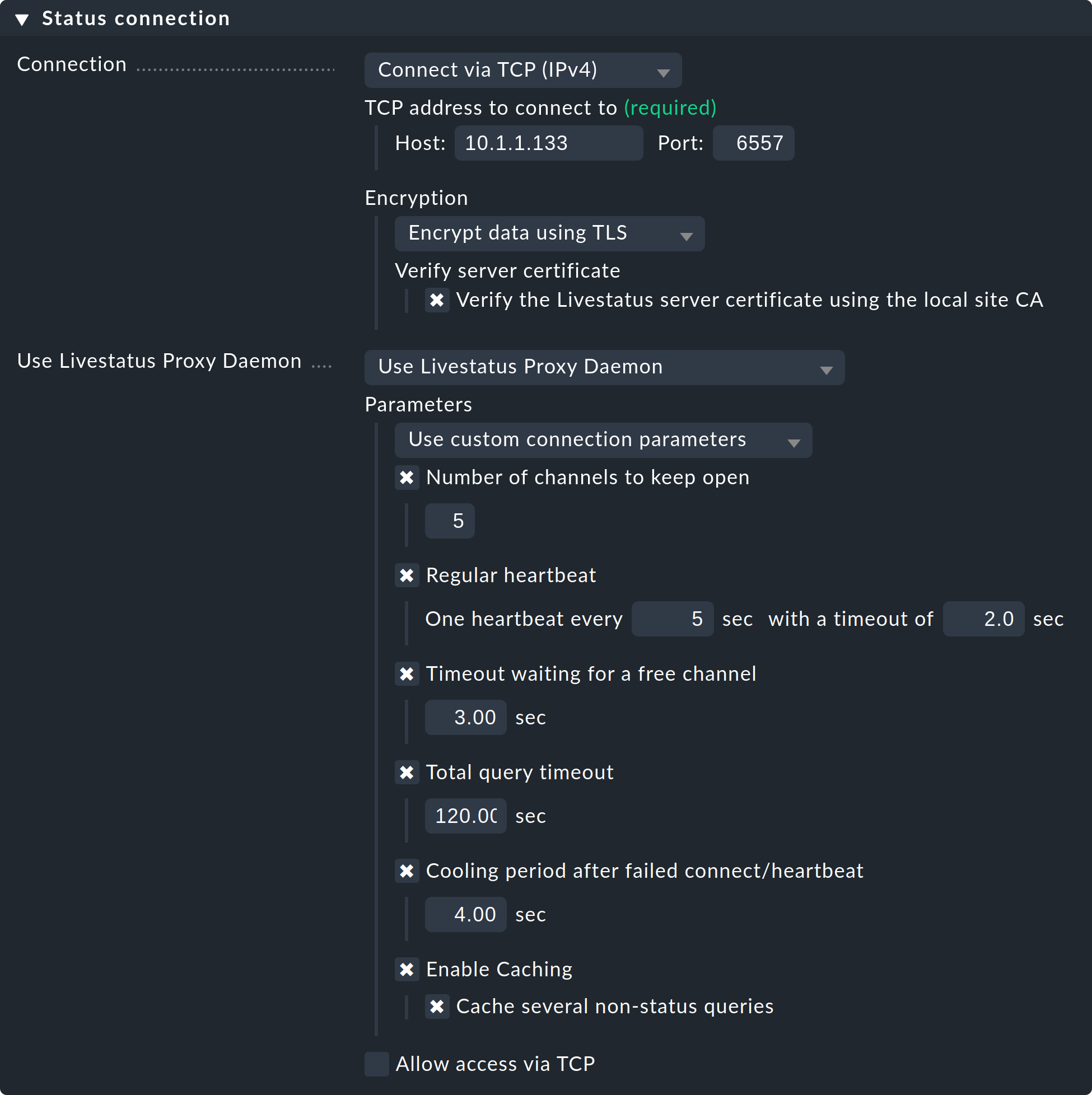
Die Angaben zu Host und Port sind wie gehabt. Auf den Remote-Instanzen müssen Sie nichts ändern. Bei Number of channels to keep open geben Sie die Anzahl der parallelen TCP-Verbindungen an, die der Proxy zur Zielseite aufbauen und aufrechterhalten soll.
Der TCP-Verbindungspool wird von allen Anfragen der GUI gemeinsam genutzt. Die Anzahl der Verbindungen begrenzt die maximale Anzahl von gleichzeitig in Bearbeitung befindlichen Anfragen. Dies beschränkt indirekt die Anzahl der Benutzer. In Situationen, in denen alle Kanäle belegt sind, kommt es nicht sofort zu einem Fehler. Die GUI wartet eine gewisse Zeit auf einen freien Kanal. Die meisten Anfragen benötigen nämlich nur wenige Millisekunden.
Falls die GUI länger als Timeout waiting for a free channel auf so einen Kanal warten muss, wird mit einem Fehler abgebrochen und der Benutzer sieht eine Fehlermeldung. In so einem Fall sollten Sie die Anzahl der Verbindungen erhöhen. Beachten Sie dabei jedoch, dass auf der Gegenstelle (der Remote-Instanz) genügend gleichzeitige eingehende Verbindungen erlaubt sein müssen. Per Default ist das auf 20 eingestellt. Sie finden diese Einstellung in den globalen Optionen unter Monitoring core > Maximum concurrent Livestatus connections.
Der Regular heartbeat sorgt für eine ständige aktive Überwachung der Verbindungen direkt auf Protokollebene. Dabei sendet der Proxy regelmäßig eine einfache Livestatus-Anfrage, welche von der Remote-Instanz in der eingestellten Zeit (Default: 2 Sekunden) beantwortet sein muss. So werden auch Situationen erkannt, wo der Zielserver und der TCP-Port zwar erreichbar sind, aber der Monitoring-Kern nicht mehr antwortet.
Bleibt die Antwort aus, so werden alle Verbindungen als tot deklariert und nach einer Cooldownzeit (Default: 4 Sekunden) wieder neu aufgebaut. Das Ganze geschieht proaktiv — also ohne, dass ein Benutzer eine GUI-Seite abrufen muss. So werden Ausfälle schnell erkannt und bei einer Wiedergenesung die Verbindungen sofort wieder aufgebaut und stehen dann im besten Fall schon wieder zur Verfügung, bevor ein Benutzer den Ausfall mitbekommt.
Das Caching sorgt dafür, dass statische Anfragen nur einmal von der Remote-Instanz beantwortet werden müssen und ab dem Zeitpunkt direkt lokal ohne Verzögerung beantwortet werden können. Ein Beispiel dafür ist die Liste der überwachten Hosts, welche von Quicksearch gebraucht wird.
Fehlerdiagnose
Der Livestatus-Proxy hat eine eigene Logdatei, die Sie unter var/log/liveproxyd.log
finden. Bei einer korrekt eingerichteten Remote-Instanz mit fünf Kanälen (Standard), sieht das etwa so aus:
2021-12-01 15:58:30,624 [20] ----------------------------------------------------------
2021-12-01 15:58:30,627 [20] [cmk.liveproxyd] Livestatus Proxy-Daemon (2.0.0p15) starting...
2021-12-01 15:58:30,638 [20] [cmk.liveproxyd] Configured 1 sites
2021-12-01 15:58:36,690 [20] [cmk.liveproxyd.(3236831).Manager] Reload initiated. Checking if configuration changed.
2021-12-01 15:58:36,692 [20] [cmk.liveproxyd.(3236831).Manager] No configuration changes found, continuing.
2021-12-01 16:00:16,989 [20] [cmk.liveproxyd.(3236831).Manager] Reload initiated. Checking if configuration changed.
2021-12-01 16:00:16,993 [20] [cmk.liveproxyd.(3236831).Manager] Found configuration changes, triggering restart.
2021-12-01 16:00:17,000 [20] [cmk.liveproxyd.(3236831).Manager] Restart initiated. Terminating site processes...
