1. Einleitung
1.1. Ereignisse sind keine Zustände
Die Hauptaufgabe von Checkmk ist das aktive Überwachen von Zuständen. Zu jedem Zeitpunkt hat jeder überwachte Service einen der Zustände OK, WARN, CRIT oder UNKNOWN. Durch regelmäßige Abfragen aktualisiert das Monitoring ständig sein Bild von der Lage.
Eine ganz andere Art des Monitorings ist das Arbeiten mit Ereignissen (events). Ein Beispiel für ein Ereignis ist eine Exception, die in einer Anwendung auftritt. Die Anwendung läuft eventuell korrekt weiter und hat nach wie vor den Zustand OK — aber irgendetwas ist passiert.
1.2. Die Event Console
Checkmk verfügt mit der Event Console (kurz EC) über ein voll integriertes System zur Überwachung von Ereignissen aus Quellen wie Syslog, SNMP-Traps, Windows Event Logs, Log-Dateien und eigenen Anwendungen. Dabei werden aus Ereignissen nicht einfach Zustände gemacht, sondern sie bilden eine eigene Kategorie und werden von Checkmk sogar im Overview der Seitenleiste mit angezeigt:
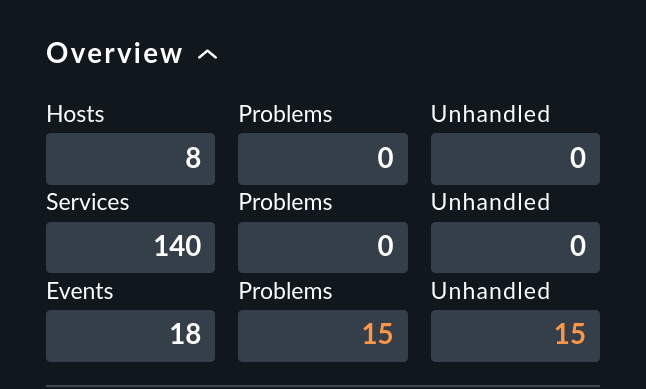
Intern werden Ereignisse nicht durch den Monitoring-Kern, sondern von einem eigenen Dienst verarbeitet — dem Event Daemon (mkeventd).
Die Event Console verfügt auch über ein Archiv, in dem Sie über Ereignisse in der Vergangenheit recherchieren können. Gleich vorweg sei allerdings gesagt: Dies ist kein Ersatz für ein echtes Log-Archiv. Die Aufgabe der Event Console ist das intelligente Herausfiltern einer kleinen Zahl von relevanten Meldungen aus einem großen Strom. Sie ist optimiert auf Einfachheit, Robustheit und Durchsatz — nicht auf Speicherung großer Datenmengen.
Ein kurzer Abriss der Funktionalität der EC:
Sie kann Meldungen per Syslog oder SNMP-Traps direkt empfangen. Eine Konfiguration der entsprechenden Linux-Systemdienste ist daher nicht notwendig.
Sie kann mithilfe der Checkmk-Agenten auch textbasierte Log-Dateien und Windows Event Logs auswerten.
Sie klassifiziert Meldungen anhand einer Kette von benutzerdefinierten Regeln.
Sie kann Meldungen korrelieren, zusammenfassen, zählen, annotieren, umschreiben und auch deren zeitliche Zusammenhänge berücksichtigen.
Sie kann automatisiert Aktionen ausführen und über Checkmk Benachrichtigungen versenden.
Sie ist voll in die Oberfläche von Checkmk integriert.
Sie ist in jedem aktuellen Checkmk-System enthalten und sofort einsatzfähig.
1.3. Begriffe
Die Event Console empfängt Meldungen (meist in Form von Log Messages). Eine Meldung ist eine Zeile Text mit einer Reihe von möglichen Zusatzattributen, wie z.B. einem Zeitstempel, einem Host-Namen usw. Wenn die Meldung relevant ist, wird daraus direkt ein Event mit den gleichen Attributen, aber:
Nur wenn eine Regel greift, wird aus einer Meldung ein Event erzeugt.
Regeln können den Text und andere Attribute von Meldungen verändern.
Mehrere Meldungen können zu einem Event zusammengefasst werden.
Meldungen können aktuelle Events wieder aufheben.
Künstliche Events können erzeugt werden, wenn bestimmte Meldungen ausbleiben.
Ein Event kann verschiedene Phasen durchlaufen:
open |
Der „normale“ Zustand: Etwas ist passiert: der Operator soll sich kümmern. |
acknowledged |
Das Problem wurde quittiert — dies ist analog zu Host- und Service-Problemen aus dem statusbasierten Monitoring. |
counting |
Es ist noch nicht die erforderliche Anzahl von bestimmten Meldungen eingetroffen: die Situation ist noch unproblematisch. Das Ereignis wird dem Operator deswegen noch nicht angezeigt. |
delayed |
Eine Störmeldung ist eingegangen, aber die Event Console wartet noch, ob in einer konfigurierten Zeit die passende OK-Meldung eingeht. Erst danach wird das Event dem Operator angezeigt. |
closed |
Das Event wurde vom Operator oder automatisch geschlossen und ist nur noch im Archiv. |
Ein Event hat ferner einen Zustand. Genau genommen ist hier aber nicht der Zustand des Events selbst gemeint, sondern des Dienstes oder Gerätes, der/das den Event gesendet hat. Um eine Analogie zum statusbasierten Monitoring zu schaffen, ist auch ein Event als OK, WARN, CRIT oder UNKNOWN eingestuft.
2. Die Event Console aufsetzen
Das Einrichten der Event Console ist sehr einfach, da die Event Console fester Bestandteil von Checkmk ist und automatisch aktiviert wird.
Falls Sie jedoch über das Netzwerk Syslog-Meldungen oder SNMP-Traps empfangen möchten, so müssen Sie dies separat aktivieren. Der Grund ist, dass beide Dienste einen UDP-Port mit einer jeweils bestimmten bekannten Portnummer öffnen müssen. Und da dies pro System nur eine Checkmk Instanz machen kann, ist der Empfang über das Netzwerk per Default abgeschaltet.
Die Port-Nummern sind:
| Protokoll | Port | Dienst |
|---|---|---|
UDP |
162 |
SNMP-Traps |
UDP |
514 |
Syslog |
TCP |
514 |
Syslog via TCP |
Syslog via TCP wird nur selten verwendet, hat aber den Vorteil, dass die Übertragung der Meldungen hier abgesichert wird. Bei UDP ist niemals garantiert, dass Pakete wirklich ankommen. Und weder Syslog noch SNMP-Traps bieten Quittungen oder einen ähnlichen Schutz vor verlorengegangen Meldungen. Damit Sie Syslog via TCP verwenden können, muss natürlich auch das sendende System dazu in der Lage sein, Meldungen über diesen Port zu verschicken.
In der Checkmk Appliance können Sie den Empfang von Syslog/SNMP-Traps in der Instanzkonfiguration einschalten.
Ansonsten verwenden Sie einfach omd config.
Sie finden die benötigte Einstellung unter Addons:
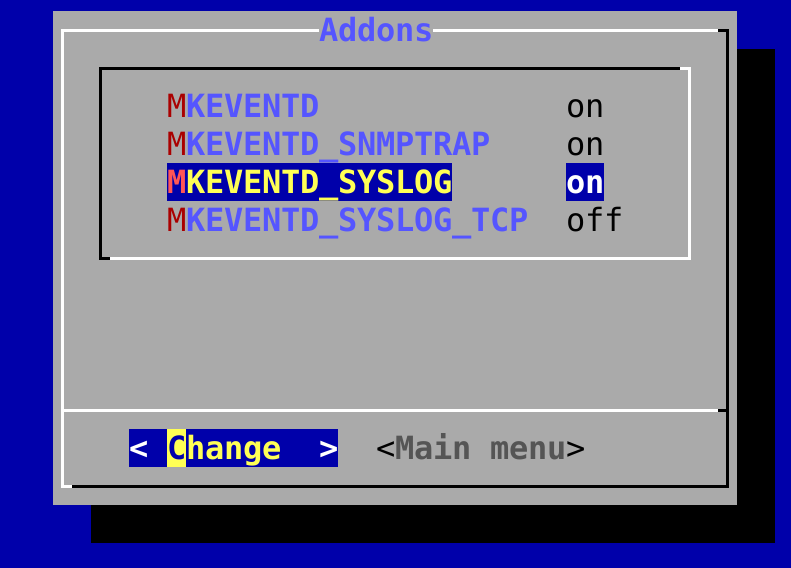
Beim omd start sehen Sie in der Zeile mit mkeventd, welche externen Schnittstellen Ihre EC offen hat:
OMD[mysite]:~$ omd start
Creating temporary filesystem /omd/sites/mysite/tmp...OK
Starting mkeventd (builtin: syslog-udp,snmptrap)...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
Initializing Crontab...OK3. Erste Schritte mit der Event Console
3.1. Regeln, Regeln, Regeln
Eingangs wurde erwähnt, dass die EC dazu dient, relevante Meldungen herauszufischen und anzuzeigen. Nun ist es leider so, dass die meisten Meldungen — egal ob aus Textdateien, dem Windows Event Log oder dem Syslog — ziemlich unwichtig sind. Und da hilft es auch nichts, wenn Meldungen seitens des Verursachers bereits voreingestuft sind.
Zum Beispiel gibt es in Syslog und im Windows Event Log eine Klassifizierung der Meldungen in etwas Ähnliches wie OK, WARN und CRIT. Aber was jetzt WARN und CRIT ist, hat dabei der jeweilige Programmierer subjektiv festgelegt. Und es ist noch nicht einmal gesagt, dass die Anwendung, welche die Meldung produziert hat, auf diesem Rechner überhaupt wichtig ist. Kurzum: Sie kommen nicht drumherum, selbst zu konfigurieren, welche Meldungen für Sie nach einem Problem aussehen und welche einfach verworfen werden können.
Wie überall in Checkmk erfolgt auch hier die Konfiguration über Regeln, welche bei jeder eingehenden Meldung von der EC nach dem „first match“-Prinzip abgearbeitet werden. Die erste Regel, die auf eine eingehende Meldung greift, entscheidet also über deren Schicksal. Greift keine Regel, so wird die Meldung einfach lautlos verworfen.
Da man bei der EC mit der Zeit gewöhnlich sehr viele Regeln aufbaut, sind die Regeln hier in Paketen organisiert. Die Abarbeitung geschieht Paket für Paket und innerhalb eines Pakets von oben nach unten. Damit ist auch die Reihenfolge der Pakete wichtig.
3.2. Anlegen einer einfachen Regel
Die Konfiguration der EC finden Sie wenig überraschend im Setup-Menü unter Events > Event Console. Ab Werk finden Sie dort nur das Default rule pack, das aber keine Regeln enthält. Eingehende Meldungen werden demnach, wie bereits erwähnt, verworfen und auch nicht geloggt. Das Modul präsentiert sich so:
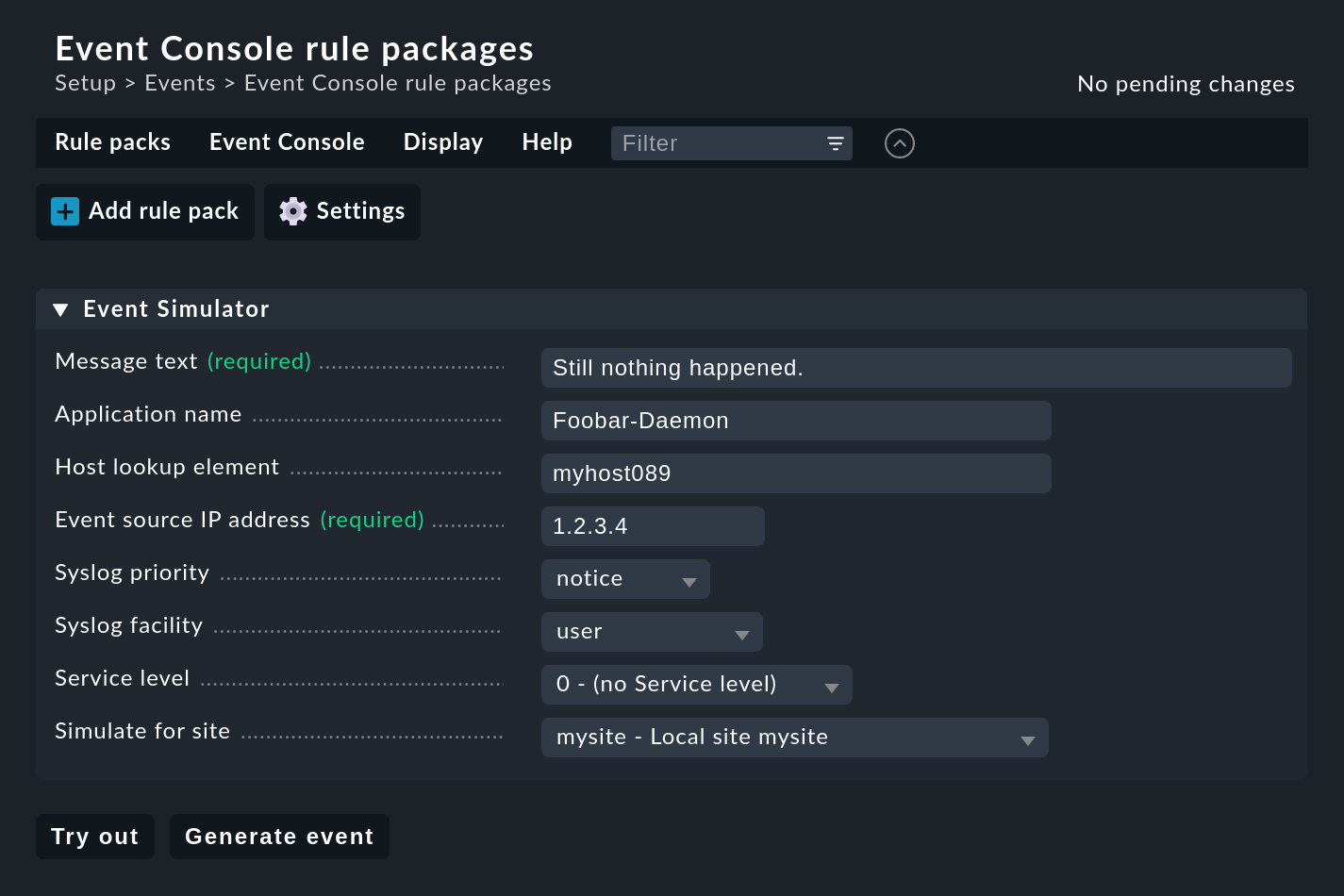
Legen Sie nun mit ![]() Add rule pack als Erstes ein neues Regelpaket an:
Add rule pack als Erstes ein neues Regelpaket an:
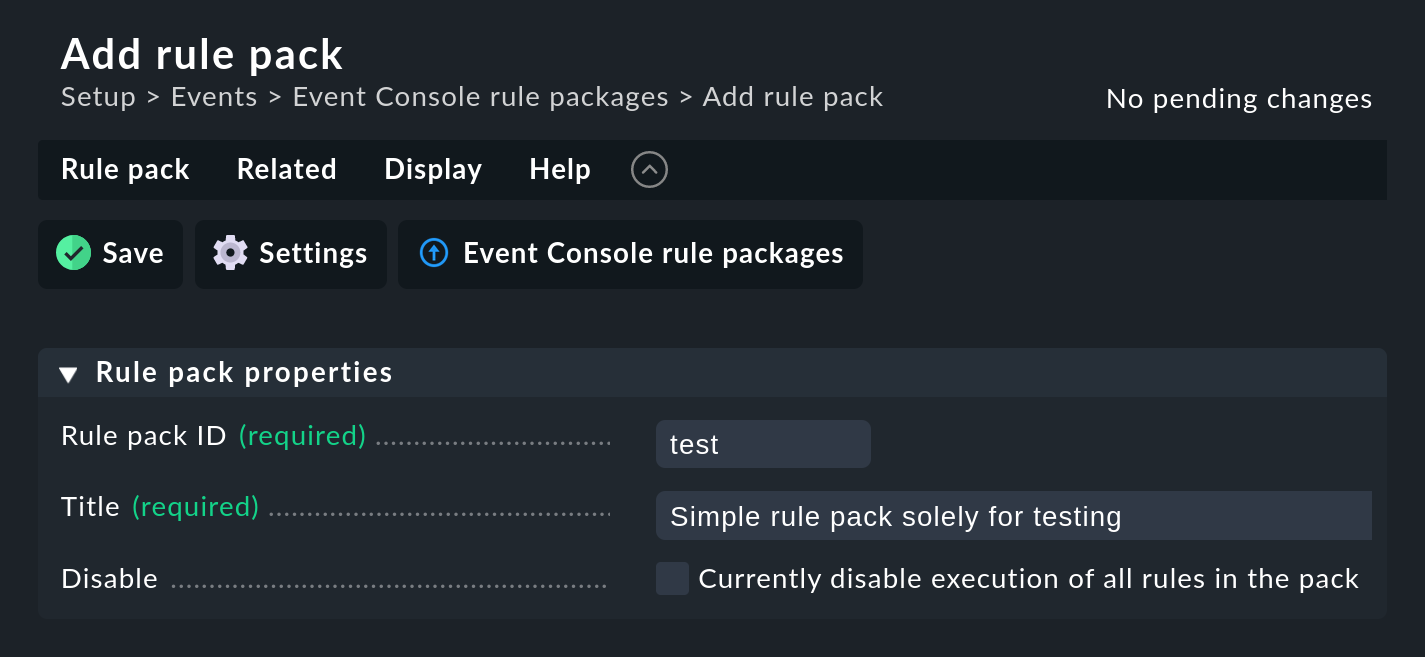
Wie immer gilt die ID als interne Referenz und kann später nicht mehr geändert werden. Nach dem Speichern finden Sie den neuen Eintrag in der Liste Ihrer Regelpakete:
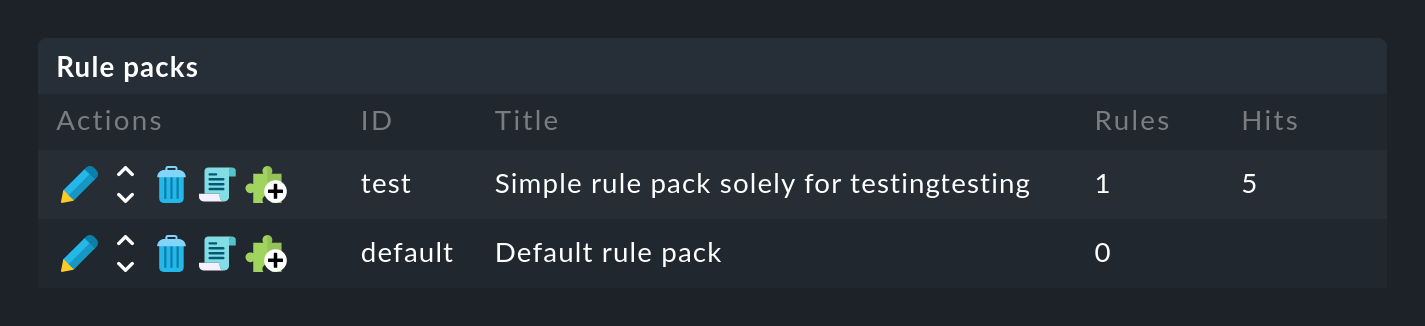
Dort können Sie jetzt mit ![]() in das noch leere Paket wechseln und mit
in das noch leere Paket wechseln und mit ![]() Add rule eine neue Regel anlegen.
Füllen Sie hier lediglich den ersten Kasten mit der Überschrift Rule Properties:
Add rule eine neue Regel anlegen.
Füllen Sie hier lediglich den ersten Kasten mit der Überschrift Rule Properties:
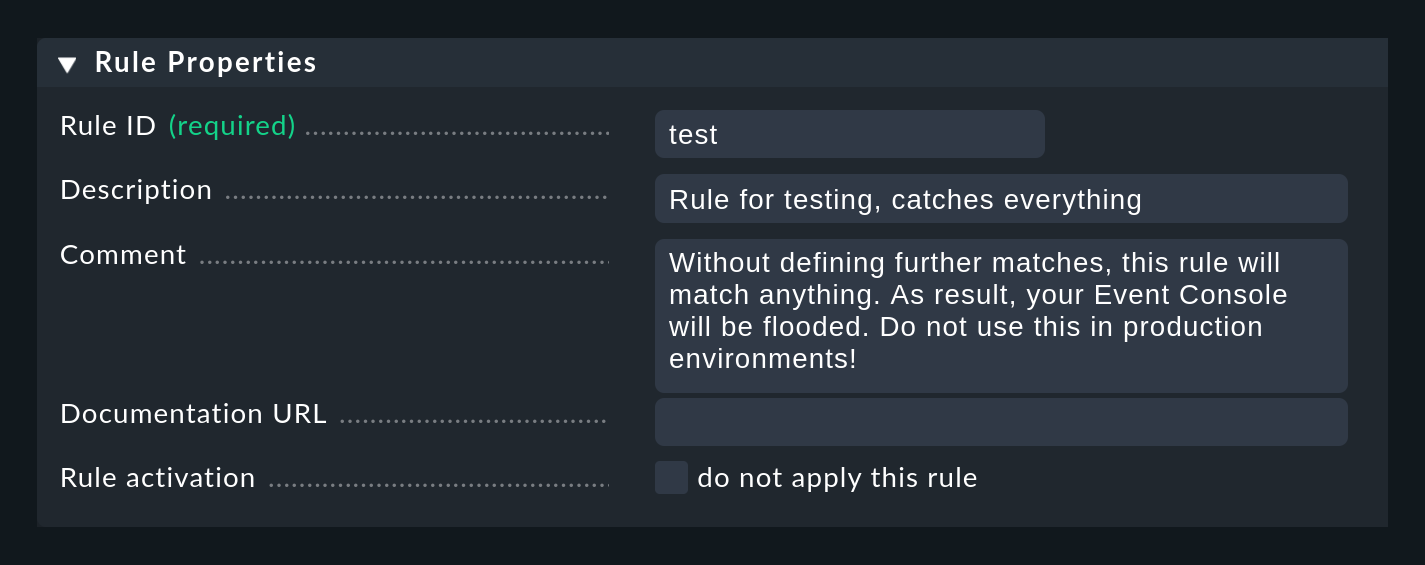
Einzig notwendig ist eine eindeutige Rule ID. Diese ID werden Sie später auch in Log-Dateien finden, und sie wird bei den erzeugten Events mit gespeichert. Es ist also nützlich, die IDs systematisch zu vergeben. Alle weiteren Kästen sind optional. Das gilt insbesondere für die Bedingungen.
Wichtig: Die neue Regel ist erst einmal nur zum Testen und greift vorerst auf jedes Ereignis. Daher ist es auch wichtig, dass Sie diese später wieder entfernen oder zumindest deaktivieren! Andernfalls wird ihre Event Console mit jeder nur erdenklichen unnützen Meldung geflutet und so ziemlich nutzlos werden.
Aktivieren der Änderungen
Wie immer in Checkmk, müssen Sie zuerst Änderungen aktivieren, damit diese wirksam werden. Das ist nicht von Nachteil: Denn so können Sie bei Änderungen, die mehrere zusammengehörige Regeln betreffen, genau festlegen, wann diese „live“ gehen sollen. Und Sie können mit dem Event Simulator zuvor testen, ob alles passt.
Klicken Sie zuerst rechts oben auf der Seite auf die Zahl der aufgelaufenen Änderungen.
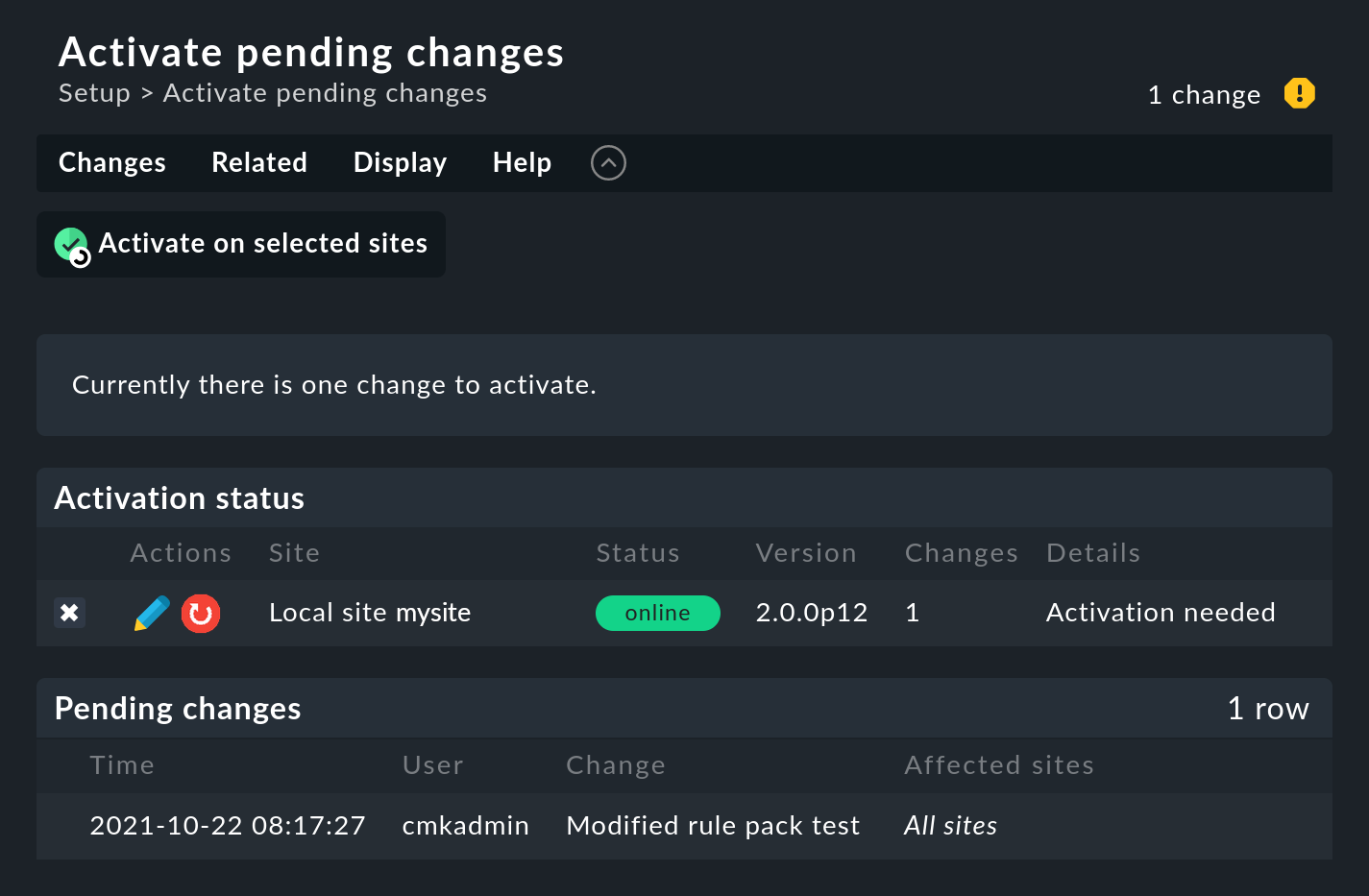
Klicken Sie anschließend auf Activate on selected sites um die Änderung zu aktivieren. Die Event Console ist so konstruiert, dass diese Aktion absolut unterbrechungsfrei abläuft. Der Empfang von eingehenden Meldungen wird zu jeder Zeit sichergestellt, so dass durch den Prozess keine Meldungen verlorengehen können.
Das Aktivieren von Änderungen in der EC ist nur Administratoren erlaubt. Gesteuert wird das über die Berechtigung Activate changes for event console.
Ausprobieren der neuen Regel
Für das Testen könnten Sie jetzt natürlich Meldungen per Syslog oder SNMP senden. Das sollten Sie später auch tun. Für einen ersten Test ist aber der in der EC eingebaute Event Simulator praktischer:
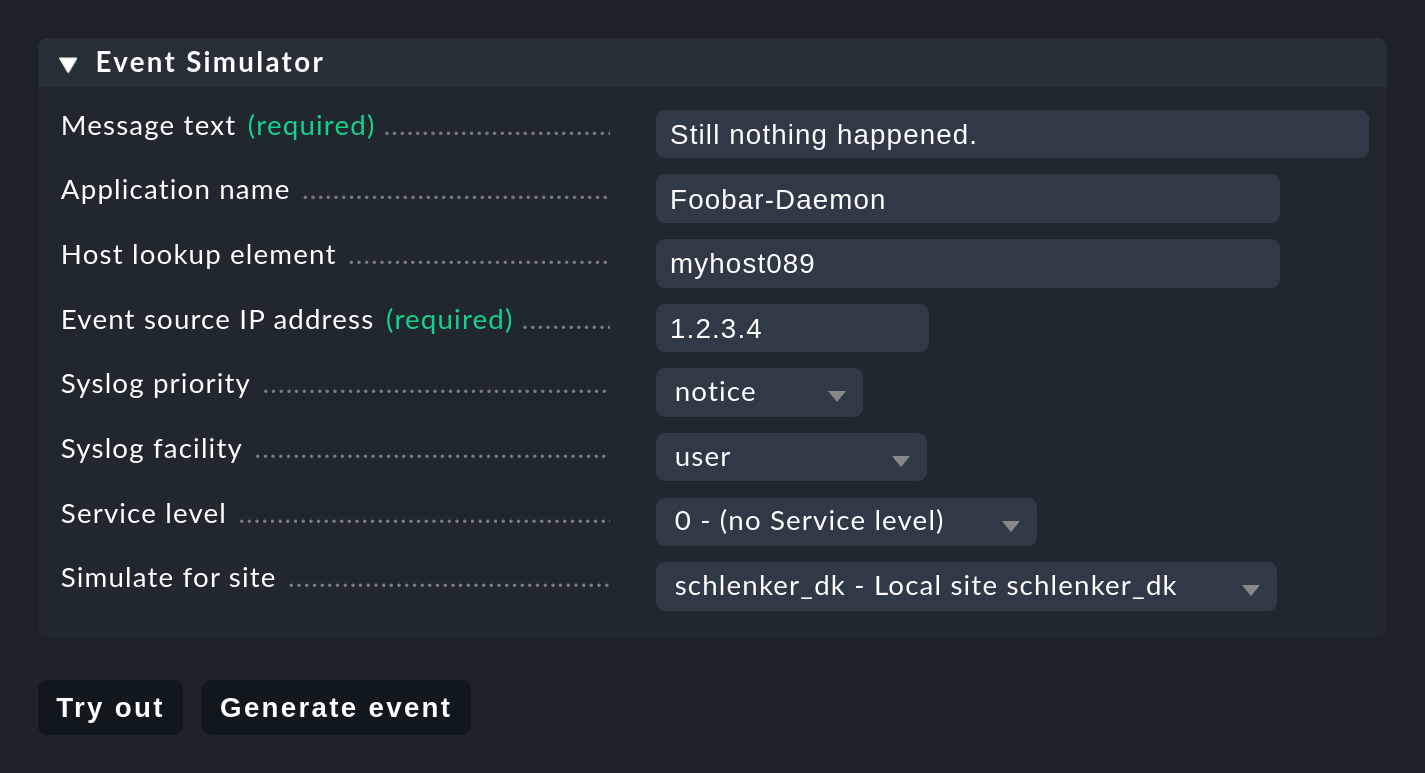
Hier haben Sie zwei Möglichkeiten: Try out berechnet anhand der simulierten Meldung, welche der Regeln matchen würden. Befinden Sie sich in der obersten Ebene der Setup-GUI für die EC, so werden die Regelpakete markiert. Befinden Sie sich innerhalb eines Regelpakets, so werden die einzelnen Regeln markiert. Jedes Paket bzw. jede Regel wird mit einem der folgenden drei Symbole gekennzeichnet:
|
Diese Regel ist die erste, die auf die Meldung greift und legt folglich deren Schicksal fest. |
|
Diese Regel würde zwar greifen, aber die Meldung wurde schon von einer früheren Regel bearbeitet. |
|
Diese Regel greift nicht. Sehr praktisch: Wenn Sie mit der Maus über die graue Kugel fahren, bekommen Sie eine Erklärung, aus welchem Grund die Regel nicht greift. |
Ein Klick auf Generate event macht fast das Gleiche wie Try out, nur wird jetzt die Meldung tatsächlich erzeugt. Eventuell definierte Aktionen werden tatsächlich ausgeführt. Und das Event taucht dann auch in den offenen Events im Monitoring auf. Den Quelltext der erzeugten Meldung sehen Sie in der Bestätigung:

