This is a machine translation based on the English version of the article. It might or might not have already been subject to text preparation. If you find errors, please file a GitHub issue that states the paragraph that has to be improved. |
1. Introduction
1.1. Les événements ne sont pas des états
La tâche principale de Checkmk est la surveillance active des états.À tout moment, chaque service surveillé possède l'un des états suivants : OK, WARN, CRIT ou UNKNOWN. Par le biais d'une interrogation régulière, la surveillance met constamment à jour son image de la situation actuelle.
Un type de surveillance complètement différent est celui qui traite les événements. Un exemple d'événement est une exception qui se produit dans une application. L'application peut rester dans l'état OK et continuer à fonctionner correctement - mais quelque chose s'est produit.
1.2. L'Event Console
Avec l'Event Console (EC en abrégé), Checkmk fournit un système entièrement intégré pour la surveillance des événements provenant de sources telles que syslog, les traps SNMP, les journaux d'événements Windows, les fichiers journaux et les propres applications. Les événements ne sont pas simplement définis comme des états, mais ils forment une catégorie à part entière et sont en fait affichés comme des informations distinctes par Checkmk dans la barre latérale Overview.
En interne, les événements ne sont pas traités par le noyau de surveillance, mais par un service distinct - le daemon d'événements (mkeventd).
La console d'événements dispose également d'une archive dans laquelle vous pouvez rechercher des événements passés. Toutefois, il convient de préciser d'emblée qu'elle ne remplace pas une véritable archive de journaux. La tâche de la console d'événements consiste à filtrer intelligemment un petit nombre de messages pertinents à partir d'un flux important. Elle est optimisée pour la simplicité, la robustesse et le débit - et non pour le stockage de gros volumes de données.
Voici un bref aperçu des fonctionnalités de la console d'événements :
Il peut recevoir des messages directement via syslog ou des trap SNMP, ce qui rend inutile la configuration des services système Linux correspondants.
Il peut également évaluer les fichiers journaux en mode texte et les journaux d'événements Windows à l'aide des agents Checkmk.
Il classe les messages en fonction de chaînes de règles définies par l'utilisateur.
Il peut corréler, résumer, compter, annoter et réécrire les messages, ainsi que prendre en compte leurs relations temporelles.
Il peut effectuer des actions automatisées et envoyer des notifications via Checkmk.
Il est entièrement intégré à l'interface utilisateur de Checkmk.
Il est inclus et prêt à être utilisé dans n'importe quelle version actuelle du système Checkmk.
1.3. Terminologie
La console d'événements reçoit des messages (principalement sous la forme de messages de journal). Un message est une ligne de texte avec un certain nombre d'attributs supplémentaires possibles, par exemple un horodatage, un nom d'hôte, etc. Si le message est pertinent, il peut être converti directement en événement avec les mêmes attributs, mais :
Un message ne sera transformé en événement que si une règle prend effet.
Les règles peuvent modifier le texte et d'autres attributs des messages.
Plusieurs messages peuvent être combinés en un seul événement.
Les messages peuvent également annuler des événements en cours.
Des événements artificiels peuvent être générés si certains messages n'apparaissent pas.
Un événement peut passer par un certain nombre de phases:
Ouvert |
L'état "normal" : Quelque chose s'est produit : l'opérateur doit s'en occuper. |
Confirmé |
L'accuser réception d'un incident est analogue aux problèmes d'hôte et de service dans le cadre de la surveillance basée sur l'état. |
Comptage |
Le nombre requis de messages spécifiés n'est pas encore arrivé : la situation n'est pas encore problématique. L'événement n'est donc pas encore affiché à l'opérateur. |
Retardé |
Un message d'erreur a été reçu, mais l'Event Console attend encore que le message OK approprié soit reçu dans un délai configuré. Ce n'est qu'à ce moment-là que l'événement sera affiché à l'opérateur. |
Fermé |
L'événement a été clôturé par l'opérateur ou automatiquement par le système et ne se trouve plus que dans les archives. |
Un événement a également un état,mais il ne s'agit pas à proprement parler de l'état de l'événement lui-même, mais plutôt de l'état du service ou du dispositif qui a envoyé l'événement. Par analogie avec la surveillance basée sur l'état, un événement peut également être marqué comme OK, WARN, CRIT ou UNKNOWN.
2. Configuration de l'Event Console
La configuration de l'Event Console est très simple, car l'Event Console fait partie intégrante de Checkmk et est activée automatiquement.
Toutefois, si vous souhaitez recevoir des messages syslog ou des trap SNMP sur le réseau, vous devez les activer séparément. En effet, les deux services doivent ouvrir un port UDP avec un numéro de port spécifiquement identifié. Et comme seule une instance de Checkmk par système peut le faire, la réception sur le réseau est désactivée par défaut.