2021-12-01 16:00:17,028 [20] [cmk.liveproxyd.(3236831).Manager] Restart master processIn die Datei var/log/liveproxyd.state schreibt der Livestatus-Proxy regelmäßig seinen
Status:
Current state:
[remote1]
State: ready
State dump time: 2021-12-01 15:01:15 (0:00:00)
Last reset: 2021-12-01 14:58:49 (0:02:25)
Site's last reload: 2021-12-01 14:26:00 (0:35:15)
Last failed connect: Never
Last failed error: None
Cached responses: 1
Channels:
9 - ready - client: none - since: 2021-12-01 15:01:00 (0:00:14)
10 - ready - client: none - since: 2021-12-01 15:01:10 (0:00:04)
11 - ready - client: none - since: 2021-12-01 15:00:55 (0:00:19)
12 - ready - client: none - since: 2021-12-01 15:01:05 (0:00:09)
13 - ready - client: none - since: 2021-12-01 15:00:50 (0:00:24)
Clients:
Heartbeat:
heartbeats received: 29
next in 0.2s
Inventory:
State: not running
Last update: 2021-12-01 14:58:50 (0:02:25)Und so sieht der Status aus, wenn eine Instanz gerade gestoppt ist:
----------------------------------------------
Current state:
[remote1]
State: starting
State dump time: 2021-12-01 16:11:35 (0:00:00)
Last reset: 2021-12-01 16:11:29 (0:00:06)
Site's last reload: 2021-12-01 16:11:29 (0:00:06)
Last failed connect: 2021-12-01 16:11:33 (0:00:01)
Last failed error: [Errno 111] Connection refused
Cached responses: 0
Channels:
Clients:
Heartbeat:
heartbeats received: 0
next in -1.0s
Inventory:
State: not running
Last update: 2021-12-01 16:00:45 (0:10:50)Der Zustand ist hier starting.
Der Proxy ist also gerade beim Versuch, Verbindungen aufzubauen.
Channels gibt es noch keine.
Während dieses Zustands werden Anfragen an die Instanz sofort mit einem Fehler beantwortet.
4. Cascading Livestatus
Wie in der Einleitung bereits erwähnt, ist es möglich, das verteilte Monitoring um reine Checkmk-Viewer-Instanzen zu erweitern, die die Monitoring-Daten von Remote-Instanzen anzeigen, die selbst nicht direkt erreichbar sind. Einzige Voraussetzung dafür: Die Zentralinstanz muss natürlich erreichbar sein. Technisch wird dies über den Livestatus-Proxy umgesetzt: Die Zentralinstanz bekommt via Livestatus Daten von der Remote-Instanz und fungiert selbst als Proxy — kann die Daten also an dritte Instanzen durchreichen. Diese Kette können Sie beliebig erweitern, also zum Beispiel eine zweite Viewer-Instanz an die erste anbinden.
Praktisch ist dies beispielsweise für ein Szenario wie folgendes: Die Zentralinstanz kümmert sich um drei unabhängige Netze kunde1, kunde2 und kunde3 und wird selbst im Netz betreiber1 betrieben. Möchte nun etwa das Management des Betreibers aus dem Netz betreiber1 den Monitoring-Status der Kundeninstanzen sehen, könnte dies natürlich über einen Zugang auf der Zentralinstanz selbst geregelt werden. Aus technischen wie rechtlichen Gründen könnte die Zentralinstanz jedoch ausschließlich den zuständigen Mitarbeitern vorbehalten sein. Über eine rein zur Ansicht von entfernten Instanzen aufgesetzte Viewer-Instanz lässt sich der direkte Zugriff umgehen. Die Viewer-Instanz zeigt dann zwar Hosts und Services verbundener Instanzen, die eigene Konfiguration bleibt jedoch komplett leer.
Das Aufsetzen erfolgt in den Verbindungseinstellungen des verteilten Monitorings, zunächst auf der Zentralinstanz, dann auf der Viewer-Instanz (welche noch nicht existieren muss).
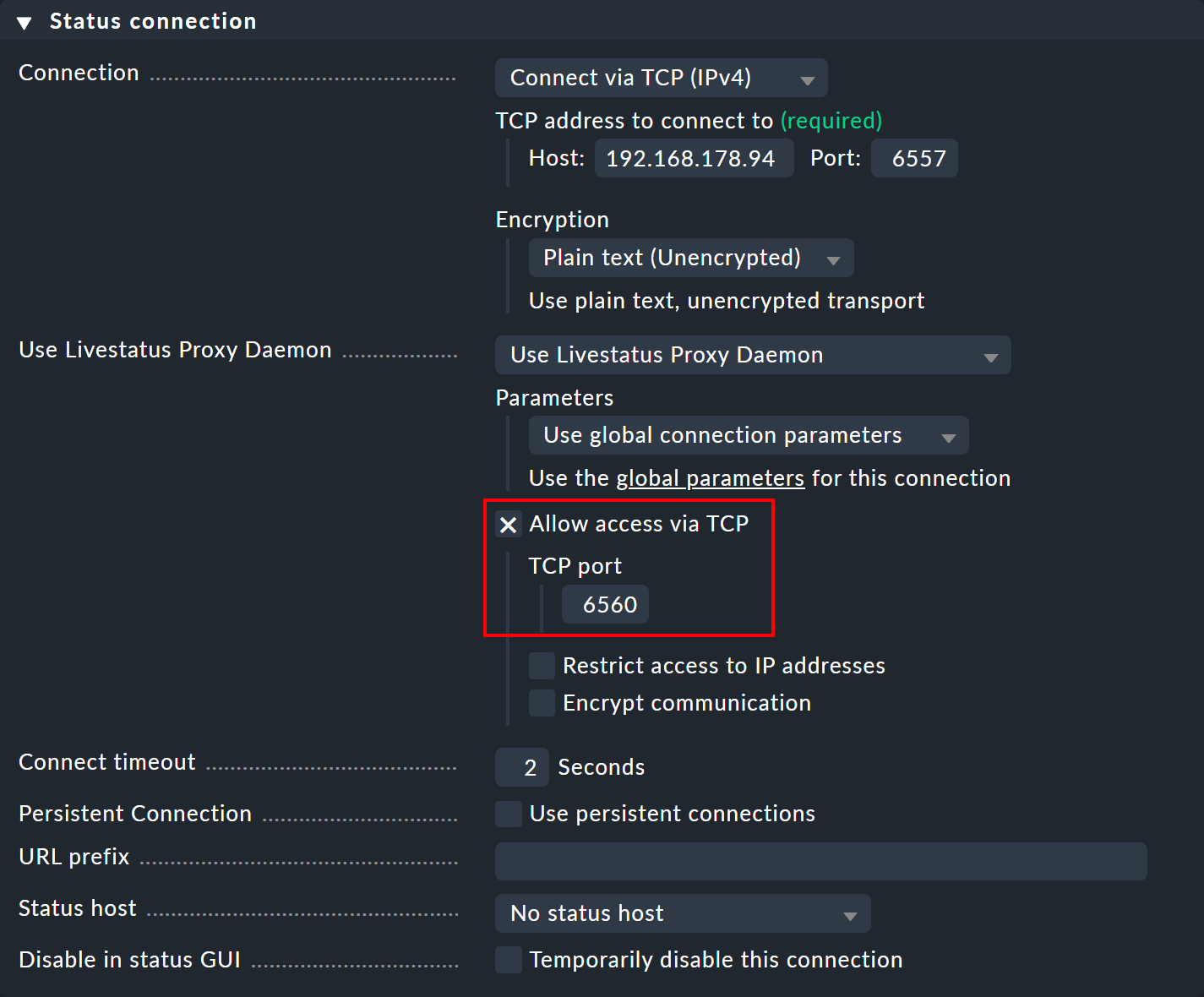
Öffnen Sie auf der Zentralinstanz die Verbindungseinstellungen der gewünschten Remote-Instanz über Setup > General > Distributed monitoring.
Unter Use Livestatus Proxy Daemon aktivieren Sie die Option Allow access via TCP und geben einen freien Port an (hier 6560).
So verbindet sich der Livestatus-Proxy der Zentralinstanz mit der Remote-Instanz und öffnet einen Port für Anfragen der Viewer-Instanz — welche dann an die Remote-Instanz weitergeleitet werden.
Erstellen Sie nun eine Viewer-Instanz und öffnen Sie auch dort wieder die Verbindungseinstellungen über Setup > General > Distributed monitoring. In den Basic settings geben Sie — wie immer bei Verbindungen im verteilten Monitoring — als Site ID den exakten Namen der Zentralinstanz an.

Im Bereich Status connection geben Sie als Host die Zentralinstanz an — sowie den manuell vergebenen freien Port (hier 6560).