Das so erzeugte Event taucht im Monitor-Menü unter Event Console > Events auf:

Meldungen testweise von Hand erzeugen
Für einen ersten echten Test über das Netzwerk können Sie sehr einfach von einem anderen Linux-Rechner aus per Hand eine Syslog-Meldung versenden.
Da das Protokoll so einfach ist, brauchen Sie dafür nicht einmal ein spezielles Programm, sondern können die Daten einfach per netcat oder nc via UDP versenden.
Der Inhalt des UDP-Pakets besteht aus einer Zeile Text.
Wenn diese einem bestimmten Aufbau entspricht, werden die Bestandteile von der Event Console sauber zerlegt:
user@host:~$ echo '<78>Dec 18 10:40:00 myserver123 MyApplication: It happened again.' | nc -w 0 -u 10.1.1.94 514Sie können aber auch einfach irgendetwas senden. Die EC wird das dann trotzdem annehmen und einfach als Meldungstext auswerten. Zusatzinformation wie z.B. die Anwendung, die Priorität etc. fehlen dann natürlich. Als Status wird zur Sicherheit CRIT angenommen:
user@host:~$ echo 'This is no syslog message' | nc -w 0 -u 10.1.1.94 514Innerhalb der Checkmk Instanz, auf der die EC läuft, gibt es eine named Pipe, in die Sie Textmeldungen lokal per echo schreiben können.
Dies ist eine sehr einfache Methode, um eine lokale Anwendung anzubinden und ebenfalls eine Möglichkeit, das Verarbeiten von Meldungen zu testen:
OMD[mysite]:~$ echo 'Local application says hello' > tmp/run/mkeventd/eventsAuch hier ist es übrigens möglich, im Syslog-Format zu senden, damit alle Felder des Events sauber befüllt werden.
3.3. Einstellungen der Event Console
Die Event Console hat ihre eigenen globalen Einstellungen, welche Sie nicht bei denen der anderen Module finden, sondern unter Setup > Events > Event Console mit dem Knopf Settings.
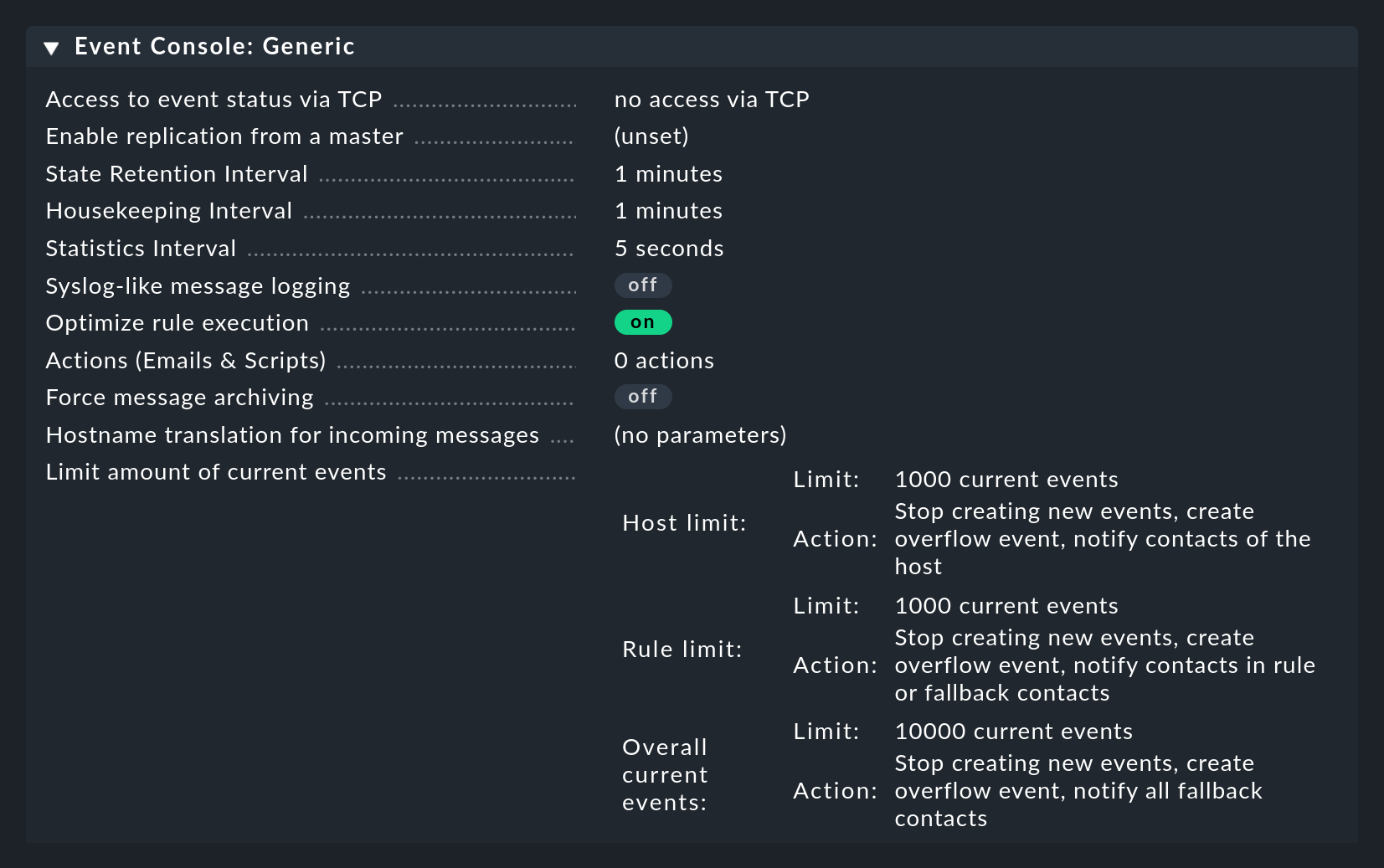
Die Bedeutung der einzelnen Einstellungen erfahren Sie wie immer aus der Inline-Hilfe und an den jeweils passenden Stellen in diesem Artikel.
Der Zugriff auf die Einstellungen ist über die Berechtigung Configuration of Event Console geschützt, welche per Default nur in der Rolle admin enthalten ist.
3.4. Berechtigungen
Auch bei den Rollen und Berechtigungen hat die Event Console einen eigenen Abschnitt:
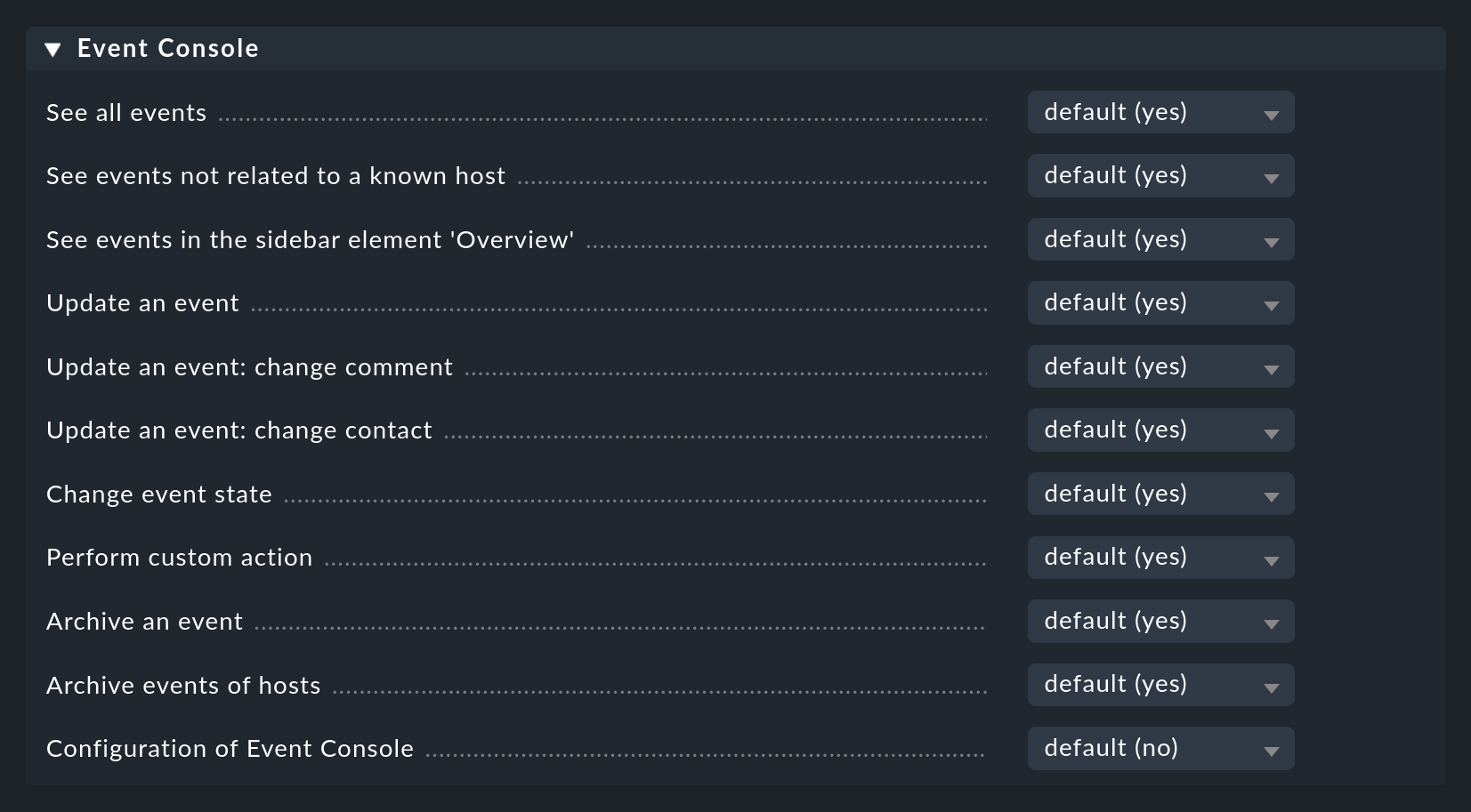
Auf einige der Berechtigungen werden wir an passenden Stellen im Artikel näher eingehen.
3.5. Host-Zuordnung in der Event Console
Eine Besonderheit der Event Console ist, dass im Gegensatz zum statusbasierten Monitoring nicht Hosts im Zentrum stehen: Events können ohne explizite Host-Zuordnung auftreten, was oft sogar gewünscht ist. Allerdings sollte bei Hosts, die sich bereits im aktiven Monitoring befinden, eine leichte Zuordnung möglich sein, um im Monitoring bei Auftreten eines Events schnell zur Statusübersicht zu gelangen. Spätestens, wenn aus Events Zustände werden sollen, ist die korrekte Zuordnung zwingend.
Grundsätzlich gilt bei per Syslog empfangenen Meldungen, dass der in der Meldung verwendete Host-Name dem Host-Namen im Monitoring entsprechen sollte.
Dies erreichen Sie durch Verwendung des fully qualified domain name (FQDN) / fully qualified host name (FQHN) sowohl in Ihrer Syslog-Konfiguration als auch in der Benennung der Hosts in Checkmk.
In Rsyslog erreichen Sie dies über die globale Direktive $PreserveFQDN on.
Checkmk versucht die Host-Namen aus den Events denen aus dem aktiven Monitoring so gut es geht automatisch zuzuordnen. Neben dem Host-Namen wird auch der Host-Alias ausprobiert. Steht hier der per Syslog übertragene Kurzname, erfolgt die Zuordnung korrekt.
Eine Rückwärtsauflösung der IP-Adresse wäre hier wenig sinnvoll, da häufig zwischengeschaltete Log-Server genutzt werden. Ist die Umstellung der Host-Namen auf FQDN/FQHN oder das Nachtragen vieler Aliase zu aufwendig, können Sie in den Einstellungen der Event Console mit Hostname translation for incoming messages Host-Namen bereits direkt beim Empfang von Meldungen umschreiben. Dabei haben Sie zahlreiche Möglichkeiten:
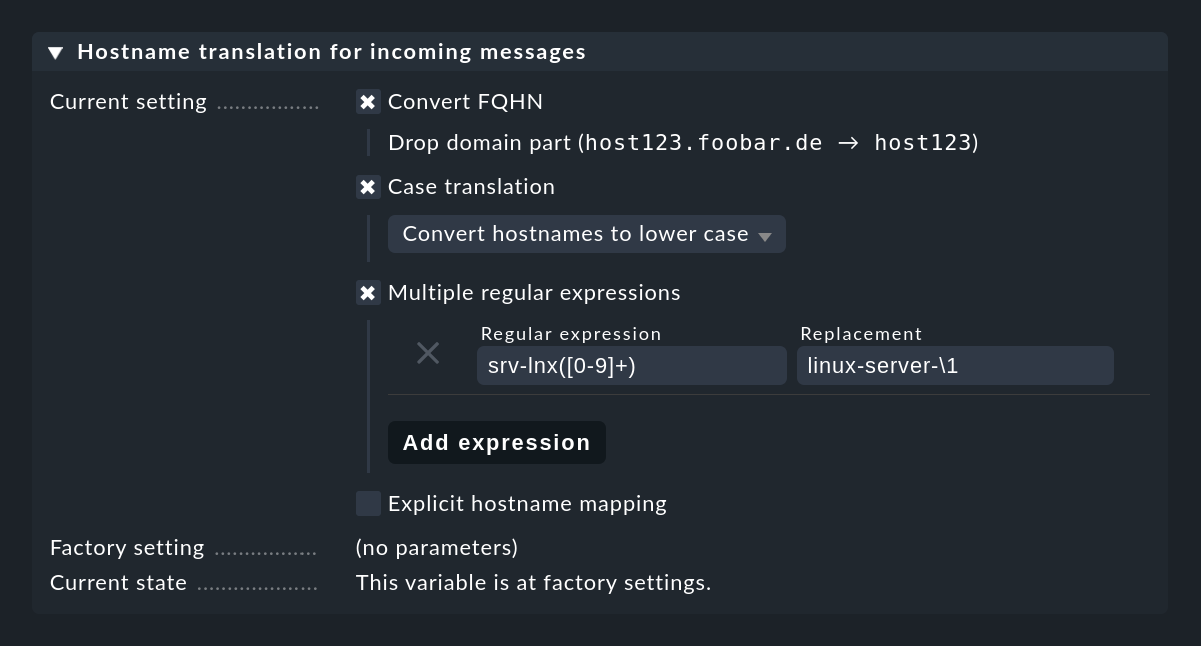
Am flexibelsten ist die Arbeit mit regulären Ausdrücken, welche intelligentes Suchen und Ersetzen in den Host-Namen erlauben.
Insbesondere, wenn zwar Host-Namen eineindeutig sind, aber nur der in Checkmk mitverwendete Domain-Teil fehlt, hilft eine simple Regel: (.*) wird zu \1.mydomain.test.
In Fällen, wo das alles nicht genügt, können Sie noch mit Explicit hostname mapping eine Tabelle von einzelnen Namen und deren jeweiliger Übersetzung angeben.
Wichtig: Die Namensumwandlung geschieht bereits vor dem Prüfen der Regelbedingungen und somit lange vor einem möglichen Umschreiben des Host-Namens durch die Regelaktion Rewrite hostname beim automatisches Umschreiben von Texten.
Etwas einfacher ist die Zuordnung bei SNMP. Hier wird die IP-Adresse des Senders mit den zwischengespeicherten IP-Adressen der Hosts im Monitoring verglichen, d.h. sobald regelmäßige aktive Checks vorhanden sind, wie Erreichbarkeitsprüfung des Telnet- oder SSH-Ports eines Switches, werden per SNMP versandte Statusmeldungen dieses Gerätes dem korrekten Host zugeordnet werden.
4. Die Event Console im Monitoring
4.1. Event-Ansichten
Von der Event Console erzeugte Events werden analog zu Hosts und Services in der Monitoring-Umgebung angezeigt. Den Einstieg dazu finden Sie im Monitor-Menü unter Event Console > Events:
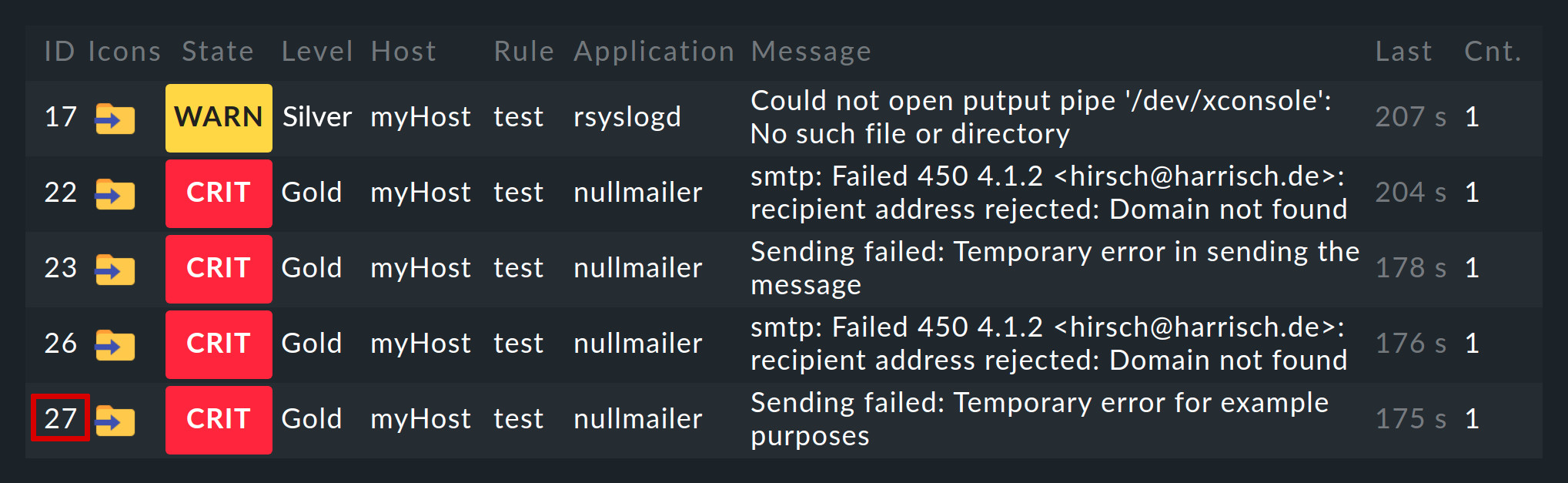
Die angezeigte Ansicht Events können Sie genauso anpassen wie alle anderen. Sie können die angezeigten Events filtern, Kommandos ausführen usw. Einzelheiten erfahren Sie im Artikel über die Ansichten. Wenn Sie neue Event-Ansichten erstellen, stehen Ihnen Events sowie Event-Historie als Datenquellen zur Verfügung.
Ein Klick auf die ID des Events (hier z.B. 27) bringt Sie zu dessen Details:
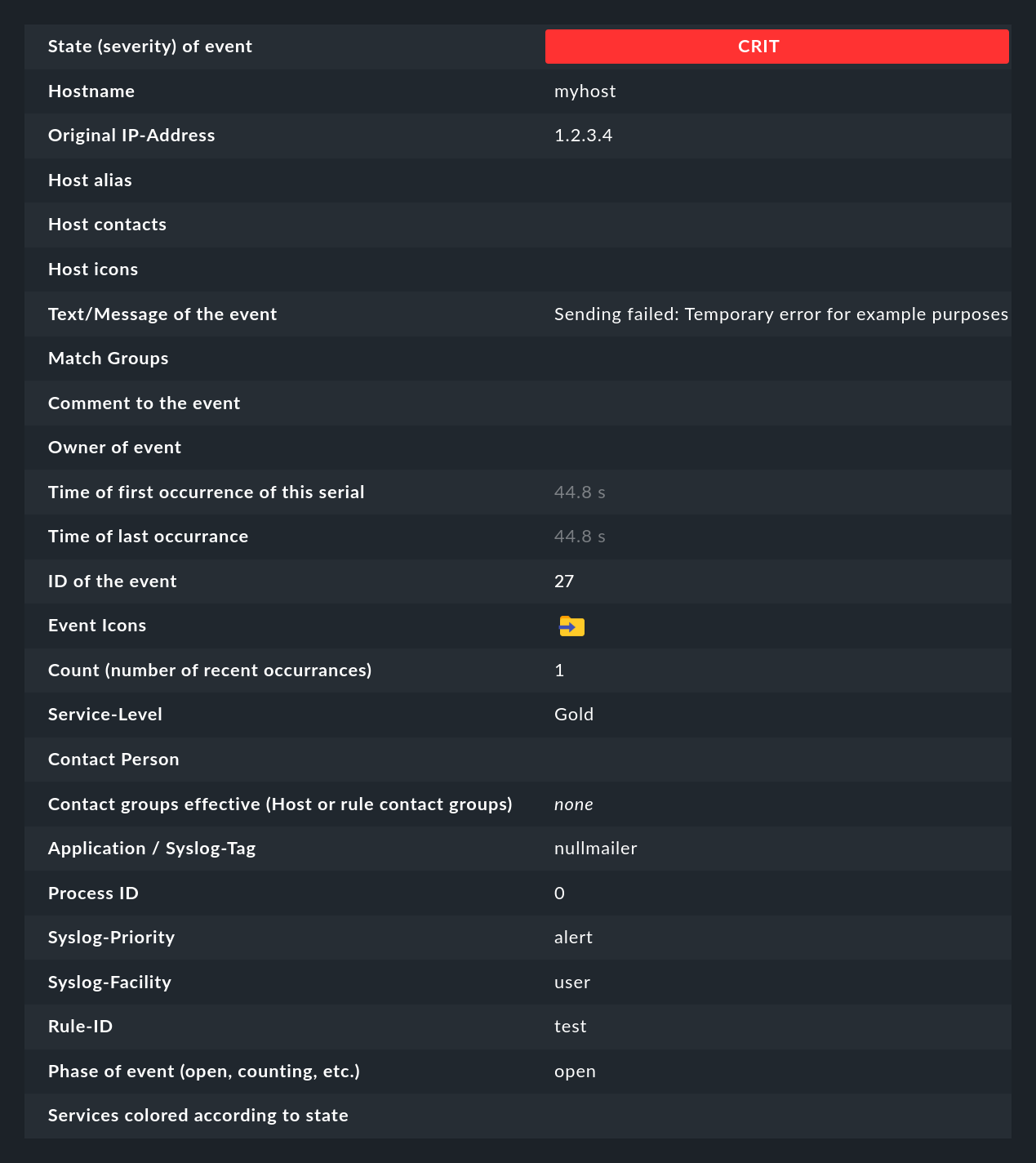
Wie Sie sehen können, hat ein Event eine ganze Menge von Datenfeldern, deren Bedeutung wir in diesem Artikel nach und nach erklären werden. Die wichtigsten Felder sollen trotzdem bereits hier kurz erwähnt werden:
| Feld | Bedeutung |
|---|---|
State (severity) of event |
Wie in der Einleitung erwähnt. wird jeder Event als OK, WARN, CRIT oder UNKNOWN eingestuft. Events vom Status OK sind eher ungewöhnlich. Denn die EC ist gerade dafür gedacht, nur die Probleme herauszufiltern. Es gibt aber Situationen, in denen ein OK-Event durchaus Sinn machen kann. |
Text/Message of the event |
Der eigentliche Inhalt des Events: Eine Textmeldung. |
Hostname |
Der Name des Hosts, der die Meldung gesendet hat. Dieser muss nicht unbedingt ein mit Checkmk aktiver überwachter Host sein. Falls ein Host dieses Namens jedoch im Monitoring existiert, stellt die EC automatisch eine Verknüpfung her. In diesem Fall sind dann auch die Felder Host alias, Host contacts und Host icons gefüllt und der Host erscheint in der gleichen Schreibweise wie im aktiven Monitoring. |
Rule-ID |
Die ID der Regel, welche diesen Event erzeugt hat. Ein Klick auf diese ID bringt Sie direkt zu den Details der Regel. Übrigens bleibt die ID auch dann erhalten, wenn die Regel inzwischen nicht mehr existiert. |
Wie eingangs erwähnt, werden Events direkt im Overview der Seitenleiste angezeigt:
Dabei sehen Sie drei Zahlen:
Events — alle offenen und quittierten Events (entspricht der Ansicht Event Console > Events)
Problems — davon nur diejenigen mit dem Zustand WARN / CRIT / UNKNOWN
Unhandled — davon wiederum nur die noch nicht quittierten (dazu gleich mehr)
4.2. Kommandos und Workflow von Events
Analog zu den Hosts und Services wird auch für Events ein einfacher Workflow abgebildet.
Wie gewohnt geschieht das über Kommandos, welche Sie im Menü Commands finden.
Durch Einblenden und Auswahl mit Checkboxen können Sie ein Kommando auf vielen Events gleichzeitig ausführen.
Als Besonderheit gibt es das häufig gebrauchte Archivieren eines einzelnen Events direkt über das Symbol ![]() .
.
Für jedes der Kommandos gibt es eine Berechtigung, über die Sie steuern können, welcher Rolle das Ausführen des Kommandos erlaubt ist.
Per Default sind alle Kommandos für Mitglieder der Rollen admin und user freigeschaltet.
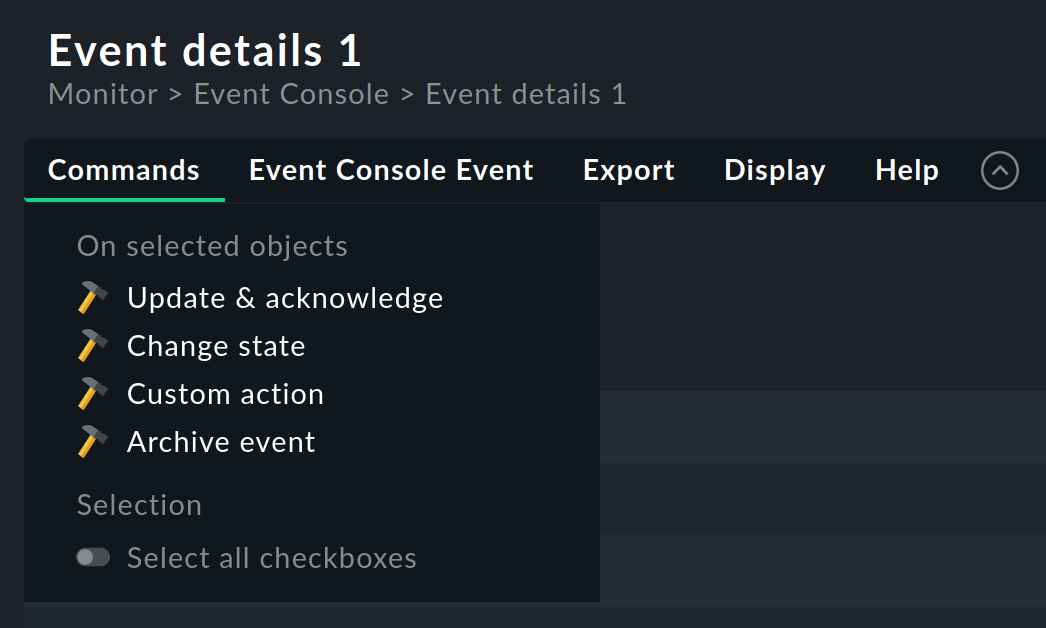
Folgende Kommandos stehen zur Verfügung:
Aktualisieren und quittieren
Das Kommando Update & Acknowledge blendet den folgenden Bereich oberhalb der Event-Liste ein:
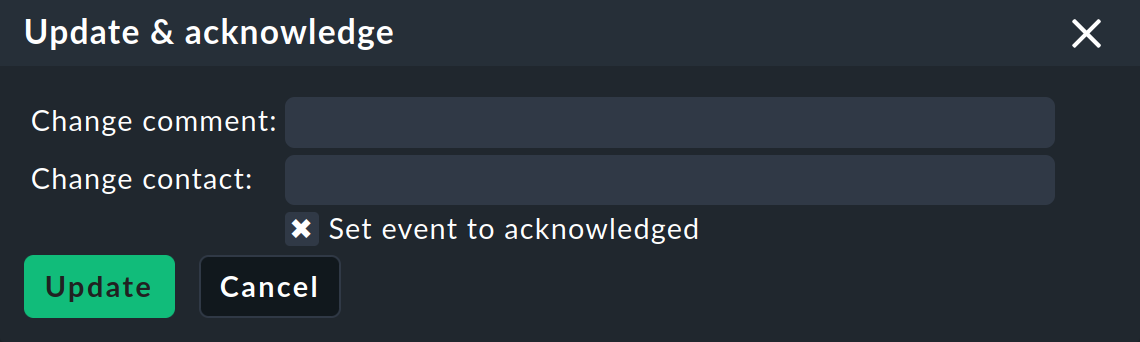
Mit dem Knopf Update können Sie in einem einzigen Arbeitsschritt einen Kommentar an das Event hängen, eine Kontaktperson eintragen und das Event quittieren. Das Feld Change contact ist bewusst Freitext. Hier können Sie auch Dinge wie Telefonnummern eintragen. Das Feld hat insbesondere keinen Einfluss auf die Sichtbarkeit des Events in der GUI. Es ist ein reines Kommentarfeld.
Die Checkbox Set event to acknowledged führt dazu, dass das Event von der Phase open übergeht nach acknowledged und fortan als handled gilt. Dies ist analog zu dem Quittieren von Host-und Service-Problemen.
Ein späteres erneutes Aufrufen des Kommando mit nicht gesetzter Checkbox entfernt die Quittierung wieder.
Zustand ändern
Das Kommando Change State erlaubt den manuellen Zustandswechsel von Events — z.b. von CRIT auf WARN.
Aktionen ausführen
Mit dem Kommando Custom Action können Sie auf Events frei definierbare Aktionen ausführen lassen. Zunächst ist nur die Aktion Send monitoring notification verfügbar. Diese sendet eine Checkmk Benachrichtigung, die genauso behandelt wird wie die von einem aktiv überwachten Service. Diese durchläuft die Benachrichtigungsregeln und führt dann entsprechend zu E-Mails, SMS oder was auch immer Sie konfiguriert haben. Einzelheiten zur Benachrichtigung durch die EC erfahren Sie weiter unten.
Archivieren
Das Kommando Archive Event löscht das Event endgültig aus der Liste der offenen Events. Da alle Aktionen auf Events — inklusive dieses Löschvorgangs — auch im Archiv aufgezeichnet werden, können Sie später immer noch auf alle Informationen des Events zugreifen. Deswegen sprechen wir nicht von Löschen, sondern von Archivieren.
Das Archivieren von einzelnen Events erreichen Sie auch aus der Event-Liste bequem über das Symbol ![]() .
.
4.3. Sichtbarkeit von Events
Problematik der Sichtbarkeit
Für die Sichtbarkeit von Hosts und Services im Monitoring für normale Benutzer werden von Checkmk Kontaktgruppen verwendet. Diese werden per Setup-GUI, Regel oder Ordnerkonfiguration den Hosts und Service zugeordnet.
Nun ist es aber bei der Event Console so, dass so eine Zuordnung von Events zu Kontaktgruppen erst einmal nicht existiert. Denn im Vorhinein ist gar nicht bekannt, welche Meldungen überhaupt empfangen werden können. Nicht einmal die Liste der Hosts ist bekannt, denn die Sockets für Syslog und SNMP sind ja von überall aus erreichbar. Deswegen gibt es bei der Sichtbarkeit in der Event Console ein paar Besonderheiten.
Erst einmal dürfen alle alles sehen
Zunächst einmal gibt es bei der Konfiguration der Benutzerrollen die Berechtigung Event Console > See all events.
Diese ist per Default an, so dass auch normale Benutzer alle Events sehen dürfen!
Dies ist bewusst so eingestellt, damit nicht aufgrund fehlerhafter Konfiguration wichtige Fehlermeldungen unter den Tisch fallen.
Der erste Schritt zu einer genaueren Steuerung der Sichtbarkeit ist also das Entfernen dieser Berechtigung aus der Rolle user.
Zuordnung zu Hosts
Damit die Sichtbarkeit von Events möglichst konsistent mit dem übrigen Monitoring ist, versucht die Event Console so gut wie möglich die Hosts, von denen sie Events empfängt, ihren per Setup-GUI konfigurierten Hosts zuzuordnen. Was einfach klingt ist trickreich im Detail. Denn teils fehlt im Event eine Angabe zum Host-Namen und nur die IP-Adresse ist bekannt. In anderen Fällen hat der Host-Name eine andere Schreibweise als in der Setup-GUI.
Die Zuordnung erfolgt konkret wie folgt:
Ist im Event kein Host-Name bekannt, so wird anstelle dessen seine IP-Adresse als Host-Name verwendet.
Der Host-Name im Event wird dann ohne Berücksichtigung von Groß-/Kleinschreibung mit allen Host-Namen, Host-Aliase und IP-Adressen der Hosts aus dem Monitoring verglichen.
Wird so ein Host gefunden, werden dessen Kontaktgruppen für den Event übernommen, und darüber wird dann die Sichtbarkeit gesteuert.
Wird der Host jedoch nicht gefunden, so werden die Kontaktgruppen — falls dort konfiguriert — aus der Regel übernommen, welche den Event erzeugt hat.
Sind auch dort keine Gruppen hinterlegt, so darf der Benutzer den Event nur dann sehen, wenn er die Berechtigung Event Console > See events not related to a known host hat.
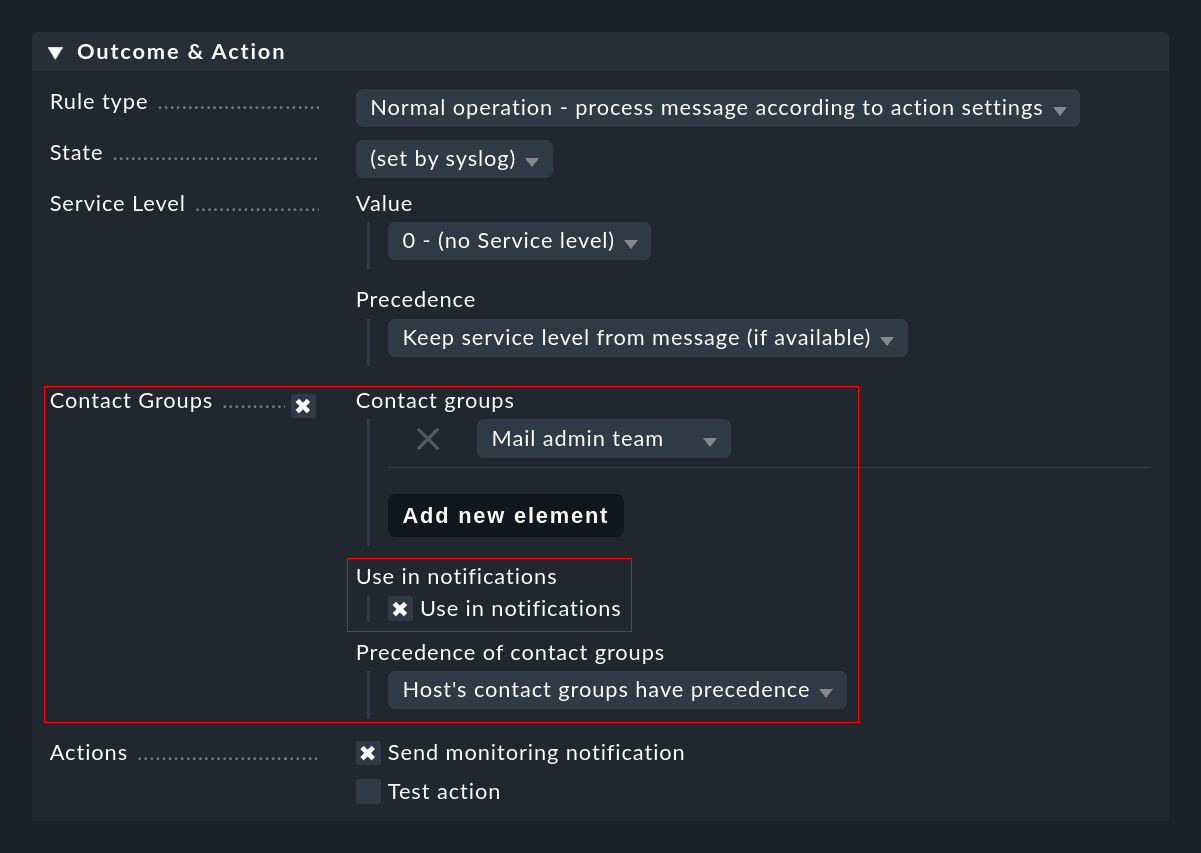
Sie können die Zuordnung an einer Stelle beeinflussen: Falls nämlich in der Regel Kontaktgruppen definiert sind und der Host zugeordnet werden konnte, hat normalerweise die Zuordnung Vorrang. Dies können Sie in einer Regel mit der Option Precedence of contact groups umstellen:
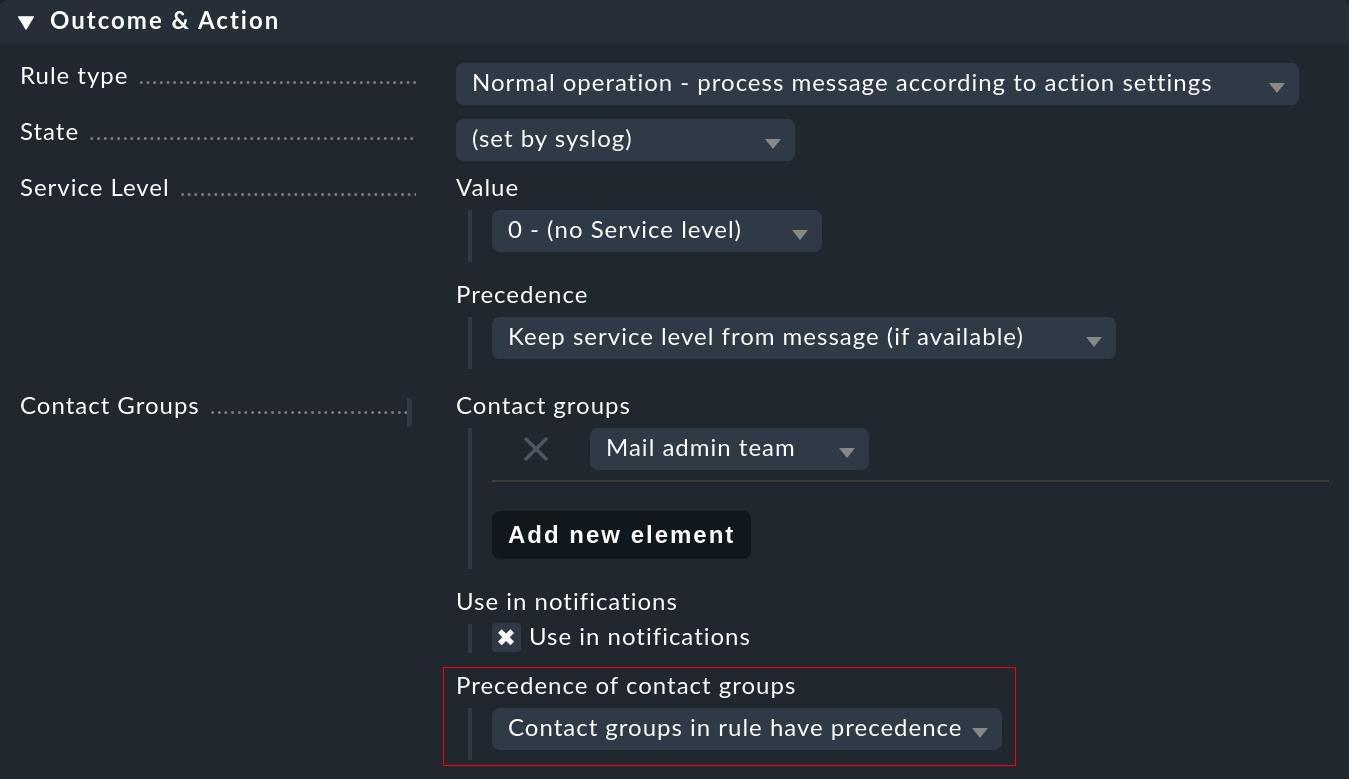
Zudem können Sie direkt in der Regel Einstellungen für die Benachrichtigung vornehmen. Dies ermöglicht es, die Art des Events gegenüber den regulären Zuständigkeiten für einen Host zu priorisieren.
4.4. Fehlersuche
Welche Regel greift wie oft?
Sowohl bei den Regelpaketen …
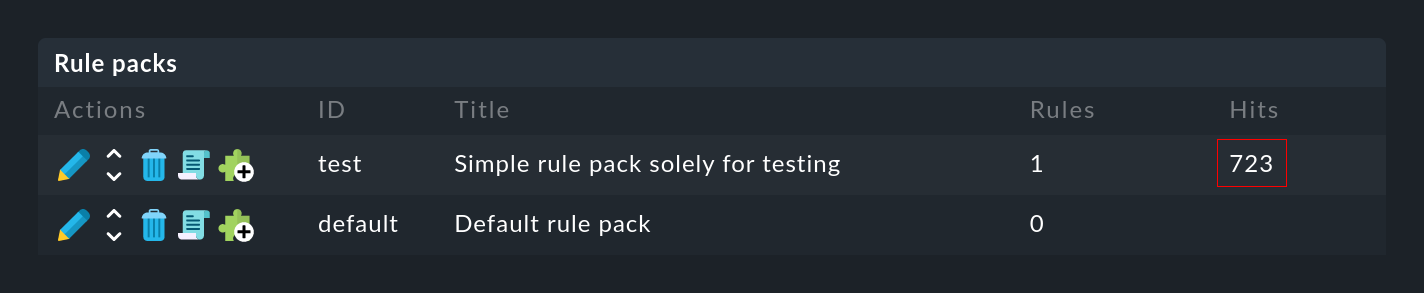
… als auch bei den einzelnen Regeln …