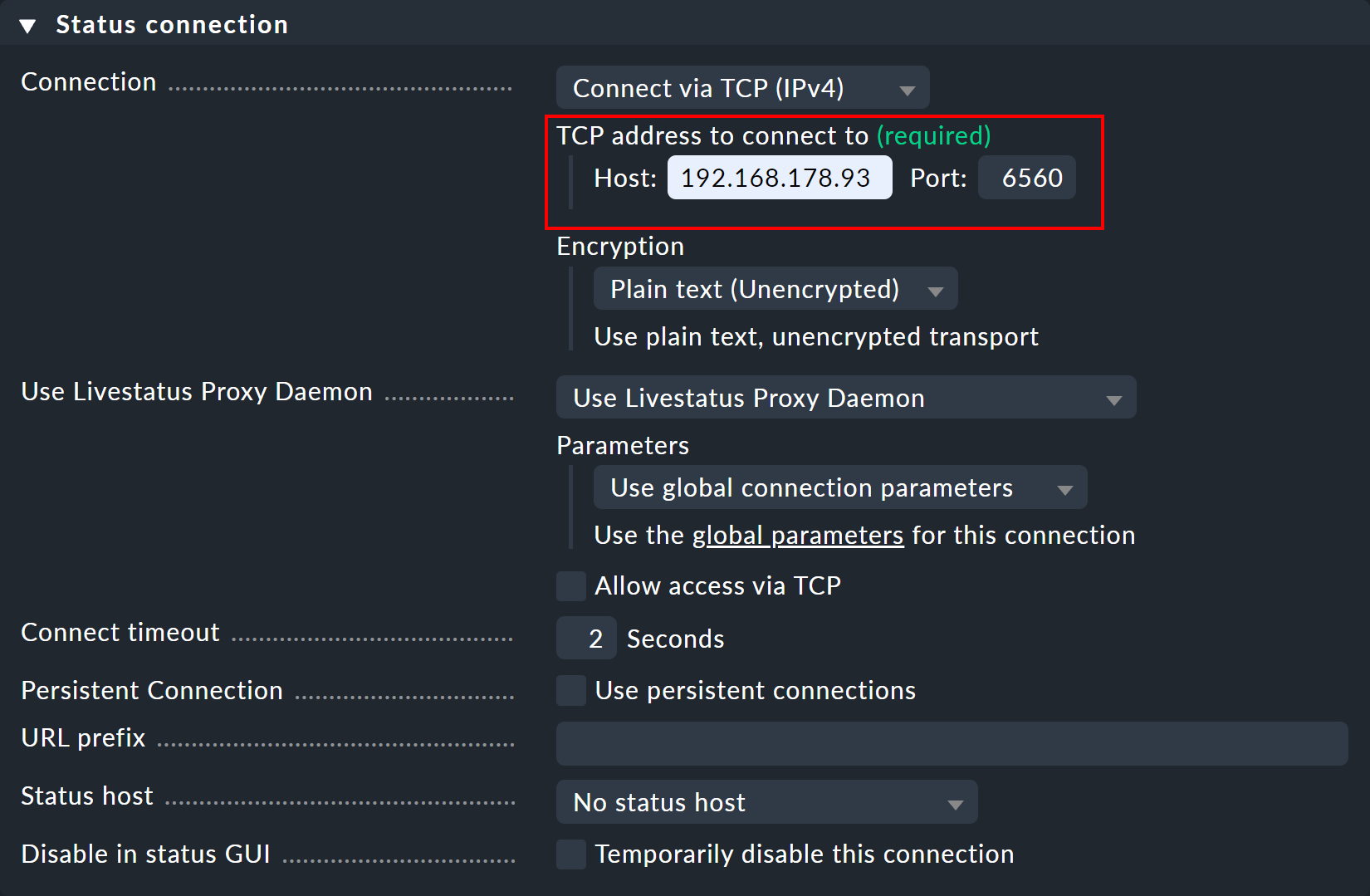
Sobald die Verbindung steht, sehen Sie die gewünschten Hosts und Services der Remote-Instanz in den Monitoring-Ansichten der Viewer-Instanz.
Möchten Sie weiter kaskadieren, müssen Sie auf der Viewer-Instanz, wie zuvor auf der Zentralinstanz, ebenfalls den TCP-Zugriff auf den Livestatus-Proxy erlauben, erneut mit einem anderen, freien Port.
5. Livedump und CMCDump
5.1. Motivation
Das bisher beschriebene Konzept für ein verteiltes Monitoring mit Checkmk ist in den meisten Fällen eine gute und einfache Lösung. Es erfordert allerdings Netzwerkzugriff von der Zentralinstanz auf die Remote-Instanzen. Es gibt Situationen, in denen das entweder nicht möglich oder nicht gewünscht ist, z.B. weil
die Instanzen in den Netzen Ihrer Kunden stehen, auf die Sie keinen Zugriff haben,
die Instanzen in einem Sicherheitsbereich stehen, auf den Zugriff strikt verboten ist oder
die Instanzen keine permanente Netzwerkverbindung oder keine feste IP-Adressen haben und Techniken, wie Dynamisches DNS keine Option sind.
Das verteilte Monitoring mit Livedump bzw. CMCDump geht einen ganz anderen Weg. Zunächst einmal sind die Remote-Instanzen so aufgesetzt, dass sie völlig unabhängig von der Zentralinstanz arbeiten und dezentral administriert werden. Auf eine verteilte Konfigurationsumgebung wird verzichtet.
Dann werden in der Zentralinstanz alle Hosts und Services der Remote-Instanzen als Kopie angelegt. Dazu kann Livedump/CMCDump einen Abzug der Konfiguration der Remote-Instanzen erstellen, der bei der Zentralinstanz eingespielt wird.
Während des Monitorings wird nun auf jeder Remote-Instanz einmal pro definiertem Intervall
(z.B. jede Minute) ein Abzug des aktuellen Status in eine
Datei geschrieben. Diese wird auf einem beliebigen Weg auf die Zentrale übertragen
und dort als Statusupdate eingespielt. Für die Übertragung ist kein bestimmtes
Protokoll vorgesehen oder vorbestimmt. Alle automatisierbaren Übertragungsprotokolle
kommen in Frage. Es muss nicht unbedingt scp sein — auch eine Übertragung per E-Mail ist denkbar!
Ein solches Setup weist gegenüber dem „normalen“ verteilten Monitoring folgende Unterschiede auf:
Die Aktualisierung der Zustände und Messdaten in der Zentrale geschieht verzögert.
Eine Berechnung der Verfügbarkeit wird auf der Zentralinstanz, im Vergleich mit der Remote-Instanz, geringfügig abweichende Werte ergeben.
Zustandswechsel, die schneller geschehen als das Aktualisierungsintervall, sind für die Zentrale unsichtbar.
Ist eine Remote-Instanz „tot“, so veralten die Zustände auf der Zentralinstanz, die Services werden „stale“, sind aber immer noch sichtbar. Messdaten und Verfügbarkeitsdaten gehen für diesen Zeitraum verloren (auf der Remote-Instanz sind sie noch vorhanden).
Kommandos wie Schedule downtimes und Acknowledge problems auf der Zentralinstanz können nicht auf die Remote-Instanz übertragen werden.
Zu keiner Zeit erfolgt ein Zugriff von der Zentralinstanz auf die Remote-Instanz.
Ein Zugriff auf Logdateidetails von Logwatch ist nicht möglich.
Die Event Console wird von Livedump/CMCDump nicht unterstützt.
Da kurze Zustandswechsel bedingt durch das gewählte Intervall für die Zentralinstanz eventuell nicht sichtbar sind, ist eine Benachrichtigung durch die Zentrale nicht ideal. Wird die Zentrale jedoch als reine Anzeigeinstanz verwendet — z.B. für einen zentralen Überblick über alle Kunden — hat die Methode durchaus ihre Vorteile.
Livedump/CMCDump kann übrigens ohne Probleme gleichzeitig mit dem verteilten Monitoring über Livestatus verwendet werden. Manche Instanzen sind dann einfach direkt über Livestatus angebunden — andere verwenden Livedump. Dabei kann der Livedump auch in eine der entfernten Livestatus-Instanzen eingespielt werden.
5.2. Aufsetzen von Livedump
![]() Wenn Sie die
Wenn Sie die ![]() Checkmk Raw Edition einsetzen (oder die CEE mit Nagios als Kern), dann
verwenden Sie das Werkzeug
Checkmk Raw Edition einsetzen (oder die CEE mit Nagios als Kern), dann
verwenden Sie das Werkzeug livedump. Der Name leitet sich ab von
Livestatus und Status-Dump.
livedump befindet sich direkt im Suchpfad und ist daher global als Befehl verfügbar.
Wir gehen im Folgenden davon aus, dass
die Remote-Instanz bereits voll eingerichtet ist und fleißig Hosts und Services überwacht,
die Zentralinstanz gestartet ist und läuft und
auf der Zentrale mindestens ein Host lokal überwacht wird (z.B. weil sie sich selbst überwacht).
Übertragen der Konfiguration
Als Erstes erzeugen Sie auf der Remote-Instanz einen Abzug der Konfiguration Ihrer
Hosts und Services im Nagios-Konfigurationsformat. Leiten Sie dazu die Ausgabe von livedump -TC in eine Datei
um:
OMD[remote1]:~$ livedump -TC > config-remote1.cfgDer Anfang der Datei sieht in etwa wie folgt aus:
define host {
name livedump-host
use check_mk_default
register 0
active_checks_enabled 0
passive_checks_enabled 1
}
define service {
name livedump-service
register 0
active_checks_enabled 0
passive_checks_enabled 1
check_period 0x0
}Übertragen Sie die Datei zu der Zentralinstanz (z.B. mit scp) und legen Sie sie
dort in das Verzeichnis ~/etc/nagios/conf.d/. In diesem erwartet Nagios die Konfiguration
für Hosts und Services. Wählen Sie einen Dateinamen, der auf .cfg
endet, z.B. ~/etc/nagios/conf.d/config-remote1.cfg. Wenn ein SSH-Zugang
von der Remote-Instanz auf die Zentralinstanz möglich ist, geht das z.B. so:
OMD[remote1]:~$ scp config-remote1.cfg central@myserver.mydomain:etc/nagios/conf.d/
central@myserver.mydomain's password:
config-remote1.cfg 100% 8071 7.9KB/s 00:00Loggen Sie sich jetzt auf der Zentralinstanz ein und aktivieren Sie die Änderungen:
OMD[central]:~$ cmk -R
Generating configuration for core (type nagios)...OK
Validating Nagios configuration...OK
Precompiling host checks...OK
Restarting monitoring core...OKNun sollten alle Hosts und Services der Remote-Instanz in der Zentralinstanz auftauchen — und zwar im Zustand PEND, in dem sie bis auf Weiteres auch bleiben:
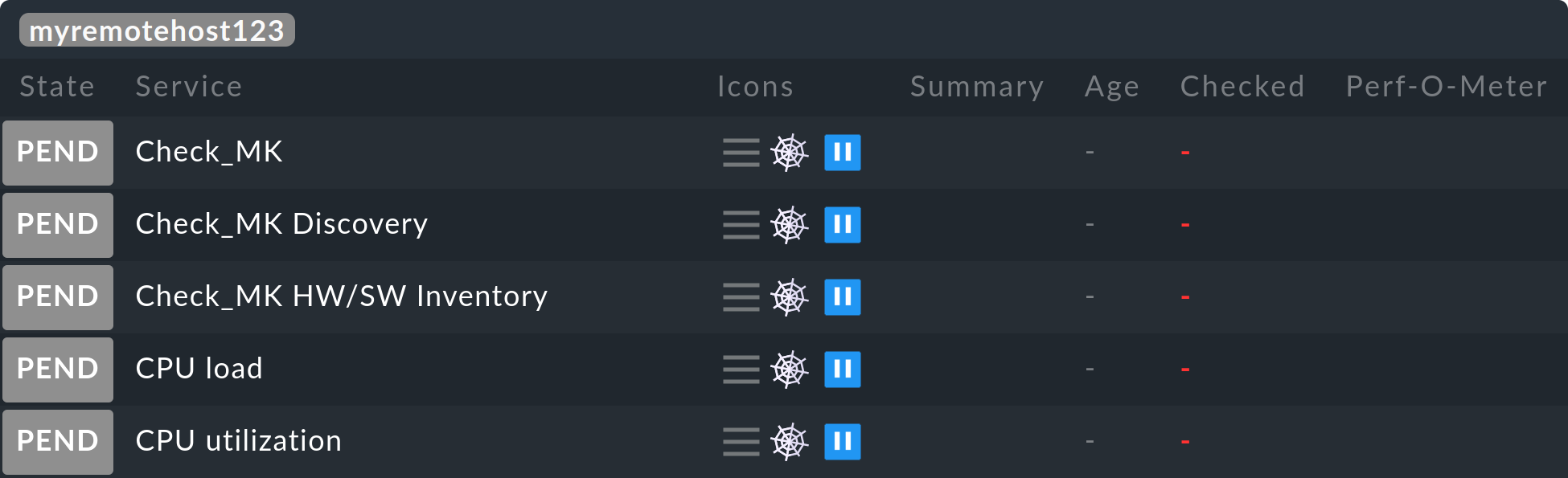
Hinweise:
Durch die Option
-Tbeilivedumperzeugt Livedump Template-Definitionen, auf die sich die Konfiguration bezieht. Ohne diese kann Nagios nicht gestartet werden. Sie dürfen jedoch nur einmal vorhanden sein. Falls Sie auch von einer zweiten Remote-Instanz eine Konfiguration übertragen, so dürfen Sie die Option-Tdort nicht verwenden!Der Dump der Konfiguration ist auch auf einem Checkmk Micro Core (CMC) möglich, das Einspielen benötigt Nagios. Wenn auf Ihrer Zentralinstanz der CMC läuft, dann verwenden Sie CMCDump.
Das Abziehen und Übertragen der Konfiguration müssen Sie nach jeder Änderung von Hosts oder Services auf der Remote-Instanz wiederholen.
Übertragung des Status
Nachdem die Hosts in der Zentralinstanz sichtbar sind, geht es jetzt an die (regelmäßige)
Übertragung des Monitoring-Status der Remote-Instanz. Wieder erzeugen Sie mit livedump
eine Datei, allerdings diesmal ohne weitere Optionen:
OMD[remote1]:~$ livedump > stateDiese Datei enthält den Zustand aller Hosts und Services in einem Format, welches Nagios direkt aus dem Check-Ergebnis einlesen kann. Der Anfang sieht etwa so aus:
host_name=myhost1900
check_type=1
check_options=0
reschedule_check
latency=0.13
start_time=1615521257.2
finish_time=16175521257.2
return_code=0
output=OK - 10.1.5.44: rta 0.066ms, lost 0%|rta=0.066ms;200.000;500.000;0; pl=0%;80;100;; rtmax=0.242ms;;;; rtmin=0.017ms;;;;Übertragen Sie diese Datei auf die Zentralinstanz in das Verzeichnis ~/tmp/nagios/checkresults. Wichtig: Der Name der Datei muss mit c beginnen und sieben Zeichen lang sein (Nagios-Vorgabe). Mit scp würde das etwa so aussehen:
OMD[remote1]:~$ scp state central@myserver.mydomain:tmp/nagios/checkresults/caabbcc
server@myserver.mydomain's password:
state 100% 12KB 12.5KB/s 00:00Anschließend erzeugen Sie auf der Zentralinstanz eine leere Datei mit dem gleichen Namen
und der Endung .ok. Dadurch weiß Nagios, dass die Statusdatei komplett
übertragen ist und eingelesen werden kann:
OMD[central]:~$ touch tmp/nagios/checkresults/caabbcc.okDer Zustand der Hosts/Services der Remote-Instanz wird jetzt auf der Zentralinstanz sofort aktualisiert:
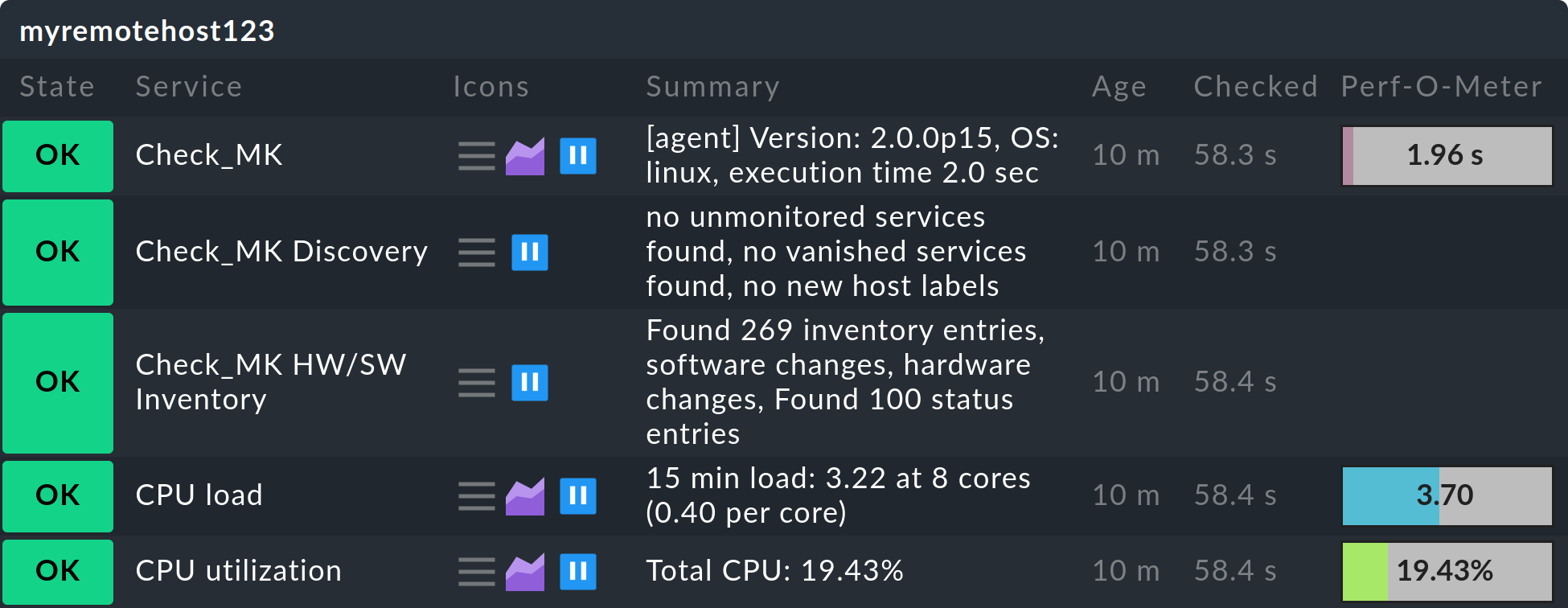
Das Übertragen des Status muss ab jetzt natürlich regelmäßig gemacht
werden. Livedump unterstützt Sie dabei leider nicht und Sie müssen das
selbst skripten. In ~/share/check_mk/doc/treasures/livedump finden
Sie das Skript livedump-ssh-recv, welches Sie einsetzen können,
um Livedumpupdates (auch solche von der Konfiguration) per SSH auf der Zentralinstanz
zu empfangen. Details finden Sie im Skript selbst.