… finden Sie in der Spalte Hits die Angabe, wie oft das Paket bzw. die Regel schon auf eine Meldung gepasst hat. Dies hilft Ihnen zum einen dabei, unwirksame Regeln zu eliminieren oder zu reparieren. Aber auch bei Regeln, die sehr oft matchen, kann dies interessant sein. Für die optimale Performance der EC sollten diese möglichst am Anfang der Regelkette stehen. So können Sie die Anzahl von Regeln reduzieren, die die EC bei jeder Meldung ausprobieren muss.
Die Zählerstände können Sie jederzeit mit dem Menüpunkt Event Console > Reset counters zurücksetzen.
Regelauswertung debuggen
Beim Ausprobieren einer Regel haben Sie schon gesehen, wie Sie mit dem Event Simulator die Auswertungen Ihrer Regeln prüfen können. Ähnliche Informationen bekommen Sie zur Laufzeit für alle Meldungen, wenn Sie in den Einstellungen der Event Console den Wert von Debug rule execution auf on umstellen.
Die Log-Datei der Event Console finden Sie unter var/log/mkeventd.log.
Für jede Regel, die geprüft wird, aber nicht greift, erfahren Sie den genauen Grund:
[1481020022.001612] Processing message from ('10.40.21.11', 57123): '<22>Dec 6 11:27:02 myserver123 exim[1468]: Delivery complete, 4 message(s) remain.'
[1481020022.001664] Parsed message:
application: exim
facility: 2
host: myserver123
ipaddress: 10.40.21.11
pid: 1468
priority: 6
text: Delivery complete, 4 message(s) remain.
time: 1481020022.0
[1481020022.001679] Trying rule test/myrule01...
[1481020022.001688] Text: Delivery complete, 4 message(s) remain.
[1481020022.001698] Syslog: 2.6
[1481020022.001705] Host: myserver123
[1481020022.001725] did not match because of wrong application 'exim' (need 'security')
[1481020022.001733] Trying rule test/myrule02n...
[1481020022.001739] Text: Delivery complete, 4 message(s) remain.
[1481020022.001746] Syslog: 2.6
[1481020022.001751] Host: myserver123
[1481020022.001764] did not match because of wrong textEs versteht sich wohl von selbst, dass Sie dieses intensive Logging nur bei Bedarf und mit Bedacht verwenden sollten. Bei einer nur etwas komplexeren Umgebung werden Unmengen von Daten erzeugt!
5. Die ganze Mächtigkeit der Regeln
5.1. Die Bedingung
Der wichtigste Teil einer EC-Regel ist die Bedingung (Matching Criteria). Nur wenn eine Meldung alle in der Regel hinterlegten Bedingungen erfüllt, werden die in der Regel definierten Aktionen ausgeführt und die Auswertung der Meldung damit abgeschlossen.
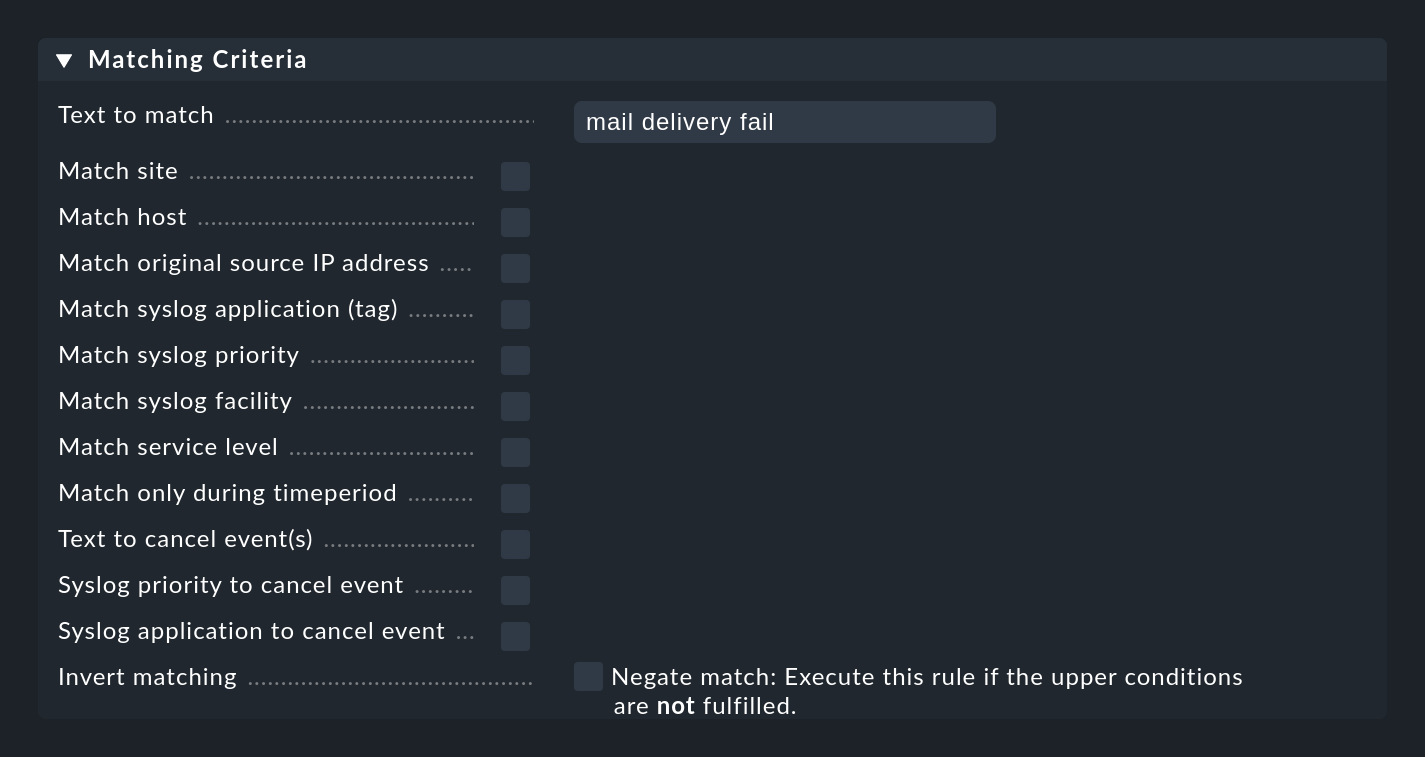
Allgemeines zu Textvergleichen
Bei allen Bedingungen, die Textfelder betreffen, wird der Vergleichstext grundsätzlich als regulärer Ausdruck behandelt. Der Vergleich findet hier immer ohne Unterscheidung von Groß-/Kleinschreibung statt. Letzteres ist eine Ausnahme von Checkmk Konventionen in anderen Modulen. Es macht aber das Formulieren der Regeln robuster. Auch sind gerade Host-Namen in Events nicht unbedingt konsistent in ihrer Schreibweise, falls diese nicht zentral, sondern auf jedem Host selbst konfiguriert werden. Daher ist diese Ausnahme hier sehr sinnvoll.
Ferner gilt immer ein Infix-Match — also eine Überprüfung auf ein Enthaltensein des Suchtextes.
Ein .* am Anfang oder am Ende des Suchtexts können Sie sich also sparen.
Davon gibt es allerdings eine Ausnahme: Wird beim Match auf den Host-Namen kein regulärer Ausdruck verwendet, sondern ein fester Host-Name, so wird dieser auf exaktes Übereinstimmen geprüft und nicht auf ein Enthaltensein.
Achtung: Sobald der Suchtext einen Punkt enthält, wird dieser als regulärer Ausdruck gewertet und es gilt die Infix-Suche.
myhost.de matcht dann auch z.B. auf notmyhostide!
Match-Gruppen
Sehr wichtig und nützlich ist hier das Konzept Match-Gruppen beim Feld Text to match. Damit sind die Textabschnitte gemeint, die beim Matchen mit geklammerten Ausdrücken im regulären Ausdruck übereinstimmen.
Nehmen Sie an, Sie möchten folgende Art von Meldung in der Log-Datei einer Datenbank überwachen:
Database instance WP41 has failedDas WP41 ist dabei natürlich variabel und Sie möchten sicher nicht für jede unterschiedliche Instanz ein eigene Regel formulieren.
Daher verwenden Sie im regulären Ausdruck .*, was für eine beliebige Zeichenfolge steht:
Database instance .* has failed
Wenn Sie jetzt den variablen Teil in runde Klammern setzen, wird sich die Event Console den tatsächlichen Wert beim Matchen für weitere Aktionen merken (capturing):
Database instance (.*) has failed
Nach einem erfolgreichen Match der Regel ist jetzt die erste Match-Gruppe auf den Wert WP41 gesetzt (oder welche Instanz auch immer den Fehler produziert hat).
Diese Match-Gruppen können Sie im Event Simulator sehen, wenn Sie mit der Maus über die grüne Kugel fahren:

Auch in den Details des erzeugten Events können Sie die Gruppen sehen:
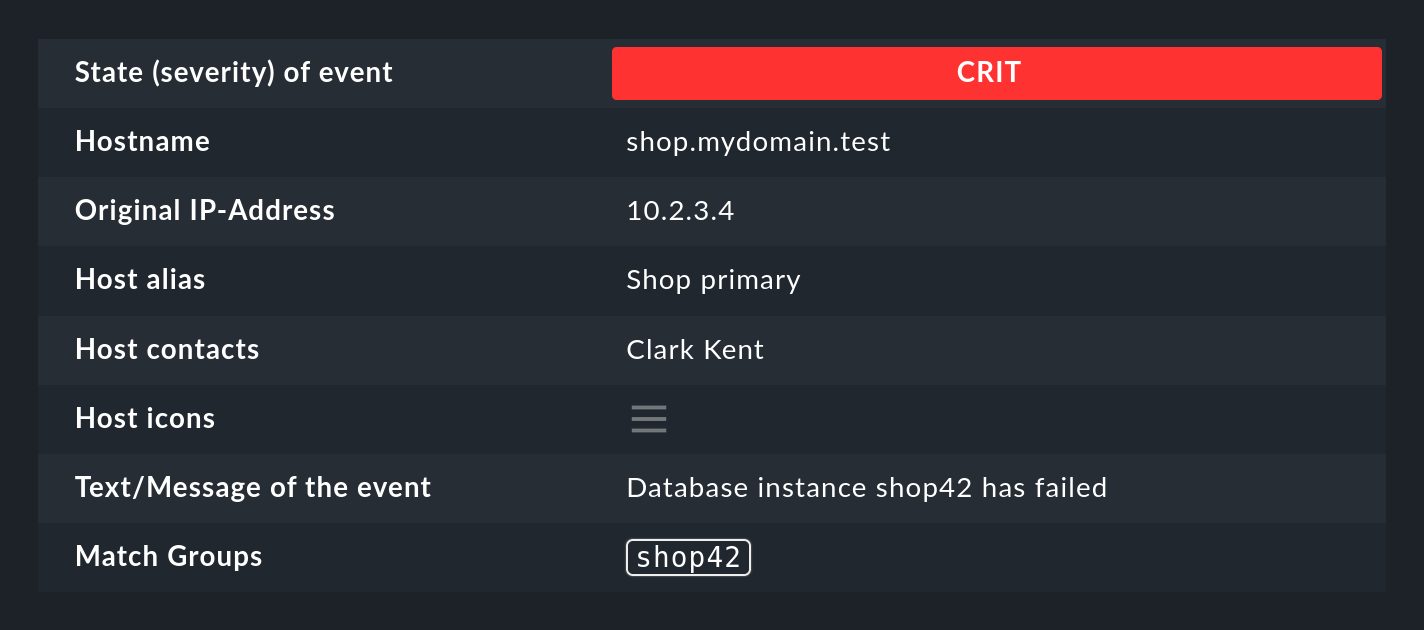
Die Match-Gruppen finden unter anderem Anwendung bei:
An dieser Stelle noch ein Tipp:
Es gibt Situationen, in denen Sie im regulären Ausdruck etwas gruppieren müssen, aber keine Match-Gruppe erzeugen möchten.
Dies können Sie durch ein ?: direkt nach der öffnenden Klammer erreichen.
Beispiel: Der Ausdruck one (.*) two (?:.*) three erzeugt bei einem Match auf one 123 two 456 three nur die eine Match-Gruppe 123.
IP-Adresse
Im Feld Match original source IP address können Sie auf die IPv4-Adresse des Senders der Meldung matchen.
Geben Sie entweder eine exakte Adresse an oder ein Netzwerk in der Notation X.X.X.X/Y, also z.B. 192.168.8.0/24, um alle Adressen im Netzwerk 192.168.8.X zu matchen.
Beachten Sie, dass der Match auf die IP-Adresse nur dann funktioniert, wenn die überwachten Systeme direkt an die Event Console senden. Ist noch ein anderer Syslog-Server dazwischen geschaltet, der die Meldungen weiterleitet, wird stattdessen dessen Adresse als Absender in der Meldung erscheinen.
Syslog-Priorität und -Facility
Die Felder Match syslog priority und Match syslog facility sind ursprünglich von Syslog definierte, standardisierte Informationen. Intern wird dabei ein 8-Bit-Feld in 5 Bits für die Facility (ergibt 32 Möglichkeiten) und 3 Bits für die Priorität (8 Möglichkeiten) aufgeteilt.
Die 32 vordefinierten Facilities waren mal für so etwas wie eine Anwendung gedacht.
Nur ist die Auswahl damals nicht sehr zukunftsweisend gemacht worden.
Eine der Facilities ist z.B. uucp — ein Protokoll das schon in den 90er Jahren des vergangenen Jahrtausends kaum noch verwendet wurde.
Fakt ist aber, dass jede Meldung, die per Syslog kommt, eine der Facilities trägt. Teilweise können Sie diese beim Senden auch frei vergeben, um später darauf gezielt zu filtern. Das ist durchaus nützlich.
Die Verwendung von Facility und Priorität hat auch einen Performance-Aspekt. Wenn Sie eine Regel definieren, die sowieso nur auf Meldungen greift, die alle die gleiche Facility oder Priorität haben, sollten Sie diese zusätzlich in den Filtern der Regel setzen. Die Event Console kann diese Regeln dann sehr effizient sofort umgehen, wenn eine Meldung mit abweichenden Werten eingeht. Je mehr Regeln diese Filter gesetzt haben, desto weniger Regelvergleiche werden benötigt.
Invertieren des Matches
Die Checkbox Negate match: Execute this rule if the upper conditions are not fulfilled. führt dazu, dass die Regel genau dann greift, wenn die Bedingungen nicht alle erfüllt sind. Dies ist eigentlich nur nützlich im Zusammenhang mit zwei Regelarten (Rule type im Kasten Outcome & Action der Regel):
Do not perform any action, drop this message, stop processing
Skip this rule pack, continue rule execution with next pack
Zu den Regelpaketen erfahren Sie weiter unten mehr.
5.2. Auswirkung der Regel
Regeltyp: Abbrechen oder Event erzeugen
Wenn eine Regel matcht, legt sie fest, was mit der Meldung geschehen soll. Das geschieht im Kasten Outcome & Action:
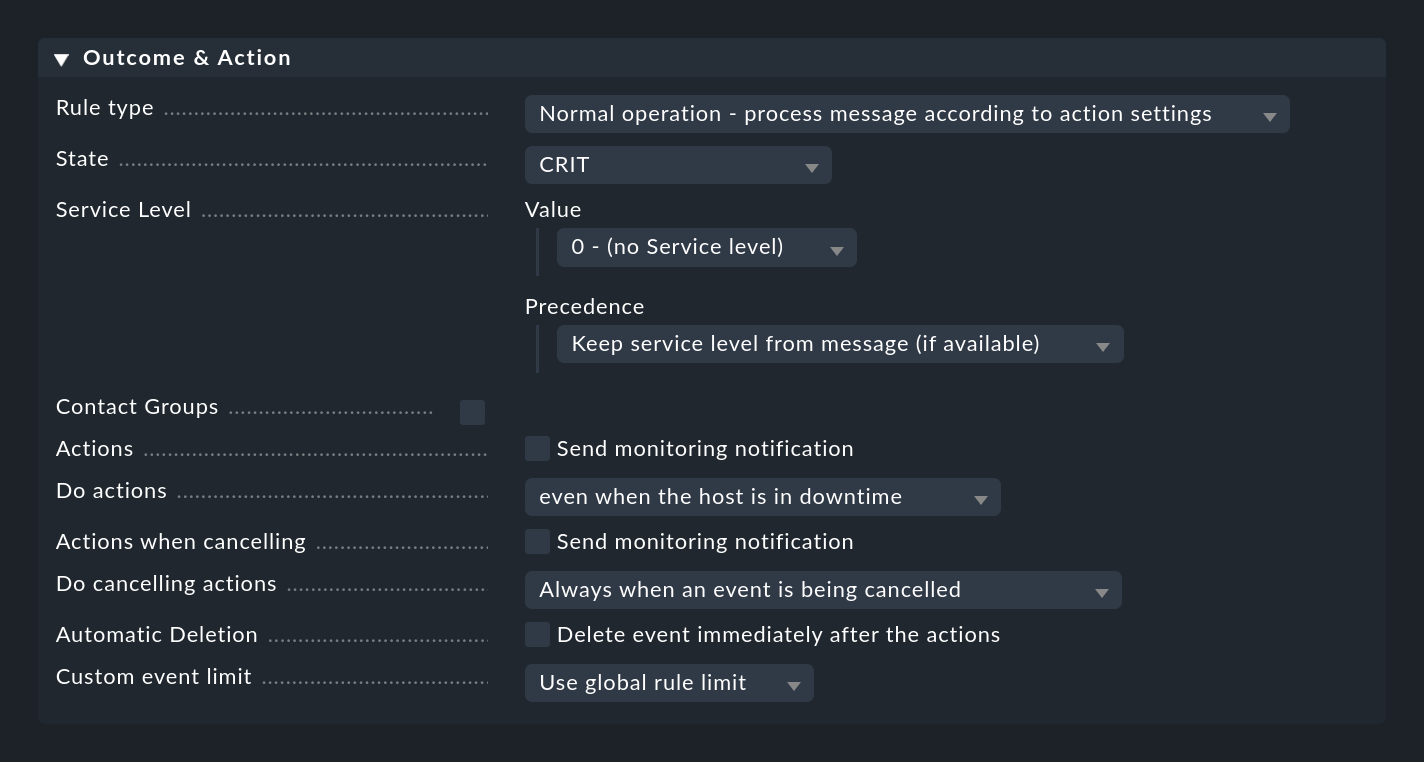
Mit dem Rule type kann die Auswertung an der Stelle ganz oder für das aktuelle Regelpaket abgebrochen werden. Gerade die erste Möglichkeit sollten Sie nutzen, um den größten Teil des nutzlosen „Rauschens“ durch ein paar gezielte Regeln ganz am Anfang loszuwerden. Nur bei den „normalen“ Regeln werden die anderen Optionen in diesem Kasten überhaupt ausgewertet.
Festlegen des Status
Mit State legt die Regel den Monitoring-Status des Events fest. In der Regel wird diese WARN oder CRIT sein. Regeln, die OK-Events erzeugen, können in Ausnahmen interessant sein, um bestimmte Ereignisse rein informativ darzustellen. Hier ist dann eine Kombination mit einem automatischen Herausaltern dieser Events interessant.
Neben dem Festlegen eines expliziten Status gibt es noch zwei dynamischere Möglichkeiten. Die Einstellung (set by syslog) übernimmt die Einstufung anhand der Syslog-Priorität. Dies funktioniert allerdings nur, wenn die Meldung bereits vom Absender nutzbar klassifiziert wurde. Meldungen, die direkt per Syslog empfangen wurden, enthalten eine von acht per RFC festgelegten Prioritäten, die wie folgt abgebildet werden:
| Priorität | ID | Zustand | Definition laut Syslog |
|---|---|---|---|
|
0 |
CRIT |
Das System ist unbrauchbar |
|
1 |
CRIT |
Sofortige Aktion erforderlich |
|
2 |
CRIT |
Kritischer Zustand |
|
3 |
CRIT |
Fehler |
|
4 |
WARN |
Warnung |
|
5 |
OK |
Normal, aber signifikante Information |
|
6 |
OK |
Reine Information |
|
7 |
OK |
Debug-Meldung |
Neben Syslog-Meldungen bieten auch Meldungen aus dem Windows Event Log und Meldungen aus Textdateien, die bereits mit dem Checkmk Plugin Logwatch auf dem Zielsystem klassifiziert wurden, vorbereitete Zustände. Bei SNMP-Traps gibt es diese leider nicht.
Eine ganze andere Methode ist, die Einstufung der Meldung anhand des Texts selbst zu machen. Dies geht mit der Einstellung (set by message text):
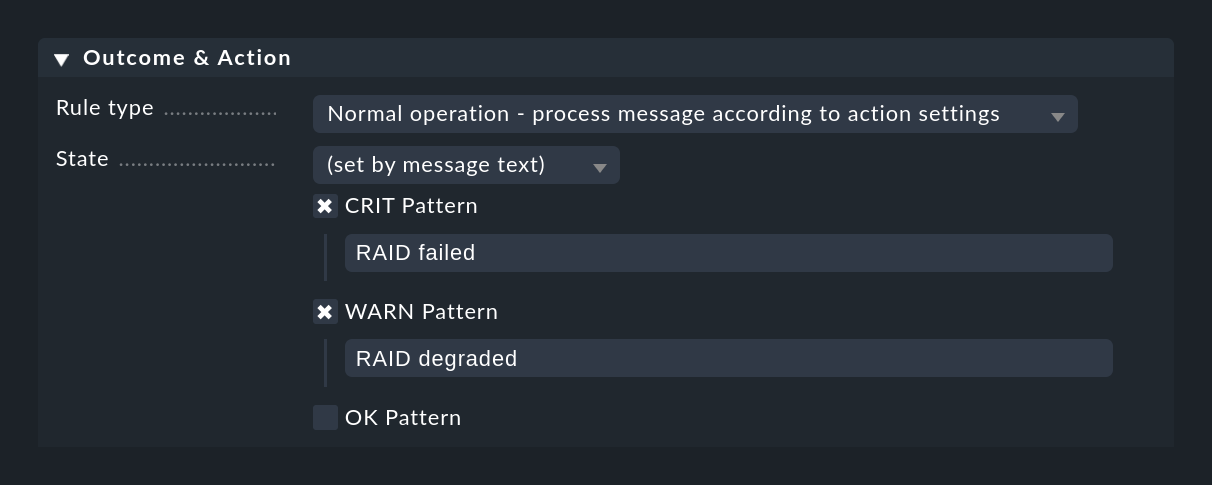
Der Match auf die hier konfigurierten Texte geschieht erst, nachdem auf Text to match und auf die anderen Regelbedingungen geprüft wurde. Diese müssen Sie also hier nicht wiederholen.
Falls keines der konfigurierten Patterns gefunden wird, nimmt das Event den Zustand UNKNOWN an.
Service-Level
Hinter dem Feld Service Level steckt die Idee, dass jeder Host und jeder Service im Unternehmen eine bestimmte Wichtigkeit hat. Damit kann eine konkrete Service-Vereinbarung verbunden sein. In Checkmk können Sie per Regeln Ihren Hosts und Services solche Level zuordnen und dann z.B. die Benachrichtigung oder selbst definierte Dashboards davon abhängig machen.
Da Events erst einmal nicht unbedingt mit Hosts oder Services korrelieren, erlaubt die Event Console, dass Sie einem Event per Regel ebenfalls einen Service-Level zuordnen. Sie können die Event-Ansichten dann später nach diesem Level filtern.
Ab Werk definiert Checkmk die vier Level 0 (kein Level), 10 (Silber), 20 (Gold) und 30 (Platin). Diese Auswahl können Sie in den Global settings > Notifications > Service Levels beliebig anpassen. Entscheidend sind hierbei die Zahlen der Levels, dann nach diesen werden sie sortiert und auch nach der Wichtigkeit verglichen.
Kontaktgruppen
Die Kontaktgruppen für die Sichtbarkeit werden auch bei der Benachrichtigung von Events verwendet. Sie können hier per Regel Events explizit Kontaktgruppen zuordnen. Einzelheiten erfahren Sie im Kapitel über das Monitoring.
Aktionen
Aktionen sind den Alert Handlers für Hosts und Services sehr ähnlich. Hier können Sie beim Öffnen eines Events ein selbst definiertes Skript ausführen lassen. Alle Einzelheiten zu den Aktionen erfahren Sie weiter unten in einem eigenen Abschnitt.
Automatisches Löschen (Archivieren)
Das automatische Löschen (= Archivieren), welches Sie mit Delete event immediately after the actions einstellen können, sorgt letztlich dafür, dass ein Event im Monitoring überhaupt nicht sichtbar wird. Das ist dann sinnvoll, wenn Sie lediglich automatisch Aktionen auslösen oder nur bestimmte Events archivieren möchten, damit Sie später danach recherchieren können.
5.3. Automatisches Umschreiben von Texten (Rewriting)
Mit dem Rewriting kann eine EC-Regel Textfelder in der Meldung automatisch umschreiben und Anmerkungen anfügen. Dies wird in einem eigenen Kasten konfiguriert:
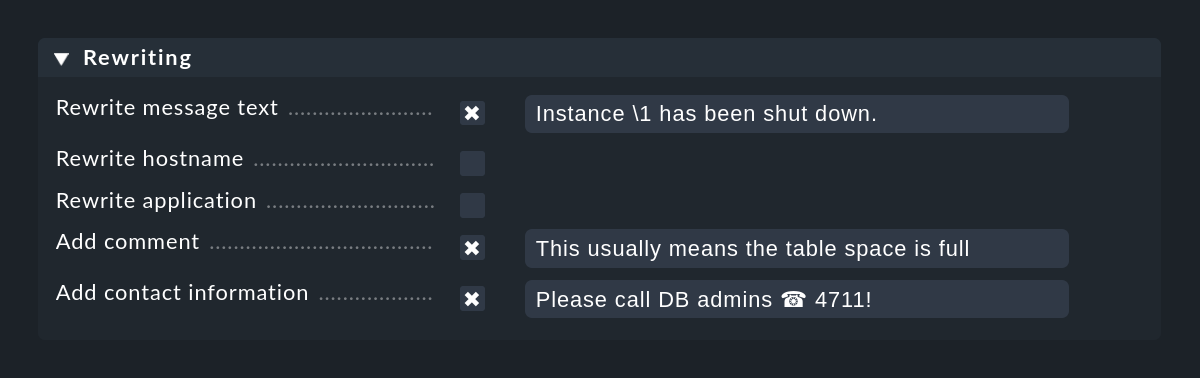
Beim Umschreiben sind die Match-Gruppen besonders wichtig. Denn Sie erlauben es, Teile der Originalmeldung gezielt in den neuen Text einzubauen. Sie können bei den Ersetzungen auf die Gruppen wie folgt zugreifen:
|
Wird durch die erste Match-Gruppe der Originalmeldung ersetzt. |
|
Wird durch die zweite Match-Gruppe der Originalmeldung ersetzt (usw.). |
|
Wird durch die komplette Originalmeldung ersetzt. |
In obigem Screenshot wird der neue Meldungstext auf Instance \1 has been shut down. gesetzt.
Das klappt natürlich nur, wenn beim Text to match in der gleichen Regel der reguläre Suchausdruck auch mindestens einen Klammerausdruck hat.
Ein Beispiel dafür wäre z.B.:

Einige weitere Hinweise zum Umschreiben:
Das Umschreiben geschieht nach dem Matchen und vor dem Ausführen von Aktionen.
Match, Umschreiben und Aktionen geschehen immer in der gleichen Regel. Es ist nicht möglich, eine Meldung umzuschreiben, um sie dann mit einer späteren Regel zu bearbeiten.
Die Ausdrücke
\1,\2usw. können in allen Textfeldern verwendet werden, nicht nur im Rewrite message text.
5.4. Automatisches Aufheben von Events (Canceling)
Manche Anwendungen oder Geräte sind so nett, nach einer Störmeldung später eine passende OK-Meldung zu senden, sobald das Problem wieder behoben ist. Sie können die EC so konfigurieren, dass in so einem Fall das durch die Störung geöffnete Event automatisch wieder geschlossen wird. Dies nennt man Aufheben (canceling).
Folgende Abbildung zeigt eine Regel, in der nach Meldungen mit dem Text database instance (.*) has failed gesucht wird.
Der Ausdruck (.*) steht für eine beliebige Zeichenfolge, die in einer Match-Gruppe eingefangen wird.
Der Ausdruck database instance (.*) recovery in progress, welcher im Feld Text to cancel event(s) in der gleichen Regel eingetragen ist, sorgt für ein automatisches Schließen von mit dieser Regel erzeugten Events, wenn eine passende Meldung eingeht:
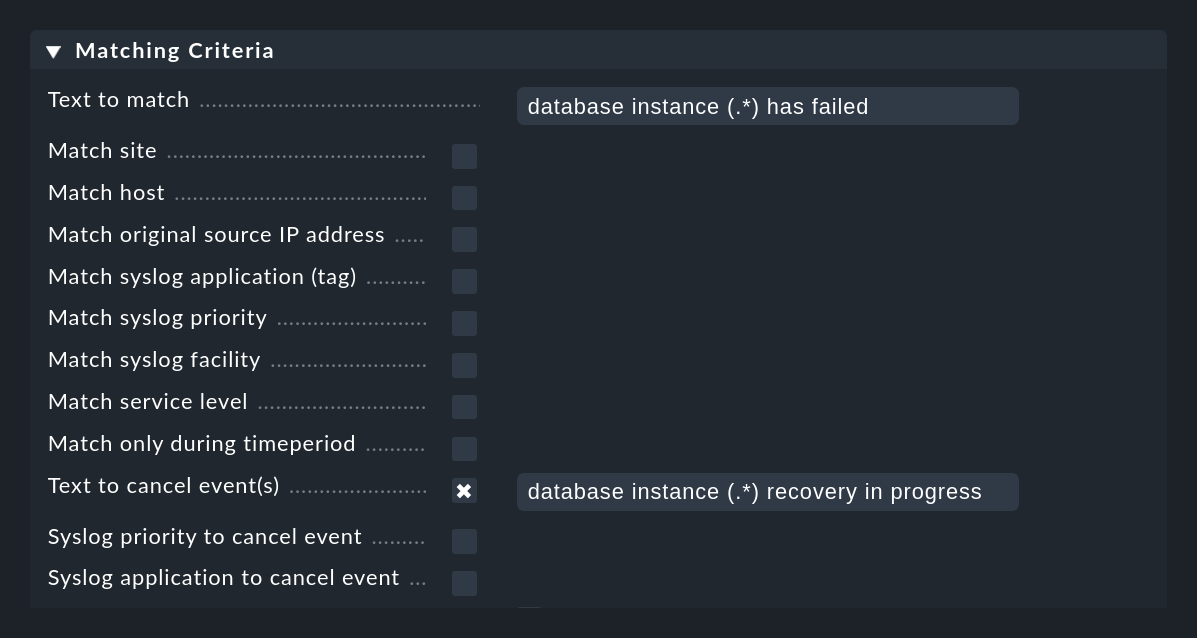
Das automatische Aufheben funktioniert genau dann, wenn
eine Meldung eingeht, deren Text auf Text to cancel event(s) passt,
der hier in der Gruppe
(.*)eingefangene Wert identisch mit der Match-Gruppe aus der ursprünglichen Meldung ist,beide Meldungen vom gleichen Host kamen und
es sich um die gleiche Anwendung handelt (Feld Syslog application to cancel event).
Das Prinzip der Match-Gruppen ist hier sehr wichtig.
Denn es wäre schließlich wenig sinnvoll, wenn die Meldung database instance TEST recovery in progress ein Event aufheben würde, das von der Meldung database instance PROD has failed stammt, oder?
Bitte machen Sie nicht den Fehler, in Text to cancel events(s) den Platzhalter \1 zu verwenden.
Das funktioniert nicht!
Diese Platzhalter funktionieren nur beim Rewriting.
In einigen Fällen kommt es vor, dass ein Text sowohl zur Erzeugung als auch zum Aufheben eines Events passt. In diesem Fall erhält das Aufheben Priorität.
Ausführen von Aktionen beim Aufheben
Sie können beim Aufheben eines Events auch automatisch Aktionen ausführen lassen. Dazu ist es wichtig zu wissen, dass beim Aufheben etliche Datenfelder des Events von Werten der OK-Meldung überschrieben werden, bevor die Aktionen ausgeführt werden. Auf diese Art sind im Aktionsskript dann die Daten der OK-Meldung vollständig verfügbar. Auch ist während dieser Phase der Zustand des Events als OK eingetragen. Auf diese Art kann ein Aktionsskript ein Aufheben erkennen und Sie können das gleiche Skript für Fehler und OK-Meldung verwenden (z.B. bei der Anbindung an ein Ticketsystem).
Folgende Felder werden aus Daten der OK-Meldung überschrieben:
Der Meldungstext
Der Zeitstempel
Die Zeit des letzten Auftretens
Die Syslog-Priorität
Alle anderen Felder bleiben unverändert — inklusive der Event-ID.
Aufheben in Kombination mit Umschreiben
Falls Sie in der gleichen Regel mit Umschreiben und Aufheben arbeiten, so sollten Sie vorsichtig sein beim Umschreiben des Host-Namens oder der Application. Beim Aufheben prüft die EC stets, ob die aufhebende Meldung zu Host-Name und Anwendung des offenen Events passt. Wenn diese aber umgeschrieben wurden, würde das Aufheben nie funktionieren.
Daher simuliert die Event Console vor dem Aufheben ein Umschreiben von Host-Name und Anwendung (application), um so die relevanten Texte zu vergleichen. Das ist wahrscheinlich das, was Sie auch erwarten würden.
Dieses Verhalten können Sie auch ausnutzen, wenn das Anwendungsfeld bei der Fehlermeldung und der späteren OK-Meldung nicht übereinstimmen. Schreiben Sie in diesem Fall einfach das Anwendungsfeld in einen bekannten festen Wert um. Das führt faktisch dazu, dass dieses Feld beim Aufheben ignoriert wird.
Aufheben anhand der Syslog-Priorität
Es gibt (leider) Fälle, in denen der Text der Fehler- und OK-Meldung absolut identisch ist. Meist ist der eigentliche Status dann nicht im Text, sondern in der Syslog-Priorität kodiert.
Dazu gibt es die Option Syslog priority to cancel event.
Geben Sie hier z.B. den Bereich debug … notice an.
Alle Prioritäten in diesem Bereich werden normalerweise als OK-Status gewertet.
Bei Verwendung dieser Option sollten Sie trotzdem in das Feld Text to cancel event(s) einen passenden Text eintragen.
Sonst wird die Regel auf alle OK-Meldungen matchen, welche die gleiche Anwendung betreffen.
5.5. Zählen von Meldungen
Im Kasten Counting & Timing finden Sie Optionen zum Zählen von gleichartigen Meldungen. Die Idee ist, dass manche Meldungen erst dann relevant sind, wenn Sie in bestimmten Zeiträumen zu häufig oder zu selten auftreten.
Zu häufige Meldungen
Das Prüfen auf zu oft auftretende Meldungen aktivieren Sie mit der Option Count messages in interval:
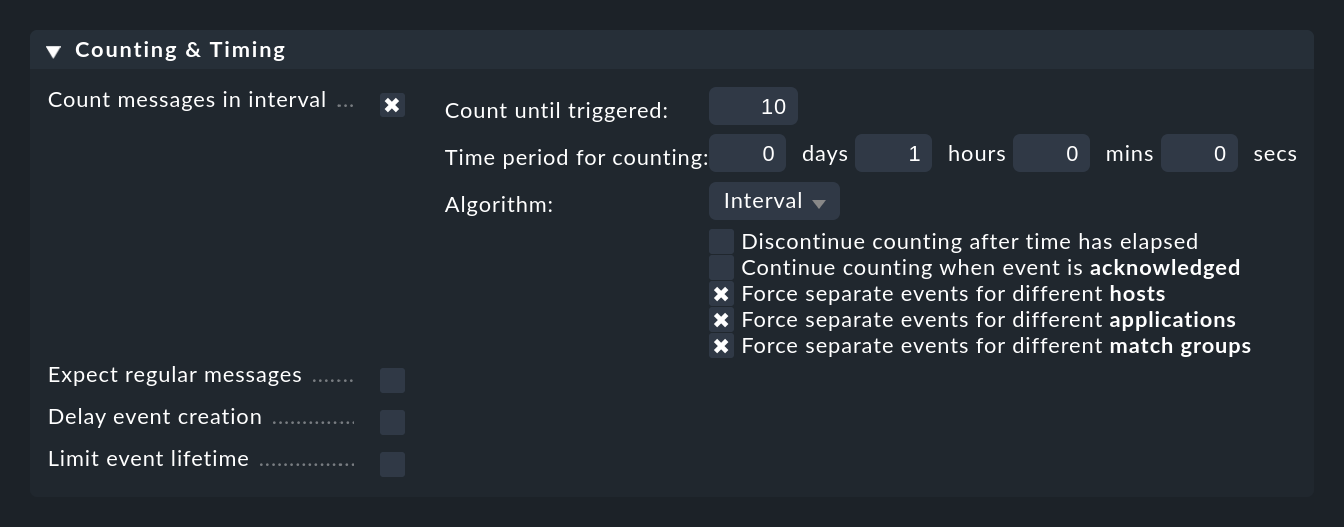
Hier geben Sie zunächst einen Zeitraum bei Time period for counting und eine Anzahl von Meldungen bei Count until triggered vor, die zum Öffnen eines Events führen sollen. Im Beispiel in der Abbildung ist das auf 10 Meldungen pro Stunde eingestellt. Natürlich handelt es sich dabei nicht um 10 beliebige Meldungen, sondern um solche, die von der Regel gematcht werden.
Normalerweise ist es hier aber sinnvoll, nicht einfach global alle passenden Meldungen zu zählen, sondern nur diejenigen, die sich auf die gleiche „Ursache“ beziehen. Um das zu steuern, gibt es die drei Checkboxen mit dem Titel Force separate events for different …. Diese sind so voreingestellt, dass Meldungen nur dann zusammengezählt werden, wenn sie übereinstimmen in:
Host
Anwendung
Damit können Sie Regeln formulieren wie „Wenn vom gleichen Host, der gleichen Anwendung und dort der gleichen Instanz mehr als 10 Meldungen pro Stunde kommen, dann…“. Dadurch kann es dann auch sein, dass aufgrund der Regel mehrere unterschiedliche Events erzeugt werden.
Wählen Sie z.B. alle drei Checkboxen ab, so wird nur noch global gezählt und die Regel kann auch nur insgesamt ein einziges Event generieren!
Es kann übrigens durchaus sinnvoll sein, als Anzahl eine 1 einzutragen. Damit können Sie „Event-Stürme“ effektiv in den Griff bekommen. Kommen z.B. in kurzer Zeit 100 Meldungen der gleichen Art, so wird dafür dann trotzdem nur ein einziges Event erzeugt. Sie sehen dann in den Event-Details
den Zeitpunkt des Auftretens der ersten Meldung,
den Zeitpunkt der jüngsten Meldung und
die Gesamtzahl an Meldungen, die in diesem Event zusammengefasst sind.
Wann der Fall dann „abgeschlossen“ ist und bei erneuten Meldungen wieder ein neues Event aufgemacht werden soll, legen Sie über zwei Checkboxen fest. Normalerweise führt eine Quittierung des Events dazu, dass bei weiteren Meldungen eine neue Zählung mit einem neuen Event angefangen wird. Das können Sie mit Continue counting when event is acknowledged abschalten.
Die Option Discontinue counting after time has elapsed sorgt dafür, dass für jeden Vergleichszeitraum immer ein separates Event geöffnet wird. In obigem Beispiel war eine Schwelle von 10 Meldungen pro Stunde eingestellt. Ist diese Option aktiviert, so werden auf ein bereits geöffnetes Event maximal 10 Meldungen einer Stunde aufgerechnet. Sobald die Stunde abgelaufen ist, wird (bei ausreichender Zahl von Meldungen) wieder ein neues Event geöffnet.
Setzen Sie z.B. die Anzahl auf 1 und das Zeitintervall auf einen Tag, so werden Sie pro Tag von diesem Meldungstyp nur noch maximal ein Event sehen.
Die Einstellung Algorithm ist auf den ersten Blick vielleicht etwas überraschend. Aber mal ehrlich: Was meint man eigentlich mit „10 Meldungen pro Stunde“? Welche Stunde ist damit gemeint? Immer volle Stunden der Tageszeit? Dann könnte es sein, dass in der letzten Minute einer Stunde neun Meldungen kommen und in der ersten Minute der nächsten nochmal neun. Macht insgesamt 18 Meldungen in zwei Minuten. Aber trotzdem weniger als 10 pro Stunde und die Regel würde nicht greifen. Das klingt nicht so sinnvoll …
Weil es dazu nicht nur eine einzige Lösung gibt, bietet Checkmk drei verschiedene Definitionen an, was denn „10 Meldungen pro Stunde“ genau bedeuten soll:
| Algorithmus | Funktionsweise |
|---|---|
Interval |
Das Zählintervall startet bei der ersten eingehenden passenden Meldung. Ein Event in der Phase counting wird erzeugt. Vergeht nun die eingestellte Zeit, bevor die Anzahl erreicht wird, wird das Event stillschweigend gelöscht. Wird die Anzahl aber schon vor Ablauf der Zeit erreicht, wird das Event sofort geöffnet (und eventuell konfigurierte Aktionen ausgelöst). |
Token Bucket |
Dieser Algorithmus arbeitet nicht mit festen Zeitintervallen, sondern implementiert ein Verfahren, das bei Netzwerken oft zum Traffic Shaping eingesetzt wird. Angenommen, Sie haben 10 Meldungen pro Stunde konfiguriert. Das sind im Schnitt eine alle 6 Minuten. Wenn zum ersten Mal eine passende Meldung eingeht, wird ein Event in der Phase counting erzeugt und die Anzahl auf 1 gesetzt. Bei jeder weiteren Meldung wird diese um 1 erhöht. Und alle 6 Minuten wird der Zähler wieder um 1 verringert — egal, ob eine Meldung gekommen ist oder nicht. Fällt der Zähler wieder auf 0, wird das Event gelöscht. Der Trigger wird also dann ausgelöst, wenn die Rate der Meldungen im Schnitt dauerhaft über 10 pro Stunde liegt. |
Dynamic Token Bucket |
Dies ist eine Variante des Token Bucket-Algorithmus, bei der der Zähler umso langsamer verringert wird, je kleiner er gerade ist. In obigem Beispiel würde der Zähler bei Stand von 5 nur alle 12 statt alle 6 Minuten verringert. Das führt insgesamt dazu, dass Meldungsraten, die nur knapp über der erlaubten Rate liegen, deutlich schneller ein Event öffnen (und damit benachrichtigt werden). |
Welchen Algorithmus sollten Sie also wählen?
Interval ist am einfachsten zu verstehen und leichter nachzuvollziehen, wenn Sie später in Ihrem Syslog-Archiv genau nachzählen möchten.
Token Bucket dagegen ist intelligenter und „weicher“. Es kommt zu weniger Anomalien an den Rändern der Intervalle.
Dynamic Token Bucket macht das System reaktiver und erzeugt schneller Benachrichtigungen.
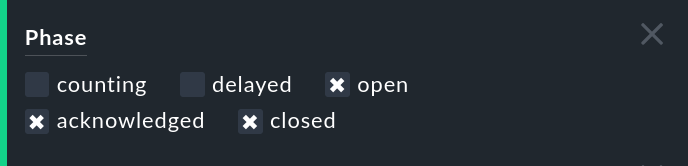
Events, die die eingestellte Anzahl noch nicht erreicht haben, sind latent schon vorhanden aber für den Operator nicht automatisch sichtbar. Sie befinden sich in der Phase counting. Sie können solche Events mit dem Filter Phase in der Event-Ansicht sichtbar machen:
Zu seltene oder ausbleibende Meldungen
Genauso wie das Eingehen einer bestimmten Meldung kann auch das Ausbleiben ein Problem bedeuten. Eventuell erwarten Sie pro Tag mindestens eine Meldung von einem bestimmten Job. Bleibt diese aus, ist der Job wahrscheinlich nicht gelaufen und sollte dringend repariert werden.
So etwas können Sie unter Counting & Timing > Expect regular messages konfigurieren:
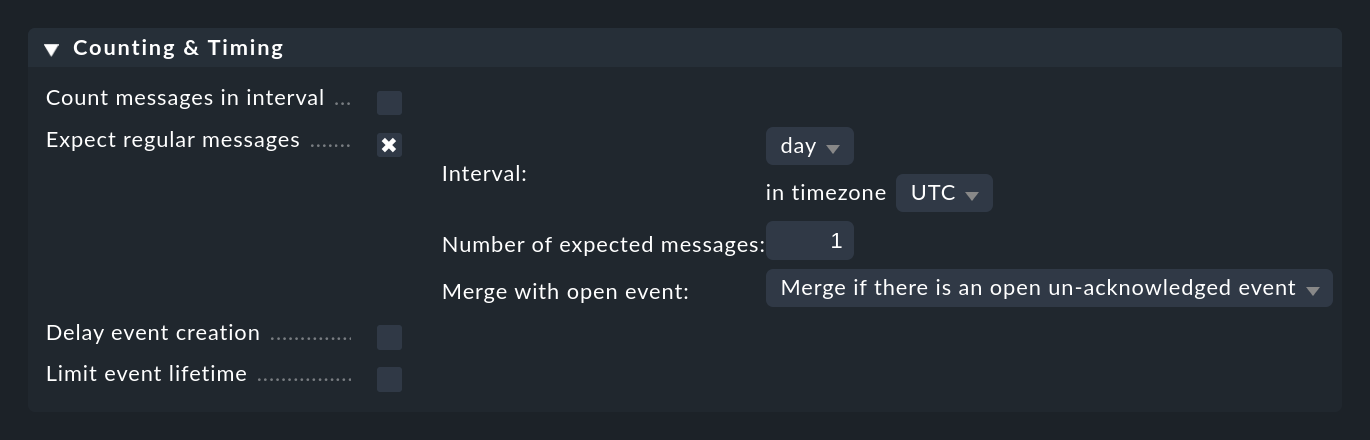
Wie beim Zählen müssen Sie auch hier einen Zeitraum angeben, in dem Sie die Meldung(en) erwarten. Hier kommt allerdings ein ganz anderer Algorithmus zur Anwendung, der an dieser Stelle viel sinnvoller ist. Der Zeitraum wird hier nämlich immer exakt an definierten Stellen ausgerichtet. So wird z.B. beim Interval hour immer bei Minute und Sekunde Null begonnen. Sie haben folgende Optionen:
| Interval | Ausrichtung |
|---|---|
10 seconds |
Bei einer durch 10 teilbaren Sekundenzahl |
minute |
Auf der vollen Minute |
5 minutes |
Bei 0:00, 0:05, 0:10, usw. |
15 minutes |
Bei 0:00, 0:15, 0:30, 0:45, usw. |
hour |
Auf dem Beginn jeder vollen Stunde |
day |
Exakt bei 00:00 Uhr, allerdings in einer konfigurierbaren Zeitzone. Damit können Sie auch sagen, dass Sie eine Meldung zwischen 12:00 Uhr und 12:00 Uhr am nächsten Tag erwarten. Wenn Sie selbst z.B. in der Zeitzone UTC +1 sind, geben Sie dazu UTC -11 hours an. |
two days |
Zu Beginn einer vollen Stunde. Sie können hier einen Zeitzonenoffset von 0 bis 47 angeben, der sich auf 1970-01-01 00:00:00 UTC bezieht. |
week |
Um 00:00 Uhr am Donnerstag morgen in der Zeitzone UTC plus das Offset, das Sie in Stunden ausgeben können. Donnerstag deswegen, weil der 1.1.1970 — der Beginn der „Epoche“, an einem Donnerstag war. |
Warum ist das so kompliziert? Das soll Fehlalarme vermeiden. Erwarten Sie z.B. eine Meldung vom Backup pro Tag? Sicher wird es leichte Unterschiede in der Laufzeit des Backups geben, so dass die Meldungen nicht exakt 24 Stunden auseinander liegen. Erwarten Sie die Meldung z.B. ungefähr gegen Mitternacht plus/minus ein oder zwei Stunden, so ist ein Intervall von 12:00 bis 12:00 Uhr viel robuster, als eines von 00:00 bis 00:00 Uhr. Allerdings bekommen Sie dann auch erst um 12:00 Uhr eine Benachrichtigung, wenn die Meldung ausbleibt.
Mehrfaches Auftreten des gleichen Problems
Die Option Merge with open event ist so voreingestellt, dass bei einem mehrfachen hintereinander Ausbleiben der gewünschten Meldung, das bestehende Event aktualisiert wird. Dies können Sie so umschalten, dass jedes Mal ein neues Event aufgemacht wird.
5.6. Timing
Unter Counting & Timing gibt es zwei Optionen, welche das Öffnen bzw. automatische Schließen von Events betreffen.
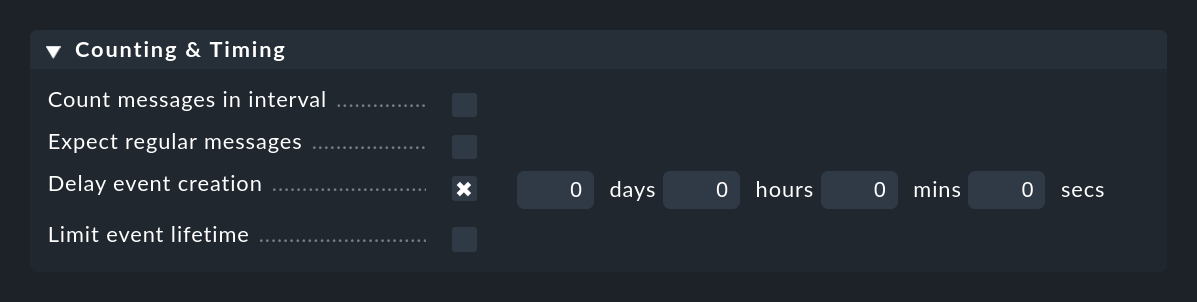
Die Option Delay event creation ist nützlich, wenn Sie mit dem automatischen Aufheben von Events arbeiten. Setzen Sie z.B. eine Verzögerung von 5 Minuten, so verharrt bei einer Störmeldung das so erzeugte Event 5 Minuten im Zustand delayed — in der Hoffnung, dass in dieser Zeit die OK-Meldung eintrifft. Ist das der Fall, so wird das Event automatisch und ohne Aufhebens wieder geschlossen und schlägt nicht im Monitoring auf. Läuft die Zeit aber ab, so wird das Event geöffnet und eventuell eine dafür definierte Aktion ausgeführt:
In etwa das Gegenteil macht Limit event lifetime. Damit können Sie Events nach einer bestimmten Zeit automatisch schließen lassen. Das ist z.B. nützlich für informative Events mit OK-Status, die Sie zwar anzeigen möchten, aber für die das Monitoring keine Aktivitäten nach sich ziehen soll. Durch das automatische „Herausaltern“ sparen Sie sich das manuelle Löschen solcher Meldungen:
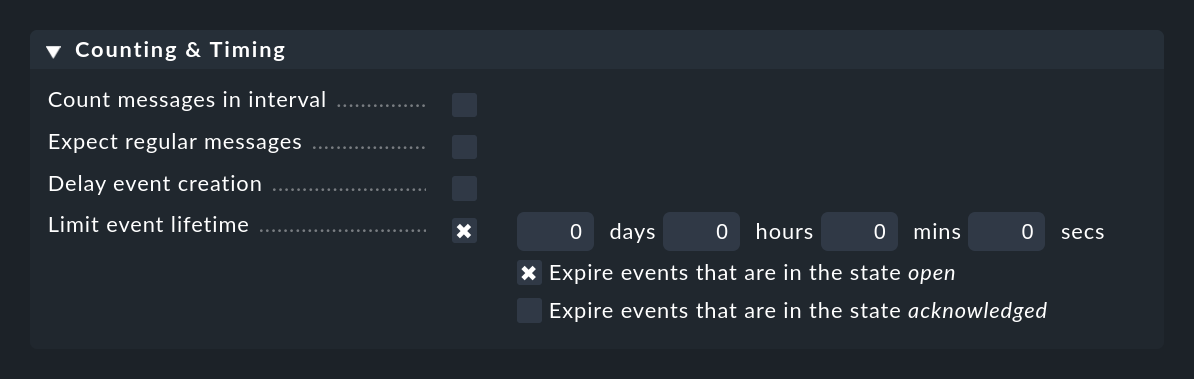
Durch ein Quittieren wird das Herausaltern erst einmal gestoppt. Dieses Verhalten können Sie aber mit den beiden Checkboxen nach Bedarf justieren.
5.7. Regelpakete
Regelpakete haben nicht nur den Sinn, Dinge übersichtlicher zu machen, sondern können die Konfiguration vieler ähnlicher Regeln auch deutlich vereinfachen und gleichzeitig die Auswertung beschleunigen.
Angenommen, Sie haben einen Satz von 20 Regeln, die sich alle um das Windows Event Log Security drehen. Alle diese Regeln haben gemeinsam, dass sie in der Bedingung auf einen bestimmten Text im Anwendungsfeld prüfen (der Name dieser Log-Datei wird bei den Meldungen von der EC als Application eingetragen). Gehen Sie in so einem Fall wie folgt vor:
Legen Sie ein eigenes Regelpaket an.
Legen Sie die 20 Regeln für Security in diesem Paket an oder ziehen Sie sie dorthin um (Auswahlliste Move to pack… rechts in der Regeltabelle).
Entfernen Sie aus allen diesen Regeln die Bedingung auf die Anwendung.
Legen Sie als erste Regel in dem Paket eine Regel an, durch die Meldungen das Paket sofort verlassen, wenn die Anwendung nicht Security ist.