Sie können den Dump von Konfiguration und Status auch
durch die Angabe von Livestatusfiltern einschränken, z.B. die Hosts auf
die Mitglieder der Host-Gruppe mygroup:
OMD[remote1]:~$: livedump -H "Filter: host_groups >= mygroup" > stateWeitere Hinweise zu Livedump finden Sie in der Datei README im Verzeichnis ~/share/doc/check_mk/treasures/livedump.
5.3. Aufsetzen von CMCDump
Was Livedump für Nagios ist, ist CMCDump
für den Checkmk Micro Core — und damit das Tool der Wahl für die
![]() Checkmk Enterprise Editions. Im Gegensatz zu Livedump kann CMCDump den vollständigen Status
von Hosts und Services replizieren (Nagios bietet hier nicht die notwendigen
Schnittstellen).
Checkmk Enterprise Editions. Im Gegensatz zu Livedump kann CMCDump den vollständigen Status
von Hosts und Services replizieren (Nagios bietet hier nicht die notwendigen
Schnittstellen).
Zum Vergleich: Bei Livedump werden folgende Daten übertragen:
Der aktuelle Zustand, also PEND, OK, WARN, CRIT, UNKNOWN, UP, DOWN oder UNREACH
Die Ausgabe des Check-Plugins
Die Messdaten
Zusätzlich synchronisiert CMCDump auch noch
die lange Ausgabe des Plugins,
ob das Objekte gerade
 unstetig ist,
unstetig ist,Zeitpunkt der letzten Check-Ausführung und des letzten Statuswechsels,
Dauer der Check-Ausführung,
Latenz der Check-Ausführung,
die Nummer des aktuellen Checkversuchs und ob der aktuelle Zustand hart oder weich ist,
 Quittierung, falls vorhanden und
Quittierung, falls vorhanden undob das Objekt gerade in einer
 geplanten Wartungszeit ist.
geplanten Wartungszeit ist.
Das Abbild des Monitorings ist hier also viel genauer. Der CMC simuliert beim Einspielen des Status nicht einfach eine Checkausführung, sondern überträgt mittels einer dafür bestimmten Schnittstelle einen korrekten Status. Das bedeutet unter anderem, dass Sie in der Zentrale jederzeit sehen können, ob Probleme quittiert oder Wartungszeiten eingetragen wurden.
Das Aufsetzen ist fast identisch wie bei Livedump, allerdings etwas einfacher, da Sie sich nicht um eventuelle doppelte Templates und dergleichen kümmern müssen.
Der Abzug der Konfiguration geschieht mit cmcdump -C. Legen
Sie diese Datei auf der Zentralinstanz unterhalb von etc/check_mk/conf.d/ ab.
Die Endung muss .mk heißen:
OMD[remote1]:~$ cmcdump -C > config.mk
OMD[remote1]:~$ scp config.mk central@mycentral.mydomain:etc/check_mk/conf.d/remote1.mkAktivieren Sie auf der Zentralinstanz die Konfiguration:
OMD[central]:~$ cmk -OWie bei Livedump erscheinen jetzt die Hosts und Services auf der Zentrale im
Zustand PEND. Allerdings sehen Sie gleich am Symbol ![]() ,
dass es sich um Schattenobjekte handelt. So können Sie diese von
direkt auf der Zentralinstanz oder einer „normalen“ Remote-Instanz überwachten
Objekte unterscheiden:
,
dass es sich um Schattenobjekte handelt. So können Sie diese von
direkt auf der Zentralinstanz oder einer „normalen“ Remote-Instanz überwachten
Objekte unterscheiden:
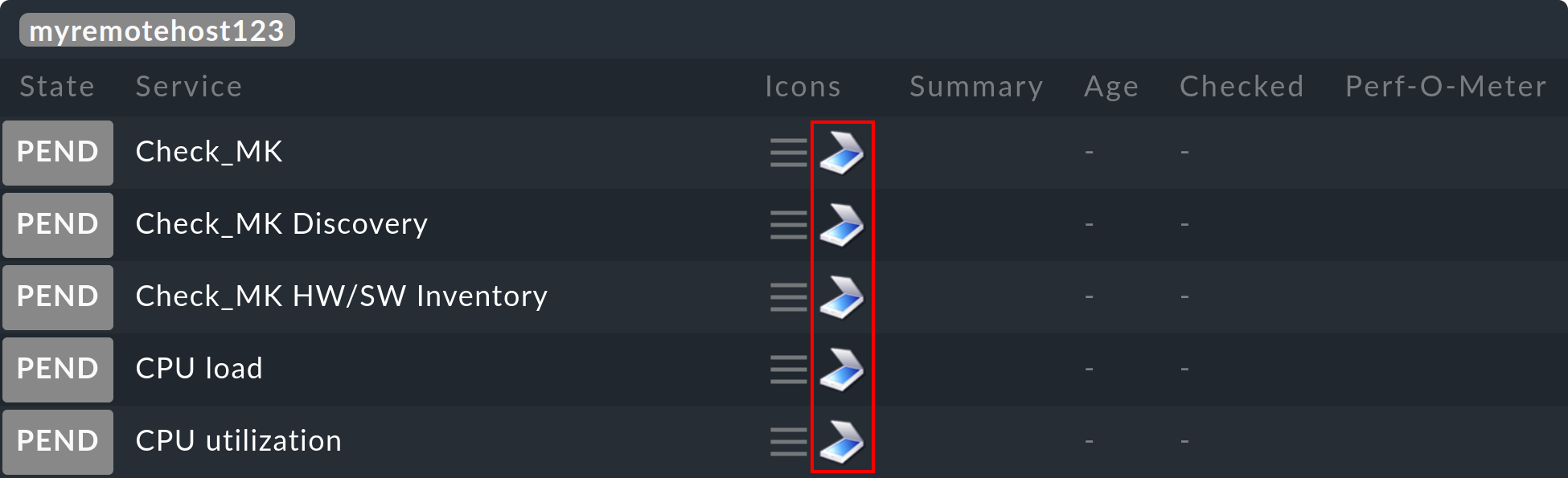
Das regelmäßige Erzeugen des Status geschieht mit cmcdump ohne
weitere Argumente:
OMD[remote1]:~$ cmcdump > state
OMD[remote1]:~$ scp state central@mycentral.mydomain:tmp/state_remote1Zum Einspielen des Status auf der Zentralinstanz muss der Inhalt der Datei mithilfe des
Tools unixcat in das UNIX-Socket tmp/run/live geschrieben
werden:
OMD[central]:~$ unixcat tmp/run/live < tmp/state_remote1Falls Sie per SSH einen passwortlosen Zugang von der Remote-Instanz zur Zentralinstanz haben, können Sie alle drei Befehle zu einem einzigen zusammenfassen — wobei nicht mal eine temporäre Datei entsteht:
OMD[remote1]:~$ cmcdump | ssh central@mycentral.mydomain "unixcat tmp/run/live"Es ist wirklich so einfach! Aber wie schon erwähnt, ist ssh/scp
nicht die einzige Methode, um Dateien zu übertragen und genauso gut können Sie
Konfiguration oder Status per E-Mail oder einem beliebigen anderen Protokoll
übertragen.
6. Benachrichtigungen in verteilten Umgebungen
6.1. Zentral oder dezentral
In einer verteilten Umgebung stellt sich die Frage, von welcher Instanz aus Benachrichtigungen (z.B. E-Mails) verschickt werden sollen: von den einzelnen entfernten Instanzen oder von der Zentralinstanz aus. Für beide gibt es Argumente.
Argumente für den Versand von den Remote-Instanz aus:
Einfacher einzurichten.
Benachrichtigungen vor Ort gehen auch dann, wenn die Verbindung zur Zentrale nicht verfügbar ist.
Geht auch mit der
 Checkmk Raw Edition.
Checkmk Raw Edition.
Argumente für den Versand von der Zentralinstanz aus:
Benachrichtigungen können an einer zentralen Stelle weiterbehandelt werden (z.B. für Weiterleitung in Ticketsystem).
Remote-Instanzen benötigen kein Setup für E-Mail oder SMS.
Bei Versand von SMS über Hardware ist diese nur einmal notwendig: auf der Zentrale.
6.2. Dezentrale Benachrichtigungen
Für die Einrichtung dezentraler Benachrichtigungen sind keine besonderen Schritte notwendig, denn dies ist die Standardeinstellung. Jede Benachrichtigung, die auf einer Remote-Instanz entsteht, durchläuft dort die Kette der Kette der Benachrichtigungsregeln. Falls Sie eine verteilte Konfigurationsumgebung einsetzen, sind diese Regeln auf allen Instanzen gleich. Aus den Regeln resultierende Benachrichtigungen werden wie üblich zugestellt, indem lokal die entsprechenden Benachrichtigungsskripte aufgerufen werden.
Sie müssen lediglich sicherstellen, dass die entsprechenden Dienste auf den Instanzen korrekt aufgesetzt sind, also z.B. für E-Mail ein Smarthost eingetragen ist — also die gleichen Schritte wie beim Einrichten einer einzelnen Checkmk-Instanz.
6.3. Zentrale Benachrichtigungen
Grundlegendes
![]() Die
Die ![]() Checkmk Enterprise Editions bieten einen eingebauten Mechanismus für zentralisierte Benachrichtigungen, welcher pro Remote-Instanz einzeln aktiviert werden kann.
Solche Remote-Instanzen leiten dann alle Benachrichtigungen zur weiteren Verarbeitung an die Zentralinstanz weiter.
Dabei ist die zentrale Benachrichtigung unabhängig davon, ob Sie Ihr verteiltes Monitoring auf dem klassischen Weg oder mit CMCDump oder einer Mischung davon eingerichtet haben.
Genau genommen muss der zentrale Benachrichtigungsserver nicht mal die Zentralinstanz sein. Diese Aufgabe kann jede Checkmk-Instanz übernehmen.
Checkmk Enterprise Editions bieten einen eingebauten Mechanismus für zentralisierte Benachrichtigungen, welcher pro Remote-Instanz einzeln aktiviert werden kann.
Solche Remote-Instanzen leiten dann alle Benachrichtigungen zur weiteren Verarbeitung an die Zentralinstanz weiter.
Dabei ist die zentrale Benachrichtigung unabhängig davon, ob Sie Ihr verteiltes Monitoring auf dem klassischen Weg oder mit CMCDump oder einer Mischung davon eingerichtet haben.
Genau genommen muss der zentrale Benachrichtigungsserver nicht mal die Zentralinstanz sein. Diese Aufgabe kann jede Checkmk-Instanz übernehmen.
Ist eine Remote-Instanz auf Weiterleitung eingestellt, so werden alle Benachrichtigungen direkt wie Sie vom Kern kommen — quasi in Rohform (wir sprechen hier auch von den Rohbenachrichtigungen) — an die Zentralinstanz weitergereicht. Erst dort werden die Benachrichtigungsregeln ausgewertet, welche entscheiden, wer und wie überhaupt benachrichtigt werden soll. Die dazu notwendigen Benachrichtigungsskripte werden auf der Zentralinstanz aufgerufen.
Einrichten der TCP-Verbindungen
Die Benachrichtigung-Spooler von entfernter und zentraler (Benachrichtigungs-)Instanz tauschen sich untereinander per TCP aus. Benachrichtigungen werden von der Remote-Instanz zur Zentralinstanz gesendet. Die Zentrale quittiert empfangene Benachrichtigungen an die Remote-Instanz, was verhindert, dass Benachrichtigungen verloren gehen, selbst wenn die TCP-Verbindung abbrechen sollte.
Für den Aufbau der TCP-Verbindung haben Sie zwei Möglichkeiten:
TCP-Verbindung wird von Zentralinstanz zur Remote-Instanz aufgebaut. Hier ist die Remote-Instanz der TCP-Server.
TCP-Verbindung wird von Remote-Instanz zur Zentralinstanz aufgebaut. Hier ist die Zentralinstanz der TCP-Server.
Somit steht dem Weiterleiten von Benachrichtigungen auch dann nichts im Wege, wenn aus Netzwerkgründen der Verbindungsaufbau nur in eine bestimmte Richtung möglich ist. Die TCP-Verbindungen werden vom Spooler mit einem Heartbeatsignal überwacht und bei Bedarf sofort neu aufgebaut — nicht erst im Falle einer Benachrichtigung.
Da Remote-Instanz und Zentralinstanz für den Spooler unterschiedliche globale Einstellungen brauchen, müssen Sie diese für alle Remote-Instanzen instanzspezifische Einstellungen machen. Die Konfiguration der Zentrale geschieht über die normalen globalen Einstellungen. Bitte beachten Sie, dass diese automatisch an alle Remote-Instanzen vererbt wird, für die Sie keine spezifischen Einstellungen definiert haben.
Betrachten Sie zuerst den Fall, dass die Zentralinstanz die TCP-Verbindungen zu den Remote-Instanzen aufbauen soll.
Schritt 1: Editieren Sie bei der Remote-Instanz die instanzspezifische globale Einstellung Notifications > Notification Spooler Configuration und aktivieren Sie Accept incoming TCP connections. Als TCP-Port wird 6555 vorgeschlagen. Sofern nichts dagegen spricht, übernehmen Sie diese Einstellung.