Diese Ausschlussregel ist wie folgt aufgebaut:
Matching Criteria > Match syslog application (tag) auf
SecurityMatching Criteria > Invert matching auf Negate match: Execute this rule if the upper conditions are not fulfilled.
Outcome & Action > Rule type auf Skip this rule pack, continue rule execution with next rule pack
Jede Meldung, die nicht vom Security-Log kommt, wird also bereits von der ersten Regel in diesem Paket „abgewiesen“. Das vereinfacht nicht nur die weiteren Regeln des Pakets, sondern beschleunigt auch die Abarbeitungen, da diese in den meisten Fällen gar nicht mehr geprüft werden müssen.
6. Aktionen
6.1. Arten von Aktionen
Die Event Console bietet drei Arten von Aktionen, welche Sie entweder manuell oder beim Öffnen oder Aufheben von Events ausführen lassen können:
Ausführen von selbst geschriebenen Shell-Skripten
Versenden von selbst definierten E-Mails
Erzeugen von Checkmk Benachrichtigungen
6.2. Shell-Skripte und E-Mails
E-Mails und Skripte müssen Sie zunächst in den Einstellungen der Event Console definieren. Sie finden diese unter dem Eintrag Actions (E-Mails & Scripts):
Shell-Skripte ausführen
Mit dem Knopf Add new action legen Sie eine neue Aktion an.
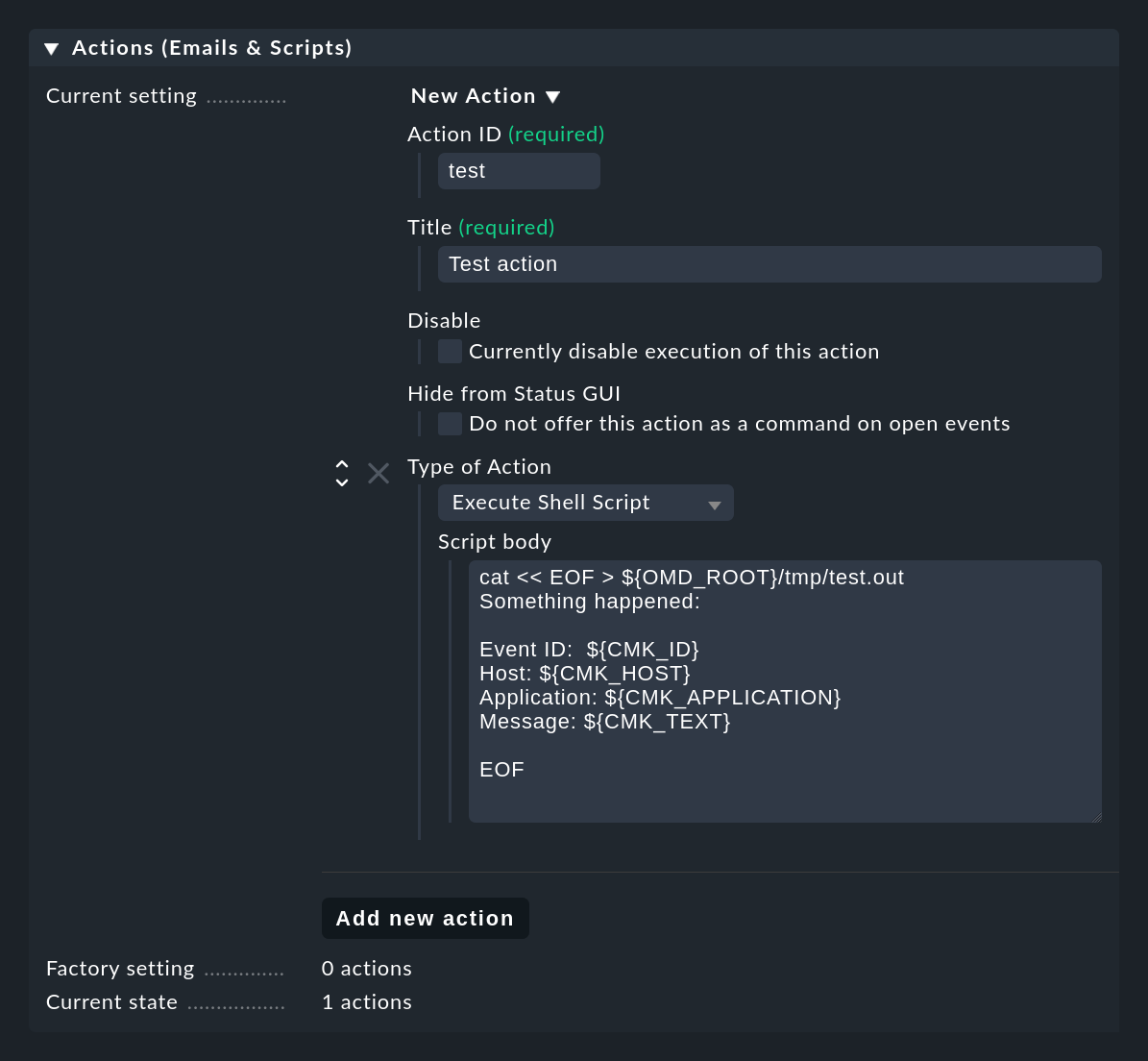
Folgendes Beispiel zeigt, wie Sie ein einfaches Shell-Skript als Aktion vom Typ Execute Shell Script anlegen können.
Dem Skript stehen über Umgebungsvariablen Details zu den Events zur Verfügung,
beispielsweise die $CMK_ID des Events, der $CMK_HOST, Volltext $CMK_TEXT oder die erste Match-Gruppe als $CMK_MATCH_GROUP_1.
Eine vollständige Liste der verfügbaren Umgebungsvariablen erhalten Sie in der ![]() Inline-Hilfe.
Inline-Hilfe.
Ältere Versionen von Checkmk haben neben Umgebungsvariablen auch Makros wie $TEXT$ erlaubt, die vor Ausführung des Skriptes ersetzt wurden.
Wegen der Gefahr, dass ein Angreifer über ein eigens angefertigtes UDP-Paket Befehle einschleusen kann, die mit den Rechten des Checkmk Prozesses ausgeführt werden, sollten Sie von Makros keinen Gebrauch machen.
Makros sind derzeit noch aus Kompatibilitätsgründen erlaubt, jedoch behalten wir uns die Entfernung in einer künftigen Checkmk Version vor.
Das Beispielskript aus dem Screenshot legt im Instanzverzeichnis die Datei tmp/test.out an und schreibt dort einen Text mit den konkreten Werten der Variablen zu dem jeweils letzten Event:
cat << EOF > ${OMD_ROOT}/tmp/test.out
Something happened:
Event-ID: $CMK_ID
Host: $CMK_HOST
Application: $CMK_APPLICATION
Message: $CMK_TEXT
EOFDie Skripte werden unter folgender Umgebung ausgeführt:
Als Interpreter wird
/bin/bashverwendet.Das Skript läuft als Instanzbenutzer mit dem Home-Verzeichnis der Instanz (z.B.
/omd/sites/mysite).Während der Laufzeit des Skripts ist die Verarbeitung weiterer Events angehalten!
Sollte Ihr Skript eventuell Wartezeiten enthalten, können Sie es mithilfe von Linux' at-Spooler asynchron laufen lassen.
Dazu legen Sie das Skript in einer eigenen Datei local/bin/myaction an und starten es mit dem at-Befehl, z.B.:
echo "$OMD_ROOT/local/bin/myaction '$HOST$' '$TEXT$' | at nowVersenden von E-Mails
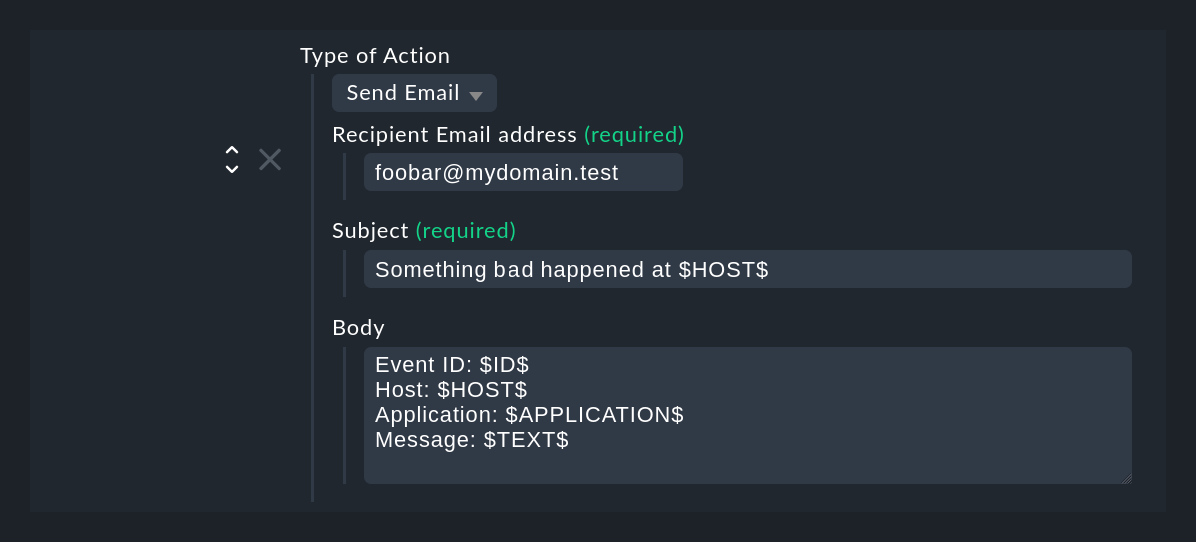
Der Aktionstyp Send Email versendet eine einfache Text-E-Mail.
Eigentlich könnten Sie das auch über den Umweg mit einem Skript erreichen, in dem Sie z.B. mit dem Kommandozeilenbefehl mail arbeiten.
Aber so ist es komfortabler.
Bitte beachten Sie, dass auch in den Feldern Recipient E-Mail address und Subject Platzhalter erlaubt sind.
6.3. Benachrichtigung durch Checkmk
Neben dem Ausführen von Skripten und dem Versenden von (einfachen) E-Mails kennt die EC noch eine dritte Art von Aktion: Das Versenden von Benachrichtigungen über das Checkmk Benachrichtigungssystem. Die dabei von der EC erzeugten Benachrichtigungen gehen den gleichen Weg, wie die Host- und Servicebenachrichtigungen aus dem aktiven Monitoring. Die Vorteile gegenüber den oben beschriebenen einfachen E-Mails liegen auf der Hand:
Die Benachrichtigung wird für aktives und Event-basiertes Monitoring gemeinsam an zentraler Stelle konfiguriert.
Funktionen wie Sammelbenachrichtigungen, HTML-E-Mails und andere nützliche Dinge stehen zur Verfügung.
Benutzerdefinierte Benachrichtigungsregeln, ein Abschalten der Benachrichtigungen und Ähnliches funktionieren wie gewohnt.
Die Aktionsart Send monitoring notification, die das macht, steht immer automatisch zur Verfügung und muss nicht extra konfiguriert werden.
Da Events einige Unterschiede zu den „normalen“ Hosts oder Services haben, gibt es ein paar Besonderheiten bei deren Benachrichtigung, welche Sie im Folgenden genauer kennen lernen.
Zuordnung zu bestehenden Hosts
Events können von beliebigen Hosts kommen — egal, ob diese im aktiven Monitoring konfiguriert sind oder nicht. Schließlich steht der Syslog- und SNMP-Port allen Hosts im Netzwerk offen. Daher stehen die erweiterten Host-Attribute wie Alias, Host-Merkmale, Kontakte usw. erst einmal nicht zur Verfügung. Das bedeutet insbesondere, dass Bedingungen in Benachrichtigungsregeln nicht unbedingt so funktionieren, wie Sie das erwarten würden.
Daher versucht die EC bei der Benachrichtigung einen zum Event passenden Host aus dem aktiven Monitoring zu finden. Dabei wird das gleiche Verfahren wie bei der Sichtbarkeit von Events angewandt. Kann so ein Host gefunden werden, so werden von diesem folgende Daten übernommen:
Die korrekte Schreibweise des Host-Namens
Der Host-Alias
Die in Checkmk konfigurierte primäre IP-Adresse
Die Host-Merkmale (host tags)
Der Ordner in der Setup-GUI
Die Liste der Kontakte und Kontaktgruppen
Dadurch kann es dazu kommen, dass der Host-Name in der Benachrichtigung nicht exakt mit dem Host-Namen aus der ursprünglichen Meldung übereinstimmt. Die Anpassung auf die Schreibweise des aktiven Monitorings vereinfacht aber das Formulieren von einheitlichen Benachrichtigungsregeln, welche Bedingungen auf den Host-Namen enthalten.
Die Zuordnung geschieht in Echtzeit durch eine Livestatus-Abfrage an den Monitoring-Kern, welcher in der gleichen Instanz wie die EC läuft, die die Meldung empfangen hat. Das klappt natürlich nur, wenn die Syslog-Meldungen, SNMP-Traps usw. immer an diejenige Checkmk Instanz gesendet werden, auf der der Host auch aktiv überwacht wird!
Falls die Abfrage nicht klappt oder der Host nicht gefunden werden kann, werden Ersatzdaten angenommen:
Host-Name |
Der Host-Name aus dem Event. |
Host-Alias |
Als Alias wird der Host-Name verwendet. |
IP-Adresse |
Das Feld IP-Adresse enthält die originale Absenderadresse der Meldung. |
Host-Merkmale |
Der Host erhält kein Host-Merkmal. Falls Sie Host-Merkmalsgruppen mit leeren Merkmalen haben, nimmt der Host dort diese Merkmale an. Ansonsten hat er kein Merkmal der Gruppe. Bitte beachten Sie das, wenn Sie in den Benachrichtigungsregeln Bedingungen über Host-Merkmale definieren. |
Setup-GUI Ordner |
Kein Ordner. Sämtliche Bedingungen, die auf einen bestimmten Ordner gehen, sind damit unerfüllbar — selbst wenn es sich um den Hauptordner handelt. |
Kontakte |
Die Liste der Kontakte ist leer. Sind Fallback-Kontakte vorhanden, werden diese eingetragen. |
Wenn der Host im aktiven Monitoring nicht zugeordnet werden kann, kann das natürlich zu Problemen bei der Benachrichtigung führen. Zum einen wegen der Bedingungen, die dann eventuell nicht mehr greifen, zum anderen wegen der Kontaktauswahl. Für solche Fälle können Sie Ihre Benachrichtigungsregeln so anpassen, dass Benachrichtigungen aus der Event Console mit einer eigenen Regel gezielt behandelt werden. Dazu gibt es eine eigene Bedingung, mit der Sie entweder positiv nur auf EC-Benachrichtigungen matchen oder umgekehrt diese ausschließen können:
Restliche Felder der Benachrichtigung
Damit Benachrichtigungen aus der EC das Benachrichtigungssystem des aktiven Monitorings durchlaufen können, muss sich die EC an dessen Schema anpassen. Dabei werden die typischen Datenfelder einer Benachrichtigung so sinnvoll wie möglich gefüllt. Wie die Daten des Hosts ermittelt werden, haben wir gerade beschrieben. Weitere Felder sind:
Benachrichtigungstyp |
EC-Benachrichtigungen gelten immer als Servicenachricht. |
Service description |
Hier wird der Inhalt des Felds Application aus dem Event eingetragen. Falls das leer ist, wird |
Benachrichtigungsnummer |
Diese ist fest auf |
Datum/Uhrzeit |
Bei Events, die zählen, ist das der Zeitpunkt des letzten Auftretens einer zum Event gehörigen Meldung. |
Plugin Output |
Der Textinhalt des Events. |
Service-Zustand |
Zustand des Events, also OK, WARN, CRIT oder UNKNOWN. |
Vorheriger Zustand |
Da Events keinen früheren Status haben, wird hier bei normalen Events immer OK, beim Aufhebung eines Events immer CRIT eingetragen. Diese Regelung kommt dem am nächsten, was man für Benachrichtigungsregeln braucht, die eine Bedingung auf den genauen Zustandswechsel haben. |
Kontaktgruppen manuell festlegen
Wie oben beschrieben, können zu einem Event eventuell nicht die passenden Kontakte automatisch ermittelt werden. Für solche Fälle können Sie direkt in der EC-Regel Kontaktgruppen angeben, welche für die Benachrichtigung verwendet werden sollen. Wichtig ist, dass Sie den Haken bei Use in notifications nicht vergessen:
Globaler Schalter für Benachrichtigungen
Im Snapin Master control gibt es einen zentralen Schalter für Benachrichtigungen. Dieser gilt auch für Benachrichtigungen, die von der EC weitergeleitet werden:
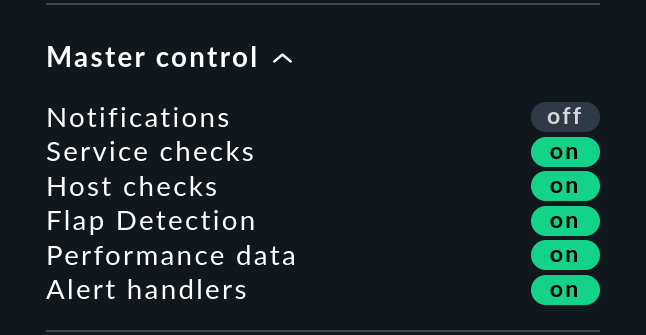
Ebenso wie die Host-Zuordnung erfordert die Abfrage des Schalters durch die EC einen Livestatus-Zugriff auf den lokalen Monitoring-Kern. Eine erfolgreiche Abfrage sehen Sie in der Log-Datei der Event Console:
[1482142567.147669] Notifications are currently disabled. Skipped notification for event 44Wartungszeiten von Hosts
Die Event Console erkennt Hosts, die gerade in einer Wartungszeit sind und versendet in diesem Fall keine Benachrichtigungen. In der Log-Datei sieht das so aus:
[1482144021.310723] Host myserver123 is currently in scheduled downtime. Skipping notification of event 433.Auch das setzt natürlich ein erfolgreiches Finden des Hosts im aktiven Monitoring voraus. Falls dies nicht gelingt, wird angenommen, dass sich der Host nicht in Wartung befindet und die Benachrichtigung auf jeden Fall generiert.
Zusätzliche Makros
Falls Sie ein eigenes Benachrichtigungsskript schreiben, haben Sie speziell bei Benachrichtigungen, die aus der Event Console kommen, etliche zusätzliche Variablen
zur Verfügung, die den ursprünglichen Event beschreiben (Zugriff wie gewohnt mit Präfix NOTIFY_):
|
Event-ID. |
|
ID der Regel, die das Event erzeugt hat. |
|
Syslog-Priorität als Zahl von |
|
Syslog Facility — ebenfalls als Zahl. Der Wertebereich geht von |
|
Phase des Events. Da nur offene Events Aktionen auslösen, sollte hier |
|
Das Kommentarfeld des Events. |
|
Das Feld Owner. |
|
Das Kommentarfeld mit der Event-spezifischen Kontaktinformation. |
|
Die ID des Prozesses, der die Meldung gesendet hat (bei Syslog-Events). |
|
Die Match-Gruppen vom Matchen in der Regel. |
|
Die optional manuell in der Regel definierten Kontaktgruppen. |
6.4. Aktionen ausführen
Das manuelle Ausführen von Aktionen durch den Operator haben Sie schon weiter oben bei den Kommandos gesehen. Spannender ist das automatische Ausführen von Aktionen, welches Sie in EC-Regeln im Abschnitt Outcome & Action konfigurieren können:
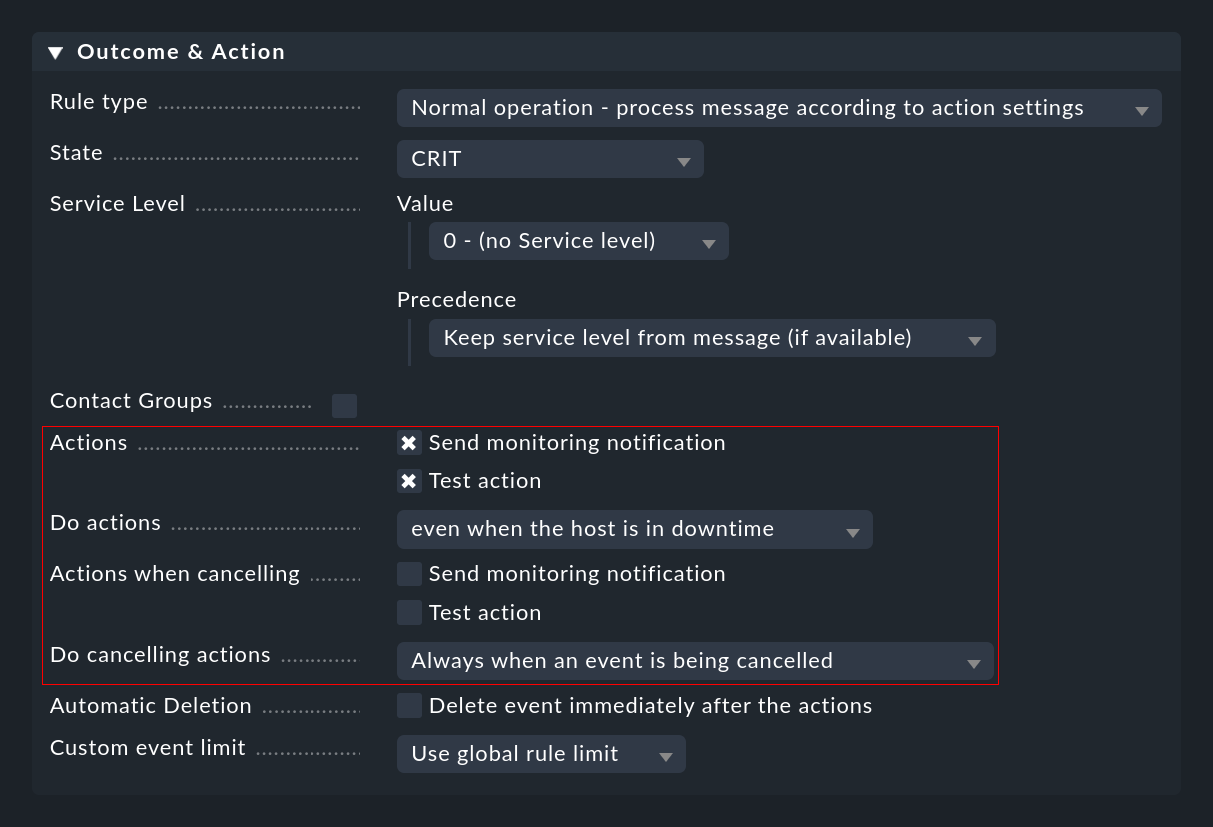
Hier können Sie eine oder mehrere Aktionen auswählen, die immer dann ausgeführt werden, wenn aufgrund der Regel ein Event geöffnet oder aufgehoben wird. Bei Letzterem können Sie über die Liste Do cancelling actions noch festlegen, ob die Aktion nur dann ausgeführt werden soll, wenn das aufgehobene Event schon die Phase open erreicht hat. Bei Verwendung von Zählen oder Verzögerung kann es nämlich dazu kommen, dass Events aufgehoben werden, die quasi noch im Wartezustand und für den Benutzer noch nicht sichtbar waren.
Die Ausführung von Aktionen wird in der Log-Datei var/log/mkeventd.log vermerkt:
[1481120419.712534] Executing command: ACTION;1;cmkadmin;test
[1481120419.718173] Exitcode: 0Auch in das Archiv werden diese geschrieben.
7. SNMP-Traps
7.1. Empfang von SNMP-Traps aufsetzen
Da die Event Console eine eingebaute eigene SNMP-Engine hat, ist das Aufsetzen des Empfangs von SNMP-Traps sehr einfach.
Sie benötigen keinen snmptrapd vom Betriebssystem!
Falls Sie diesen bereits am Laufen haben, so beenden Sie ihn bitte.
Wie im Abschnitt über das Aufsetzen der Event Console beschrieben, aktivieren Sie mit omd config den Trap-Empfänger in dieser Instanz:
Da auf jedem Server der UDP-Port für die Traps nur von einem Prozess verwendet werden kann, darf das pro Rechner nur in einer einzigen Checkmk Instanz gemacht werden.
Beim Start der Instanz können Sie in der Zeile mit mkeventd kontrollieren, ob der Trap-Empfang eingeschaltet ist:
OMD[mysite]:~$ omd start
Creating temporary filesystem /omd/sites/mysite/tmp...OK
Starting mkeventd (builtin: snmptrap)...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
Initializing Crontab...OKDamit SNMP-Traps funktionieren, müssen sich Sender und Empfänger auf bestimmte Credentials einigen. Im Fall von SNMP v1 und v2c ist das ein einfaches Passwort, was hier „Community“ genannt wird. Bei Version 3 benötigen Sie ein paar mehr Angaben. Diese Credentials konfigurieren Sie in den Einstellungen der Event Console unter Credentials for processing SNMP traps. Dabei können Sie mit dem Knopf Add new element mehrere unterschiedliche Credentials einrichten, welche von den Geräten alternativ verwendet werden können:
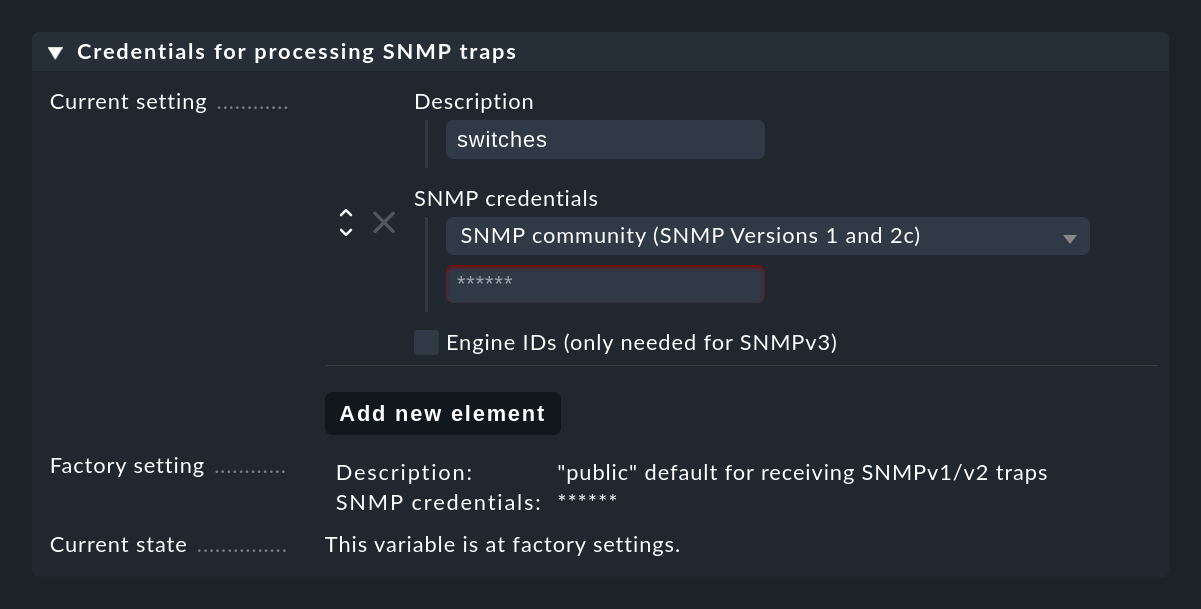
Der weitaus aufwendigere Teil ist es jetzt natürlich, bei allen Zielgeräten, die überwacht werden sollen, die Zieladresse für Traps einzutragen und auch hier die Credentials zu konfigurieren.
7.2. Testen
Leider bieten die wenigsten Geräte sinnvolle Testmöglichkeiten.
Immerhin können Sie den Empfang der Traps durch die Event Console selbst recht einfach von Hand testen, indem Sie — am besten von einem anderen Linux-Rechner aus — eine Test-Trap senden.
Dies geht mit dem Befehl snmptrap.
Folgendes Beispiel sendet eine Trap an 192.168.178.11.
Der eigene Host-Name wird nach dem .1.3.6.1 angegeben und muss auflösbar sein oder als IP-Adresse (hier 192.168.178.30) angegeben werden:
user@host:~$ snmptrap -v 1 -c public 192.168.178.11 .1.3.6.1 192.168.178.30 6 17 '' .1.3.6.1 s "Just kidding"Falls Sie in den Einstellungen das Log level auf Verbose logging eingestellt haben, können Sie den Empfang und die Auswertung der Traps in der Log-Datei der EC sehen:
[1482387549.481439] Trap received from 192.168.178.30:56772. Checking for acceptance now.
[1482387549.485096] Trap accepted from 192.168.178.30 (ContextEngineId "0x80004fb8054b6c617070666973636816893b00", ContextName "")
[1482387549.485136] 1.3.6.1.2.1.1.3.0 = 329887
[1482387549.485146] 1.3.6.1.6.3.1.1.4.1.0 = 1.3.6.1.0.17
[1482387549.485186] 1.3.6.1.6.3.18.1.3.0 = 192.168.178.30
[1482387549.485219] 1.3.6.1.6.3.18.1.4.0 =
[1482387549.485238] 1.3.6.1.6.3.1.1.4.3.0 = 1.3.6.1
[1482387549.485258] 1.3.6.1 = Just kiddingBei falschen Credentials sehen Sie nur eine einzige Zeile:
[1482387556.477364] Trap received from 192.168.178.30:56772. Checking for acceptance now.Und so sieht ein Event aus, das von solch einer Trap erzeugt wurde:

7.3. Aus Zahlen werden Texte: Traps übersetzen
SNMP ist ein binäres Protokoll und sehr sparsam mit textuellen Beschreibungen der Meldungen.
Um welche Art von Traps es sich handelt, wird intern durch Folgen von Zahlen in sogenannten OIDs übermittelt.
Diese werden als durch Punkte getrennte Zahlenfolgen angezeigt (z.B. 1.3.6.1.6.3.18.1.3.0).
Mithilfe von sogenannten MIB-Dateien kann die Event Console diese Zahlenfolgen in Texte übersetzen.
So wird dann aus 1.3.6.1.6.3.18.1.3.0 z.B. der Text SNMPv2-MIB::sysUpTime.0.
Die Übersetzung der Traps schalten Sie in den Einstellungen der Event Console ein:

Die Test-Trap von oben erzeugt jetzt einen etwas anderen Event:

Haben Sie die Option Add OID descriptions aktiviert, wird das Ganze wesentlich umfangreicher — und unübersichtlicher. Es hilft aber besser zu verstehen, was ein Trap genau bedeutet:

7.4. Hochladen eigener MIBs
Leider haben sich die Vorteile von Open Source bei den Autoren von MIB-Dateien noch nicht herumgesprochen, und so sind wir vom Checkmk Projekt leider nicht in der Lage, herstellerspezifische MIB-Dateien mit auszuliefern.
Nur eine kleine Sammlung von freien Basis-MIBs ist vorinstalliert und sorgt z.B. für eine Übersetzung von sysUpTime.
Sie können aber in der Event Console im Modul SNMP MIBs for trap translation mit dem Menü-Eintrag ![]() Add one or multiple MIBs eigene MIB-Dateien hochladen, wie das hier mit einigen MIBs von Netgear Smart Switches geschehen ist:
Add one or multiple MIBs eigene MIB-Dateien hochladen, wie das hier mit einigen MIBs von Netgear Smart Switches geschehen ist:
Hinweise zu den MIBs:
Anstelle von Einzeldateien können Sie auch ZIP-Dateien mit MIBs-Sammlungen in einem Rutsch hochladen.
MIBs haben untereinander Abhängigkeiten. Fehlende MIBs werden Ihnen von Checkmk angezeigt.
Die hochgeladenen MIBs werden auch auf der Kommandozeile von
cmk --snmptranslateverwendet.
8. Überwachen von Log-Dateien
Der Checkmk Agent ist in der Lage, Log-Dateien über das Logwatch-Plugin auszuwerten. Dieses Plugin bietet zunächst einmal eine eigene von der Event Console unabhängige Überwachung von Log-Dateien — inklusive der Möglichkeit, Meldungen direkt im Monitoring zu quittieren. Es gibt aber auch die Möglichkeit, die vom Plugin gefundenen Meldungen 1:1 in die Event Console weiterzuleiten.
Beim Windows-Agenten ist die Log-Dateiüberwachung fest integriert — in Form eines Plugins für die Auswertung von Textdateien und eines für die von Windows Event Logs.
Für Linux und Unix steht das in Python geschriebene Plugin mk_logwatch bereit.
Alle drei können Sie über die Agentenbäckerei aufsetzen bzw. konfigurieren.
Verwenden Sie dazu folgende Regelsätze:
Text logfiles (Linux, Solaris, Windows)
Finetune Windows Eventlog monitoring
Die genaue Konfiguration des Logwatch-Plugins ist nicht Thema dieses Artikels. Wichtig ist allerdings, dass Sie nach wie vor im Logwatch-Plugin selbst bereits eine möglichst gute Vorfilterung der Meldungen vornehmen und nicht einfach die kompletten Inhalte der Textdateien zur Event Console senden.
Bitte verwechseln Sie das nicht mit der nachträglichen Umklassifizierung über den Regelsatz Logfile patterns. Diese kann lediglich den Status von Meldungen ändern, die bereits vom Agenten gesendet wurden. Sollten Sie diese Patterns aber schon eingerichtet haben und möchten einfach nur von Logwatch auf die Event Console umstellen, so können Sie die Patterns beibehalten. Dazu gibt es bei den Regeln für die Weiterleitung (Logwatch Event Console Forwarding) die Option Reclassify messages before forwarding them to the EC.
In diesem Fall gehen alle Meldungen durch insgesamt drei Regelketten: auf dem Agenten, durch die Reklassifizierung und in der Event Console!
Stellen Sie Logwatch nun so um, dass die von den Plugins gefundenen Meldungen nicht mehr mit dem normalen Logwatch-Check überwacht, sondern einfach 1:1 in die Event Console weitergeleitet und dort verarbeitet werden. Dazu dient der Regelsatz Logwatch Event Console Forwarding:
Dazu einige Hinweise:
Falls Sie eine verteilte Umgebung haben, bei der nicht in jeder Instanz eine eigene Event Console läuft, müssen die Remote-Instanzen die Meldungen an die Zentralinstanz per Syslog weiterleiten.
Der Default dafür ist UDP.
Das ist aber kein abgesichertes Protokoll.
Besser ist, Sie verwenden Syslog via TCP, welches Sie allerdings in der Zentralinstanz aktivieren müssen (omd config).
Bei der Weiterleitung geben Sie eine beliebige Syslog facility an.
Anhand dieser können Sie in der EC dann leicht die weitergeleiteten Meldungen erkennen.
Gut geeignet sind dafür local0 bis local7.
Mit List of expected logfiles können Sie die Liste der gefundenen Log-Dateien überwachen lassen und werden so gewarnt, wenn bestimmte erwartete Dateien gar nicht gefunden werden.
Wichtig: Das Speichern der Regel alleine bewirkt noch nichts. Diese Regel wird lediglich bei der Service-Erkennung aktiv. Erst wenn Sie diese neu durchführen, werden die bisherigen Logwatch-Services entfernt, und anstelle dessen wird pro Host ein neuer Service mit dem Namen Log Forwarding erzeugt.

Dieser Check zeigt Ihnen später auch an, ob es beim Weiterleiten an die Event Console zu irgendwelchen Problemen kommen sollte.
8.1. Service-Level und Syslog-Priorität
Da weitergeleiteten Log-Dateien je nach verwendetem Format oft die Syslog-Klassifizierung fehlt, können Sie die Neu-Klassifizierung im Regelsatz Logwatch Event Console Forwarding unter Log Forwarding vornehmen. Zudem ist in den Regelsätzen, die Sie als Teil von Rule packs definieren, immer das individuelle Setzen von Status und Service-Level möglich.
9. Event-Status im aktiven Monitoring sehen
Wenn Sie auch im aktiven Monitoring sehen möchten, zu welchen Hosts aktuell problematische Events offen sind, können Sie pro Host einen aktiven Check hinzufügen lassen, welcher dessen aktuellen Event-Status zusammenfasst. Bei einem Host ohne offene Events sieht das dann so aus:

Sind nur Events im Zustand OK vorhanden, so zeigt der Check deren Anzahl, bleibt aber immer noch grün:

Hier ist ein Fall mit offenen Events im Zustand CRIT:

Diesen aktiven Check erzeugen Sie durch eine Regel im Regelsatz Check event state in Event Console. Dabei können Sie auch angeben, ob bereits quittierte Events noch zum Status beitragen sollen oder nicht:
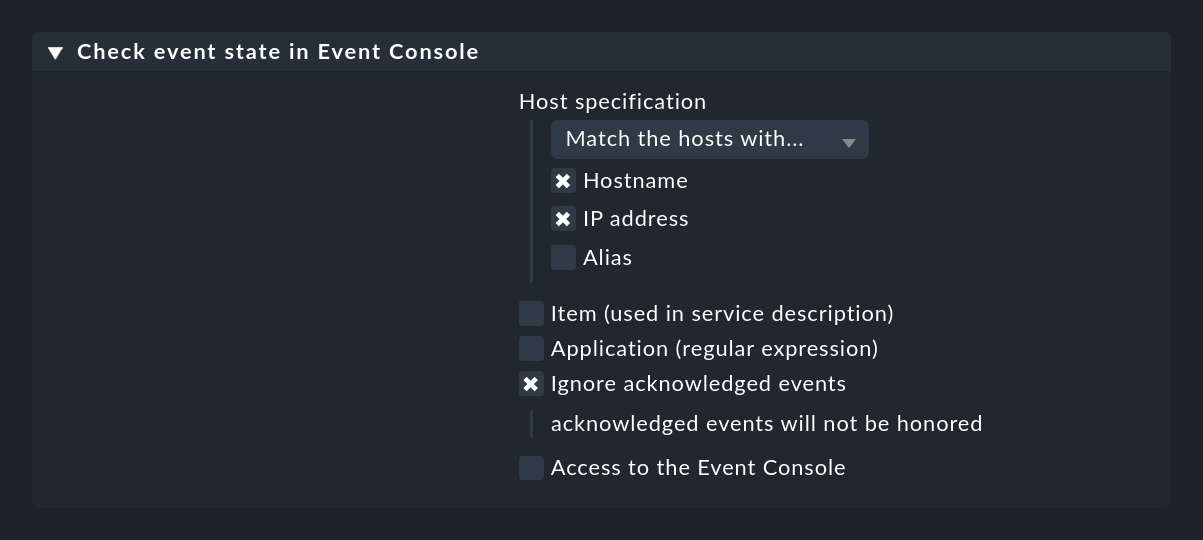
Über die Option Application (regular expression) können Sie den Check auf solche Events einschränken, die einen bestimmten Text im Anwendungsfeld haben. In diesem Fall kann es dann Sinn machen, mehr als einen Events-Check auf einem Host zu haben und die Checks nach Anwendungen zu trennen. Damit sich diese Services vom Namen unterscheiden, benötigen Sie dabei dann noch die Option Item (used in service description), welche einen von Ihnen festgelegten Text in den Namen des Services einbaut.
Falls Ihre Event Console nicht auf der gleichen Checkmk Instanz läuft, von der auch der Host überwacht wird, brauchen Sie unter Access to Event Console einen Remote-Zugriff per TCP:
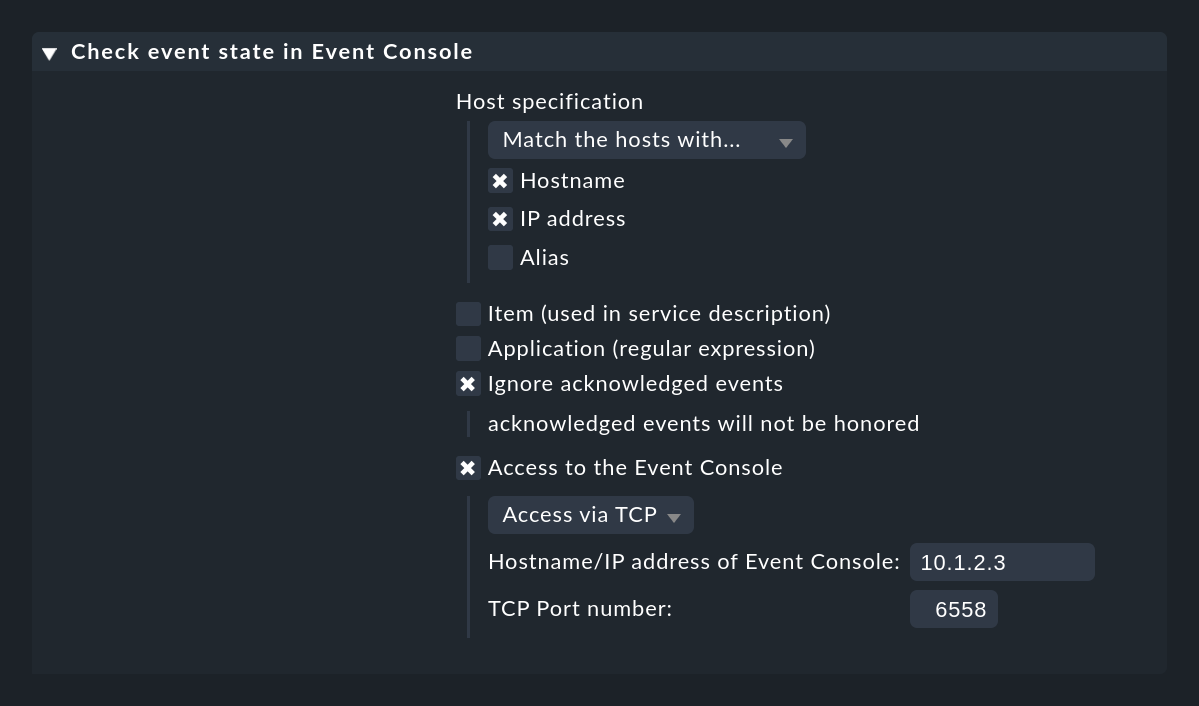
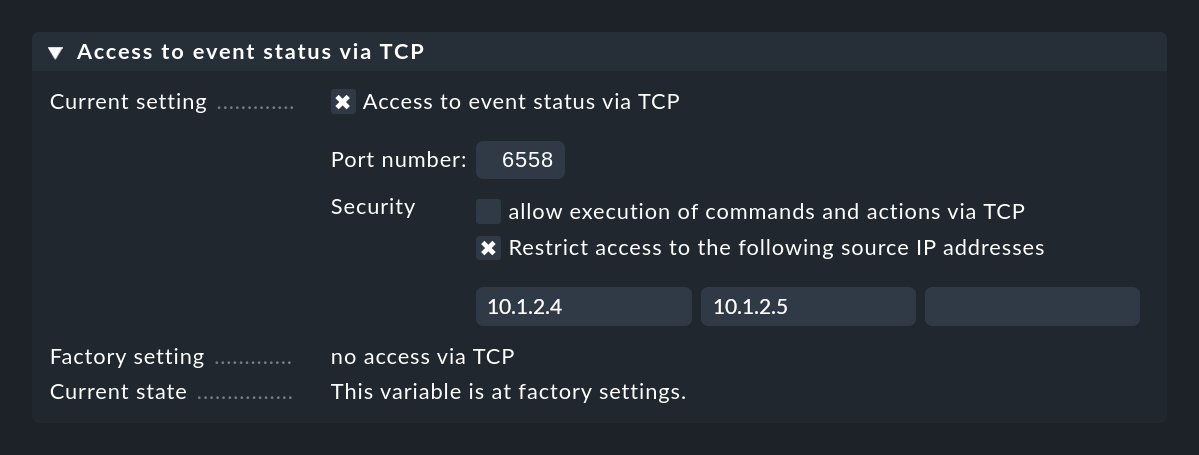
Damit dies funktioniert, muss die Event Console den Zugriff per TCP erlauben. Dies können Sie in den Einstellungen der Event Console konfigurieren, auf die zugegriffen werden soll:
10. Das Archiv
10.1. Funktionsweise
Die Event Console führt ein Protokoll von allen Änderungen, die ein Event durchläuft. Dieses finden Sie über zwei Wege:
In der globalen Ansicht Recent event history, die Sie in Monitor > Event Console finden.
Bei den Details eines Events mit dem Menüeintrag Event Console Event > History of Event.
In der globalen Ansicht greift ein Filter, der nur die Ereignisse der letzten 24 Stunden zeigt. Sie können die Filter aber wie gewohnt anpassen.
Folgende Abbildung zeigt die Historie von Event 33, welches insgesamt vier Änderungen erfahren hat.
Zuerst wurde das Event erzeugt (NEW),
dann der Zustand manuell von OK auf WARN geändert (CHANGESTATE),
dann wurde quittiert und ein Kommentar hinzugefügt (UPDATE) und
schließlich archiviert/gelöscht (DELETE):