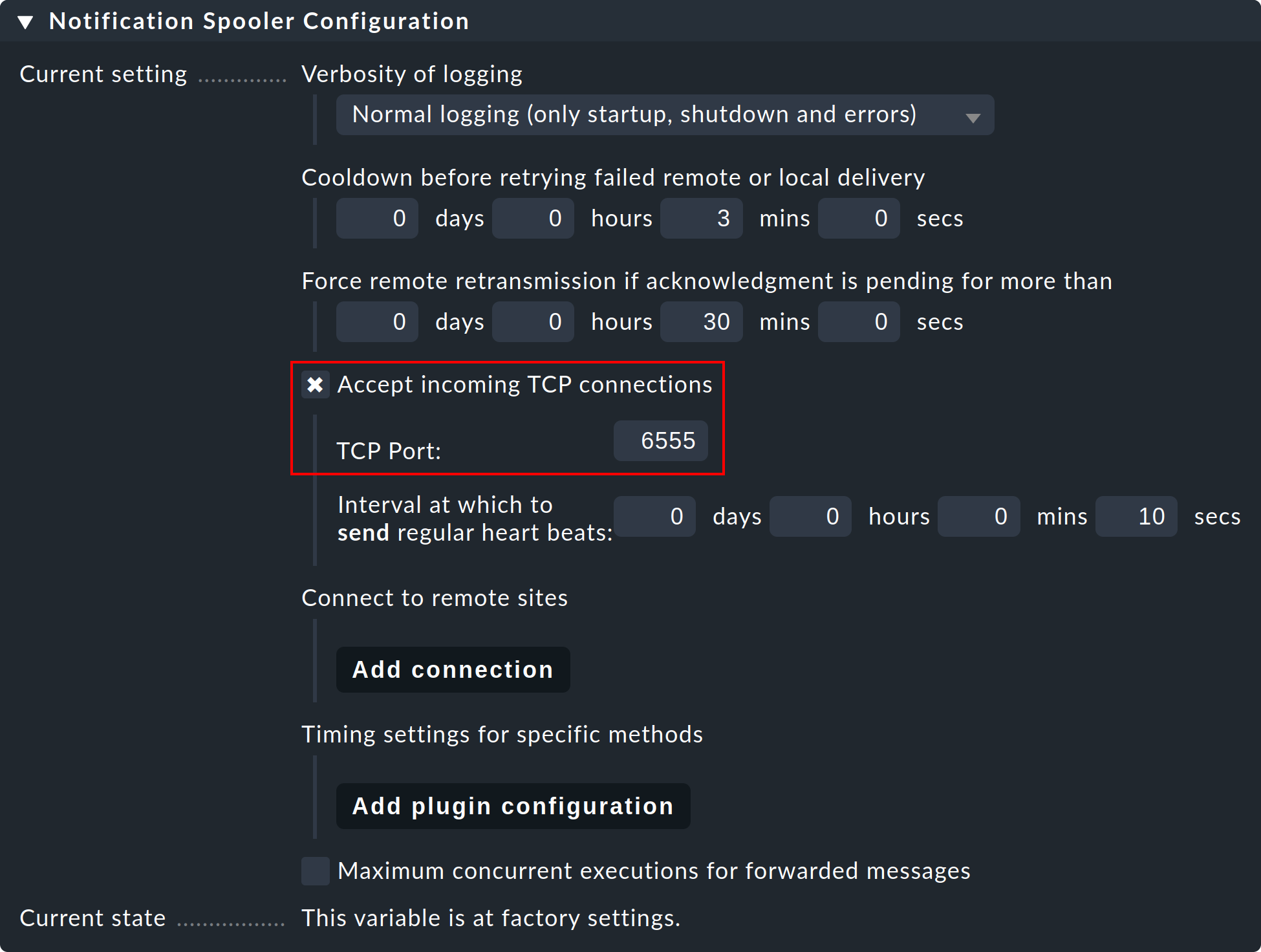
Schritt 2: Setzen Sie nun ebenfalls nur auf der Remote-Instanz die Einstellung Notification Spooling auf den Wert Forward to remote site by notification spooler.

Schritt 3: Auf der Zentralinstanz — also in den normalen globalen Einstellungen — richten Sie nun zu der Remote-Instanz (und später dann auch eventuell zu weiteren Remote-Instanzen) die Verbindungen ein:
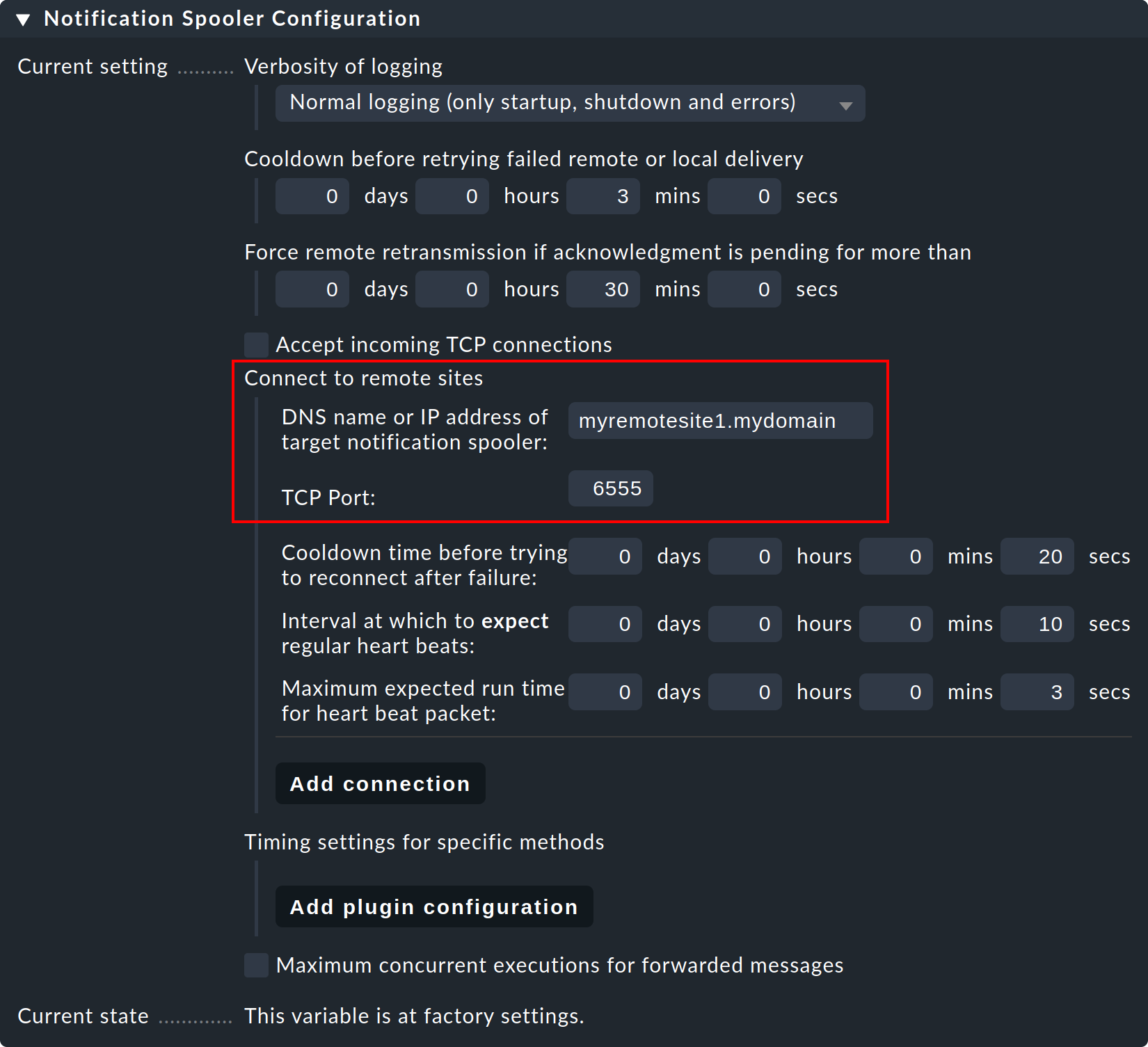
Schritt 4: Setzen Sie die globale Einstellung Notification Spooling auf Asynchronous local delivery by notification spooler, damit auch die Meldungen der Zentrale über den gleichen zentralen Spooler abgewickelt werden.

Schritt 5: Aktivieren Sie die Änderungen.
Verbindungsaufbau von der Remote-Instanz aus
Soll die TCP-Verbindung von der Remote-Instanz aus aufgebaut werden, so ist das Vorgehen identisch, bis auf die Tatsache, dass Sie die oben gezeigten Einstellungen einfach zwischen Zentralinstanz und Remote-Instanz vertauschen.
Auch eine Mischung ist möglich. In diesem Fall muss die Zentrale so aufgesetzt werden, dass sie sowohl auf eingehende Verbindungen lauscht, als auch Verbindungen zu entfernten Instanzen aufbaut. Für jede Beziehung zwischen Zentralinstanz und Remote-Instanz darf aber nur einer von beiden die Verbindung aufbauen!
Test und Diagnose
Der Benachrichtigungs-Spooler loggt in die Datei var/log/mknotifyd.log.
In den Spooler-Einstellungen können Sie das Loglevel erhöhen, so dass Sie mehr Meldungen kommen.
Bei einem Standardloglevel sollten Sie auf der Zentralinstanz etwa Folgendes sehen:
2021-11-17 07:11:40,023 [20] [cmk.mknotifyd] -----------------------------------------------------------------
2021-11-17 07:11:40,023 [20] [cmk.mknotifyd] Check_MK Notification Spooler version 2.0.0p15 starting
2021-11-17 07:11:40,024 [20] [cmk.mknotifyd] Log verbosity: 0
2021-11-17 07:11:40,025 [20] [cmk.mknotifyd] Daemonized with PID 31081.