Es gibt im Archiv folgende Aktionstypen, die in der Spalte Action angezeigt werden:
| Aktionstyp | Bedeutung |
|---|---|
|
Das Event wurde neu erzeugt (aufgrund einer Meldung oder aufgrund einer Regel, welche eine Meldung erwartet, die ausgeblieben ist). |
|
Das Event wurde durch den Operator editiert (Änderung an Kommentar, Kontaktinformation, Quittierung). |
|
Das Event wurde archiviert. |
|
Das Event wurde durch eine OK-Meldung automatisch aufgehoben. |
|
Der Zustand des Events wurde durch den Operator geändert. |
|
Das Event wurde automatisch archiviert, da keine Regel gegriffen hat und in den globalen Einstellungen Force message archiving aktiviert war. |
|
Das Event wurde automatisch archiviert, da, während es in der Phase counting war, die zugehörige Regel gelöscht wurde. |
|
Das Event wurde von counting nach open gesetzt, weil die konfigurierte Anzahl von Meldungen erreicht wurde. |
|
Das Event wurde automatisch archiviert, da in der Phase counting die erforderliche Anzahl von Meldungen nicht erreicht wurde. |
|
Das Event wurde automatisch archiviert, da, während es in der Phase counting war, die zugehörige Regel so umgestellt wurde, dass sie nicht mehr zählt. |
|
Das Event wurde geöffnet, da die in der Regel konfigurierte Verzögerung abgelaufen ist. |
|
Das Event wurde automatisch archiviert, da seine konfigurierte Lebenszeit abgelaufen ist. |
|
Eine E-Mail wurde versendet. |
|
Eine automatische Aktion (Skript) wurde ausgeführt. |
|
Das Event wurde direkt nach dem Öffnen sofort automatisch archiviert, da dies in der entsprechenden Regel so konfiguriert war. |
10.2. Speicherort des Archivs
Wie eingangs erwähnt, ist die Event Console nicht als vollwertiges Syslog-Archiv konzipiert.
Um die Implementierung und vor allem die Administration so einfach wie möglich zu halten, wurde auf ein Datenbank-Backend verzichtet.
Anstelle dessen wird das Archiv in simple Textdateien geschrieben.
Jeder Eintrag besteht aus einer Zeile Text, welche durch Tabulatoren getrennte Spalten enthält.
Sie finden die Dateien in ~/var/mkeventd/history:
OMD[mysite]:~$ ll var/mkeventd/history/
total 1328
-rw-rw-r-- 1 stable stable 131 Dez 4 23:59 1480633200.log
-rw-rw-r-- 1 stable stable 1123368 Dez 5 23:39 1480892400.log
-rw-rw-r-- 1 stable stable 219812 Dez 6 09:46 1480978800.logPer Default wird jeden Tag automatisch eine neue Datei begonnen. In den Einstellungen der Event Console können Sie die Rotation anpassen. Die Einstellung Event history logfile rotation ermöglicht das Umstellen auf eine wöchentliche Rotation.
Die Namen der Dateien entsprechen dem Unix-Zeitstempel vom Zeitpunkt der Erzeugung der Datei (Sekunden seit dem 1.1.1970 UTC).
Die Dateien werden 365 Tage aufbewahrt, sofern Sie das nicht in der Einstellung Event history lifetime umstellen. Zudem werden die Dateien auch vom zentralen Plattenplatzmanagement von Checkmk erfasst, welches Sie in den globalen Einstellungen unter Site management konfigurieren können. Dabei gilt die jeweils kürzere eingestellte Frist. Das globale Management hat den Vorteil, dass es automatisch bei Knappheit von Plattenplatz alle historischen Daten von Checkmk gleichmäßig beginnend mit den ältesten löschen kann.
Wenn Sie in Platzprobleme laufen sollten, können Sie die Dateien in dem Verzeichnis auch einfach von Hand löschen oder auslagern. Legen Sie jedoch keine gezippten oder irgendwelche anderen Dateien in diesem Verzeichnis ab.
10.3. Automatisches Archivieren
Trotz der Limitierung durch die Textdateien ist es theoretisch möglich, in der Event Console sehr viele Meldungen zu archivieren. Das Schreiben in die Textdateien des Archivs ist sehr performant — allerdings auf Kosten einer späteren Recherche. Da die Dateien als einzigen Index den Anfragezeitraum haben, müssen bei jeder Anfrage alle relevanten Dateien komplett gelesen und durchsucht werden.
Normalerweise wird die EC nur solche Meldungen ins Archiv schreiben, für die auch wirklich ein Event geöffnet wird. Sie können das auf zwei verschieden Arten auf alle Events ausweiten:
Sie erzeugen eine Regel, die auf alle (weiteren) Events matcht und aktiveren in Outcome & actions die Option Delete event immediately after the actions.
Sie aktivieren in den Einstellungen der Event Console den Schalter Force message archiving.
Letzterer sorgt dafür, dass Meldungen, auf die keine Regel greift, trotzdem ins Archiv wandern (Aktionstyp ARCHIVED).
11. Performance und Tuning
11.1. Verarbeitung von Meldungen
Auch in Zeiten, da Server 64 Kerne und 2 TB Hauptspeicher haben, spielt Performance von Software noch eine Rolle. Speziell bei der Verarbeitung von Events kommt hinzu, dass bei nicht ausreichender Leistung bei der Verarbeitung im Extremfall eingehende Meldungen verloren gehen können.
Der Grund ist, dass keines der verwendeten Protokolle (Syslog, SNMP-Traps, etc.) eine Flusskontrolle vorsieht. Wenn tausende Hosts gleichzeitig im Sekundentakt munter drauf los senden, dann hat der Empfänger keinerlei Chance, diese auszubremsen.
Deswegen ist es in etwas größeren Umgebungen wichtig, dass Sie ein Auge darauf haben, wie lang die Verarbeitungszeit für eine Meldung ist. Dies hängt natürlich ganz wesentlich davon ab, wie viele Regeln Sie definiert haben und wie diese aufgebaut sind.
Messen der Performance
Zum Messen Ihrer Performance gibt es ein eigenes Snapin für die Seitenleiste mit dem Namen Event Console Performance.
Dieses können Sie wie gewohnt mit ![]() einbinden:
einbinden:
Die hier dargestellten Werte sind Mittelwerte über etwa die letzte Minute. Einen Event-Sturm, der nur ein paar Sekunden dauert, können Sie hier also nicht direkt ablesen, aber dadurch sind die Zahlen etwas geglättet und daher besser zu lesen.
Um die maximale Performance zu testen, können Sie künstlich einen Sturm von unklassifizierten Meldungen erzeugen (bitte nur im Testsystem!), indem Sie z.B. in einer Shell-Schleife fortwährend den Inhalt einer Textdatei in die Events Pipe schreiben:
OMD[mysite]:~$ while true ; do cat /etc/services > tmp/run/mkeventd/events ; doneDie wichtigsten Messwerte aus dem Snapin haben folgende Bedeutung:
| Wert | Bedeutung |
|---|---|
Received messages |
Anzahl der aktuell pro Sekunde eingehenden Meldungen. |
Rule tries |
Anzahl der Regeln, die ausprobiert werden. Dies liefert wertvolle Informationen über die Effizienz der Regelkette — vor allem zusammen mit dem nächsten Parameter. |
Rule hits |
Anzahl der Regeln, die aktuell pro Sekunde greifen. Dies können auch Regeln sein, die Meldungen verwerfen oder einfach nur zählen. Daher resultiert nicht aus jedem Regeltreffer auch ein Event. |
Rule hit ratio |
Das Verhältnis aus Rule tries und Rule hits. Mit anderen Worten: Wie viele Regeln muss die EC ausprobieren, bis (endlich) eine greift. In dem Beispiel aus dem Screenshot ist die Rate bedenklich klein. |
Created events |
Anzahl der Events, die pro Sekunde neu erzeugt werden. Da die Event Console ja nur relevante Probleme anzeigen soll (also vergleichbar mit Host- und Service-Problemen aus dem Monitoring), wäre in der Praxis die Zahl |
Processing time per message |
Hier können Sie ablesen, wie viel Zeit denn nun die Verarbeitung einer Meldung gedauert hat. Vorsicht: Im allgemeinen ist dies nicht der Kehrwert zu Received messages. Denn dabei fehlen ja noch die Zeiten, in denen die Event Console gar nichts zu tun hatte, weil gerade keine Meldungen eingingen. Hier wird wirklich die reine real vergangene Zeit zwischen dem Eintreffen einer Meldung und dem endgültigen Abschluss der Verarbeitung gemessen. Sie können darin in etwa ablesen, wie viele Meldungen die EC pro Zeit maximal schaffen kann. Beachten Sie auch, dass es sich hier nicht um CPU-Zeit handelt, sondern um reale Zeit. Bei einem System mit genügend freien CPUs sind diese Zeiten etwa gleich. Sobald aber das System so unter Last ist, dass nicht alle Prozesse immer eine CPU bekommen, kann die reale Zeit deutlich höher werden. |
Tipps für das Tuning
Wie viele Meldungen die Event Console pro Sekunde verarbeiten kann, können Sie in etwa an der Processing time per message ablesen. Generell hängt diese Zeit damit zusammen, wie viele Regeln probiert werden müssen, bis eine Meldung verarbeitet wird. Sie haben verschiedene Möglichkeiten, hier zu optimieren:
Regeln, die sehr viele Meldungen ausschließen, sollten möglichst weit am Anfang der Regelkette stehen.
Arbeiten Sie mit Regelpaketen, um Sätze von verwandten Regeln zusammenzufassen. Die erste Regel in jedem Paket sollte das Paket sofort verlassen, wenn die gemeinsame Grundbedingung nicht erfüllt ist.
Weiterhin gibt es in der EC eine Optimierung, die auf der Syslog-Priorität und -Facility basiert. Dazu wird für jede Kombination von Priorität und Facility intern eine eigene Regelkette gebildet, in die jeweils nur solche Regeln aufgenommen werden, die für Meldungen dieser Kombination relevant sind.
Jede Regel, die eine Bedingung auf die Priorität, die Facility oder am besten auf beides enthält, kommt dann nicht mehr in alle diese Regelketten, sondern optimalerweise nur in eine einzige. Das bedeutet, dass diese Regel bei Meldungen mit einer anderen Syslog-Klassifizierung gar nicht überprüft werden muss.
Im ~/var/log/mkeventd.log sehen Sie nach einem Neustart eine Übersicht der optimierten Regelketten:
[8488808306.233330] kern : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233343] user : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233355] mail : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233367] daemon : emerg(120) alert(89) crit(89) err(89) warning(89) notice(89) info(89) debug(89)
[8488808306.233378] auth : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233389] syslog : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233408] lpr : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233482] news : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233424] uucp : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233435] cron : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233446] authpriv : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233457] ftp : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233469] (unused 12) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233480] (unused 13) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233498] (unused 13) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233502] (unused 14) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233589] local0 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233538] local1 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233542] local2 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233552] local3 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233563] local4 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233574] local5 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233585] local6 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233595] local7 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233654] snmptrap : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)In obigem Beispiel sehen Sie, dass es 67 Regeln gibt, die in jedem Fall geprüft werden müssen.
Bei Meldungen der Facility daemon sind 89 Regeln relevant, nur bei der Kombination daemon/emerg müssen 120 Regeln geprüft werden.
Jede Regel, die eine Bedingung auf Priorität oder Facility bekommt, reduziert die Anzahl von 67 weiter.
Natürlich können Sie diese Bedingungen nur dann setzen, wenn Sie sicher sind, dass sie von den relevanten Meldungen auch erfüllt werden!
11.2. Anzahl aktueller Events
Auch die Anzahl der aktuell vorhandenen Events kann die Performance der EC beeinflussen — und zwar, wenn diese deutlich aus dem Ruder läuft. Wie bereits erwähnt, sollte die EC nicht als Ersatz für ein Syslog-Archiv gesehen werden, sondern lediglich „aktuelle Probleme“ anzeigen. Die Event Console kann zwar durchaus mit mehreren tausend Problemen umgehen, aber der eigentliche Sinn ist das nicht.
Sobald die Anzahl der aktuellen Events etwa 5 000 übersteigt, beginnt die Performance spürbar schlechter zu werden. Das zeigt sich zum einen in der GUI, die langsamer auf Anfragen reagiert. Zum anderen wird auch die Verarbeitung langsamer, da in manchen Situationen Meldungen mit allen aktuellen Events verglichen werden müssen. Auch der Speicherbedarf kann problematisch werden.
Die Event Console hält aus Gründen der Performance alle aktuellen Events stets im RAM.
Diese werden einmal pro Minute (einstellbar) und beim sauberen Beenden in die Datei ~/var/mkeventd/status geschrieben.
Wenn diese sehr groß wird (z.B. über 50 Megabyte), wird dieser Vorgang ebenfalls immer langsamer.
Die aktuelle Größe können Sie schnell mit ll abfragen (Alias für ls -alF):
OMD[mysite]:~$ ll -h var/mkeventd/status
-rw-r--r-- 1 mysite mysite 386K Dez 14 13:46 var/mkeventd/statusSollten Sie aufgrund einer ungeschickten Regel (z.B. einer, die auf alles matcht) viel zu viele aktuelle Events haben, ist ein manuelles Löschen über die GUI kaum noch sinnvoll zu schaffen. In diesem Fall hilft einfach ein Löschen der Statusdatei:
OMD[mysite]:~$ omd stop mkeventd
Stopping mkeventd...killing 17436......OK
OMD[mysite]:~$ rm var/mkeventd/status
OMD[mysite]:~$ omd start mkeventd
Starting mkeventd (builtin: syslog-udp)...OKAchtung: Natürlich gehen dabei alle aktuellen Events verloren sowie die gespeicherten Zählerstände und andere Zustände. Insbesondere beginnen neue Events dann wieder mit der ID 1.
Automatischer Überlaufschutz
Die Event Console besitzt einen automatischen Schutz vor einem „Überlaufen“. Dieser limitiert die Anzahl von aktuellen Events pro Host, pro Regel und global. Dabei werden nicht nur offene Events gezählt, sondern auch solche in anderen Phasen, wie z.B. delayed oder counting. Archivierte Events werden nicht gezählt.
Dies schützt Sie in Situationen, in denen aufgrund eines systematischen Problems in Ihrem Netzwerk Tausende von kritischen Events hereinströmen und die Event Console „dicht“ machen würde. Zum einen verhindert das Performance-Einbrüche der Event Console, die zu viele Events im Hauptspeicher halten müsste. Zum anderen bleibt so die Übersicht für den Operator (einigermaßen) bewahrt und Events, die nicht Teil des Sturms sind, bleiben sichtbar.
Sobald ein Limit erreicht ist, geschieht eine der folgenden Aktionen:
Das Erzeugen neuer Events wird gestoppt (für diesen Host, diese Regel bzw. global).
Das Gleiche, aber zusätzlich wird ein „Overflow Event“ erzeugt.
Das Gleiche, aber zusätzlich werden passende Kontaktpersonen benachrichtigt.
Alternativ zu obigen drei Varianten können Sie auch das jeweils älteste Event löschen lassen, um Platz für das Neue zu machen.
Die Limits sowie die verknüpfte Auswirkung beim Erreichen stellen Sie in den Einstellungen der Event Console mit Limit amount of current events ein. Folgende Abbildung zeigt die Voreinstellung:
Falls Sie einen Wert mit …create overflow event aktiviert haben, wird beim Erreichen des Limits ein künstliches Event erzeugt, das den Operator von der Fehlersituation in Kenntnis setzt:
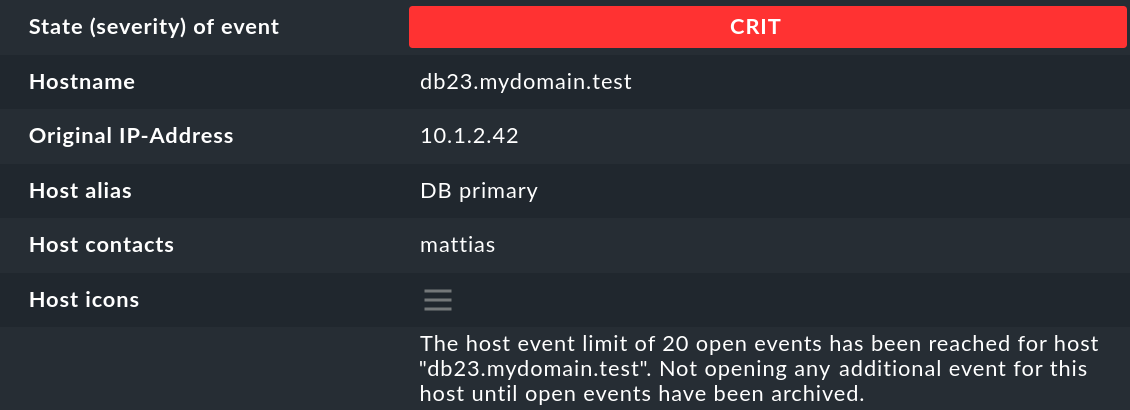
Falls Sie zusätzlich einen Wert mit …notify contacts aktiviert haben, werden passende Kontaktpersonen per Checkmk Benachrichtigung informiert. Die Benachrichtigung durchläuft die Benachrichtigungsregeln von Checkmk. Diese Regeln müssen sich nicht unbedingt an die Kontaktauswahl der Event Console halten, sondern können diese modifizieren. Folgende Tabelle zeigt, welche Kontakte ausgewählt werden, falls Sie Notify all contacts of the notified host or service eingestellt haben (was der Default ist):
| Limit | Kontaktauswahl |
|---|---|
pro Host |
Die Kontakte zum Host, welche genauso ermittelt werden, wie bei der Benachrichtigung von Events über Checkmk. |
pro Regel |
Hier wird das Feld für den Host-Namen leer gelassen. Falls in der Regel Kontaktgruppen definiert sind, werden diese ausgewählt, ansonsten die Fallback-Kontakte. |
Global |
Die Fallback-Kontakte. |
11.3. Zu großes Archiv
Wie oben gezeigt, hat die Event Console ein Archiv von allen Events und deren Verarbeitungsschritten. Dieses ist aus Gründen der einfachen Implementierung und Administration in Textdateien abgelegt.
Textdateien sind beim Schreiben von Daten in der Performance schwer zu übertreffen — von Datenbanken beispielsweise nur mit enormem Optimierungsaufwand. Das liegt unter anderem an der Optimierung dieser Zugriffsart durch Linux und der kompletten Speicherhierarchie von Platten und SANs. Dies geht allerdings zulasten der Lesezugriffe. Da Textdateien über keinen Index verfügen, ist für das Suchen in den Dateien ein komplettes Einlesen notwendig.
Die Event Console verwendet als Index für die Zeit der Ereignisse zumindest die Dateinamen der Log-Dateien. Je weiter Sie den Anfragezeitraum eingrenzen, desto schneller geht also die Suche.
Sehr wichtig ist trotzdem, dass Ihr Archiv nicht zu groß wird. Wenn Sie die Event Console nur dazu verwenden, wirkliche Fehlermeldungen zu verarbeiten, kann das eigentlich nicht passieren. Sollten Sie versuchen, die EC als Ersatz für ein echtes Syslog-Archiv einzusetzen, kann dies allerdings zu sehr großen Dateien führen.
Wenn Sie in eine Situation geraten, in der Ihr Archiv zu groß geworden ist, können Sie einfach ältere Dateien in ~/var/mkeventd/history/ löschen.
Auch können Sie in Event history lifetime die Lebenszeit der Daten generell begrenzen, so dass das Löschen in Zukunft voreingestellt ist.
Per Default wird 365 Tage gespeichert.
Vielleicht kommen Sie ja mit deutlich weniger aus.
11.4. Performance über die Zeit messen
Checkmk startet automatisch für jede laufende Instanz der Event Console einen Service, der die Leistungsdaten in Kurven aufzeichnet und Sie auch warnt, wenn es zu Überläufen kommt.
Sofern Sie auf dem Monitoring-Server einen Linux-Agenten installiert haben, wird der Check wie gewohnt automatisch gefunden und eingerichtet:

Der Check bringt sehr viele interessante Messarten mit, z.B. die Anzahl der eingehenden Meldungen pro Zeit und wie viele davon verworfen wurden:
Die Effizienz Ihrer Regelkette wird dargestellt durch einen Vergleich von ausprobierten Regeln zu solchen, die gegriffen haben:
Dieser Graph zeigt die durchschnittliche Zeit für die Verarbeitung einer Meldung:
Daneben gibt es noch etliche weitere Diagramme.
12. Verteiltes Monitoring
Wie Sie die Event Console in einer Installation mit mehreren Checkmk Instanzen einsetzen, erfahren Sie im Artikel über das verteilte Monitoring.
13. Die Statusschnittstelle
Die Event Console bietet über das Unix-Socket ~/tmp/run/mkeventd/status sowohl Zugriff auf den internen Status als auch die Möglichkeit, Kommandos auszuführen.
Das hier verwendete Protokoll ist eine stark eingeschränkte Teilmenge von Livestatus.
Auf diese Schnittstelle greift der Monitoring-Kern zu und reicht die Daten an die GUI durch, um so ein verteiltes Monitoring auch für die Event Console zu ermöglichen.
Für den vereinfachten Livestatus der Event Console gelten folgende Einschränkungen:
Die einzigen erlaubten Header sind
Filter:undOutputFormat:.Daher ist kein KeepAlive möglich, pro Verbindung ist nur eine Anfrage durchführbar.
Folgende Tabellen sind verfügbar:
|
Liste aller aktuellen Events. |
|
Zugriff auf das Archiv. Eine Anfrage auf diese Tabelle führt zum Zugriff auf die Textdateien des Archivs. Verwenden Sie auf jeden Fall einen Filter über die Zeit des Eintrags, um einen Vollzugriff auf alle Dateien zu vermeiden. |
|
Status- und Performancewerte der EC. Diese Tabelle hat immer genau eine Zeile. |
Kommandos können Sie mithilfe von unixcat mit einer sehr einfachen Syntax in das Socket schreiben:
OMD[mysite]:~$ echo "COMMAND RELOAD" | unixcat tmp/run/mkeventd/statusFolgende Kommandos sind verfügbar:
|
Archiviert ein Event. Argumente: Event-ID und Benutzerkürzel. |
|
Neuladen der Konfiguration. |
|
Beendet die Event Console. |
|
Die Log-Datei wird neu geöffnet. Dieses Kommando wird von der Log-Dateirotation benötigt. |
|
Löscht alle aktuellen und archivierten Events. |
|
Löst ein sofortiges Aktualisieren der Datei |
|
Setzt die Trefferzähler der Regeln zurück (entspricht dem Menüeintrag Event Console > Reset counters in der Setup-GUI). |
|
Führt ein Update von einem Event aus. Die Argumente sind der Reihe nach Event-ID, Benutzerkürzel, Quittierung (0/1), Kommentar und Kontaktinformation. |
|
Ändert den Status OK / WARN / CRIT / UNKNOWN eines Events. Argumente sind Event-ID, Benutzerkürzel und Statusziffer ( |
|
Führt eine benutzerdefinierte Aktion auf einem Event aus. Argumente sind Event-ID, Benutzerkürzel und Aktions-ID. Die spezielle ID |
14. Dateien und Verzeichnisse
| Pfad | Bedeutung |
|---|---|
|
Arbeitsverzeichnis des Event Daemons. |
|
Kompletter aktueller Zustand der Event Console. Dies umfasst vor allem alle aktuell offenen Events (und solche in Übergangsphasen wie counting etc.). Im Falle einer Fehlkonfiguration, die zu sehr vielen offenen Events führt, kann diese Datei riesig werden und die Performance der EC drastisch reduzieren. In diesem Fall können Sie den Dienst |
|
Ablageort des Archivs. |
|
Log-Datei der Event Console. |
|
Die globalen Einstellungen der Event Console in Python-Syntax. |
|
Ihre ganzen konfigurierten Regelpakete und Regeln in Python-Syntax. |
|
Eine Named Pipe, in die Sie mit |
|
Ein Unix-Socket, das die gleiche Aufgabe wie die Pipe erfüllt, aber ein gleichzeitiges Schreiben mehrerer Anwendungen ermöglicht. Zum Hineinschreiben benötigen Sie den Befehl |
|
Die aktuelle Prozess-ID des Event Daemons während dieser läuft. |
|
Ein Unix-Socket, das die Abfrage des aktuellen Status und das Senden von Kommandos erlaubt. Die Anfragen der GUI gehen zunächst zum Monitoring-Kern, der dann auf diesen Socket zugreift. |
|
Von Ihnen hochgeladene MIB-Dateien für die Übersetzung von SNMP-Traps. |