2021-11-17 07:11:40,029 [20] [cmk.mknotifyd] Connection to 10.1.8.44 port 6555 in progress
2021-11-17 07:11:40,029 [20] [cmk.mknotifyd] Successfully connected to 10.1.8.44:6555Die Datei var/log/mknotifyd.state enthält stets einen aktuellen Zustand des Spoolers und aller seiner Verbindungen:
Connection: 10.1.8.44:6555
Type: outgoing
State: established
Status Message: Successfully connected to 10.1.8.44:6555
Since: 1637129500 (2021-11-17 07:11:40, 140 sec ago)
Connect Time: 0.002 secDie gleiche Datei gibt es auch auf der Remote-Instanz. Dort sieht die Verbindung etwa so aus:
Connection: 10.22.4.12:56546
Type: incoming
State: established
Since: 1637129500 (2021-11-17 07:11:40, 330 sec ago)Zum Testen wählen Sie z.B. einen beliebigen Service, der auf der Remote-Instanz überwacht wird, und setzen diesen per Kommando Fake check results auf CRIT.
Auf der Zentrale sollen Sie nun in der entsprechenden Log-Datei (notify.log) die eingehenden Benachrichtigung sehen:
2021-11-17 07:59:36,231 ----------------------------------------------------------------------
2021-11-17 07:59:36,232 [20] [cmk.base.notify] Got spool file 307ad477 (myremotehost123;Check_MK) from remote host for local delivery.Das gleiche Ereignis sieht bei der Remote-Instanz so aus:
2021-11-17 07:59:28,161 [20] [cmk.base.notify] ----------------------------------------------------------------------
2021-11-17 07:59:28,161 [20] [cmk.base.notify] Got raw notification (myremotehost123;Check_MK) context with 71 variables
2021-11-17 07:59:28,162 [20] [cmk.base.notify] Creating spoolfile: /omd/sites/remote1/var/check_mk/notify/spool/307ad477-b534-4cc0-99c9-db1c517b31f3In den globalen Einstellungen können Sie sowohl das normale Benachrichtigungslog (notify.log) als auch das Log des Benachrichtigungs-Spoolers auf ein höheres Loglevel umstellen.
Überwachung des Spoolings
Nachdem Sie alles wie beschrieben aufgesetzt haben, werden Sie feststellen, dass sowohl auf der Zentralinstanz, als auch auf den Remote-Instanzen jeweils ein neuer Service gefunden wird, den Sie unbedingt in die Überwachung aufnehmen sollten. Dieser überwacht den Benachrichtigungs-Spooler und dessen TCP-Verbindungen. Dabei wird jede Verbindung zweimal überwacht: einmal durch die Zentralinstanz und einmal durch die Remote-Instanz:
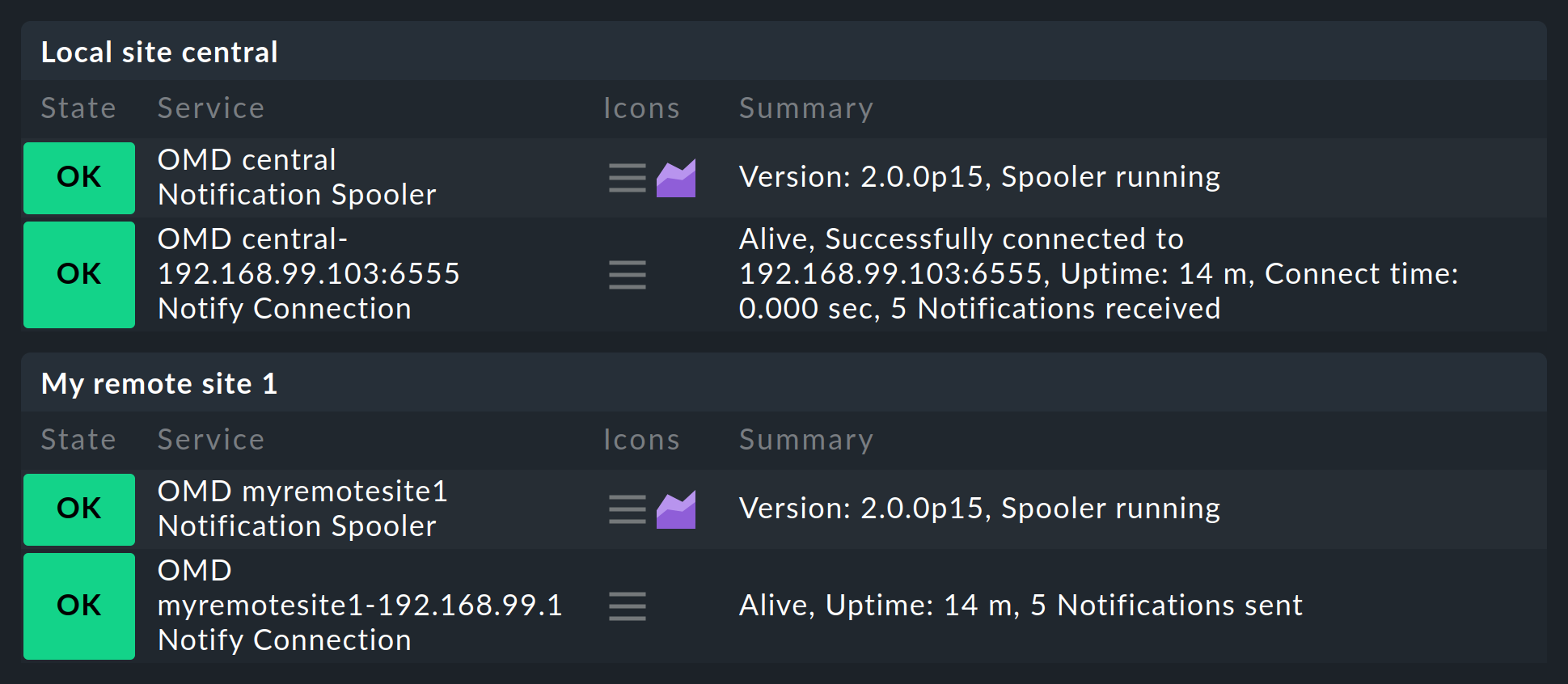
7. Dateien und Verzeichnisse
7.1. Konfigurationsdateien
| Pfad | Bedeutung |
|---|---|
|
Hier speichert Checkmk die Konfiguration der Verbindungen zu den einzelnen Instanzen. Sollte aufgrund von Fehlkonfiguration die Oberfläche so „hängen“, dass sie nicht mehr bedienbar ist, können Sie die störenden Einträge direkt in dieser Datei editieren. Falls der Livestatus-Proxy zum Einsatz kommt, ist anschließend jedoch ein Editieren und Speichern mindestens einer Verbindung notwendig, da erst hierbei für diesen Daemon eine passende Konfiguration erzeugt wird. |
|
Konfiguration für den Livestatus-Proxy. Diese Datei wird von Checkmk bei jeder Änderung an der Konfiguration des verteilten Monitorings neu generiert. |
|
Konfiguration für den Benachrichtigungs-Spooler. Diese Datei wird von Checkmk beim Speichern der globalen Einstellungen erzeugt. |
|
Wird auf den Remote-Instanzen erzeugt und sorgt dafür, dass diese nur ihre eigenen Hosts überwachen. |
|
Ablageort für selbst erstellte Nagios-Konfigurationsdateien mit Hosts und Services. Dies wird beim Einsatz von Livedump auf der Zentralinstanz benötigt. |
|
Konfiguration von Livestatus bei Verwendung von Nagios als Kern. Hier können Sie die maximale gleichzeitige Anzahl von Verbindungen konfigurieren. |
|
Konfiguration von Hosts und Regeln für Checkmk. Legen Sie hier Konfigurationsdateien ab, die per CMCDump erzeugt wurden. Nur das Unterverzeichnis |
|
Von der Serviceerkennung gefundene Services. Dieses werden immer lokal auf der Remote-Instanz gespeichert. |
|
Ablage der Round-Robin-Datenbanken für die Archivierung der Messwerte beim Einsatz des Checkmk-RRD-Formats (Default bei den Enterprise Editions). |
|
Ablage der Round-Robin-Datenbanken bei PNP4Nagios-Format ( |
|
Logdatei des Livestatus-Proxys. |
|
Aktueller Zustand des Livestatus-Proxys in lesbarer Form. Diese Datei wird alle fünf Sekunden aktualisiert. |
|
Logdatei des Checkmk-Benachrichtigungssystems. |
|
Logdatei des Benachrichtigungs-Spoolers. |
|
Aktueller Zustand des Benachrichtigungs-Spoolers in lesbarer Form. Diese Datei wird alle 20 Sekunden aktualisiert. |