Les numéros de port sont les suivants :
| Protocole | Port | Service |
|---|---|---|
UDP |
162 |
Traps SNMP |
UDP |
514 |
Syslog |
TCP |
514 |
Syslog via TCP |
Syslog via TCP est rarement utilisé, mais il présente l'avantage de sécuriser la transmission des messages. Avec UDP, il n'est jamais possible de garantir que les paquets arriveront effectivement. De plus, ni Syslog ni les traps SNMP n'offrent de confirmation ou de protection similaire contre les messages perdus. Pour pouvoir utiliser syslog via TCP, le système d'envoi doit bien entendu pouvoir envoyer des messages via ce port.
Dans le périphérique Checkmk, vous pouvez activer la réception de syslog/SNMP traps dans la configuration du site. Sinon, utilisez simplement omd config. Vous trouverez le paramètre requis sous Addons:
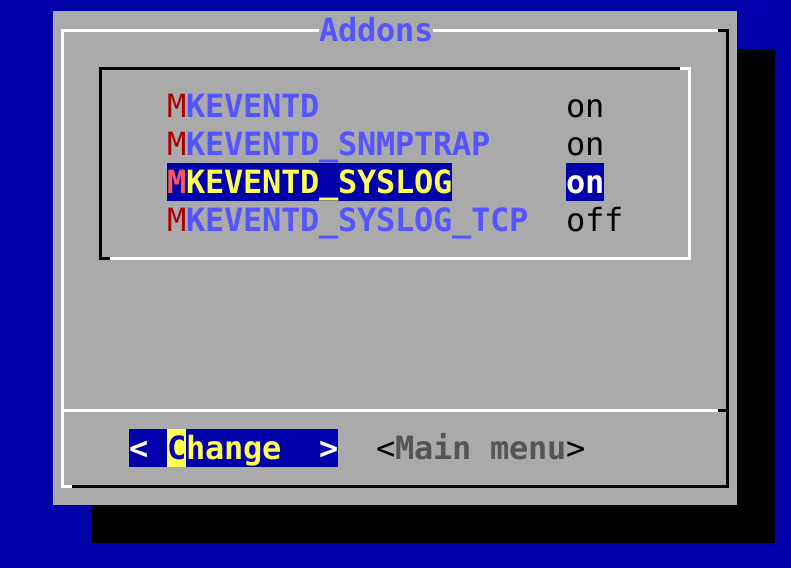
Sur omd start, vous pouvez voir sur la ligne contenant mkeventd quelles sont les interfaces externes ouvertes dans votre CE :
OMD[mysite]:~$ omd start
Creating temporary filesystem /omd/sites/mysite/tmp...OK
Starting mkeventd (builtin: syslog-udp,snmptrap)...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
Initializing Crontab...OK3. Les premiers pas avec l'Event Console
3.1. Règles, règles, règles
Il a été mentionné au début que la CE est utilisée pour repérer et afficher les messages pertinents. Cependant, le fait est que la plupart des messages - qu'ils proviennent de fichiers texte, du journal des événements de Windows ou du syslog - sont plutôt insignifiants. Cela n'aide pas non plus lorsque les messages ont déjà été pré-classifiés par leur auteur.
Par exemple, dans Syslog et dans le journal des événements de Windows, les messages sont classés comme OK, WARN et CRIT. Mais ce que WARN et CRIT signifient réellement peut être défini subjectivement par leur programmeur. Et on ne peut même pas affirmer avec certitude que l'application qui a produit le message est importante sur cet ordinateur. En bref : vous ne pouvez pas contourner la nécessité de configurer les messages qui vous semblent être un véritable problème et ceux qui peuvent simplement être écartés.
Comme partout dans Checkmk, la configuration s'effectue au moyen de règles, qui sont traitées par le CE pour chaque message entrant selon le principe de la "première saisie". La première règle appliquée à un message entrant décide de son sort. Si aucune règle n'est appliquée, le message sera simplement rejeté en silence.
Étant donné qu'au fil du temps, on accumule généralement de très nombreuses règles pour la CE, celles-ci sont organisées en paquets. Le traitement des règles s'effectue paquet par paquet et, au sein d'un paquet, de haut en bas - l'ordre de traitement de ces paquets est donc important.
3.2. Création d'une règle simple
Il n'est pas surprenant que l'interface de configuration du CE se trouve dans le menu Setup, sous Events > Event Console. Dans la case, vous ne trouverez que le module Default rule pack, qui ne contient en fait aucune règle. Les messages entrants sont donc, comme nous l'avons déjà mentionné, rejetés et ne sont pas non plus enregistrés. Le module lui-même se présente de la manière suivante :
Commencez par créer un nouveau paquet de règles avec Add rule pack:
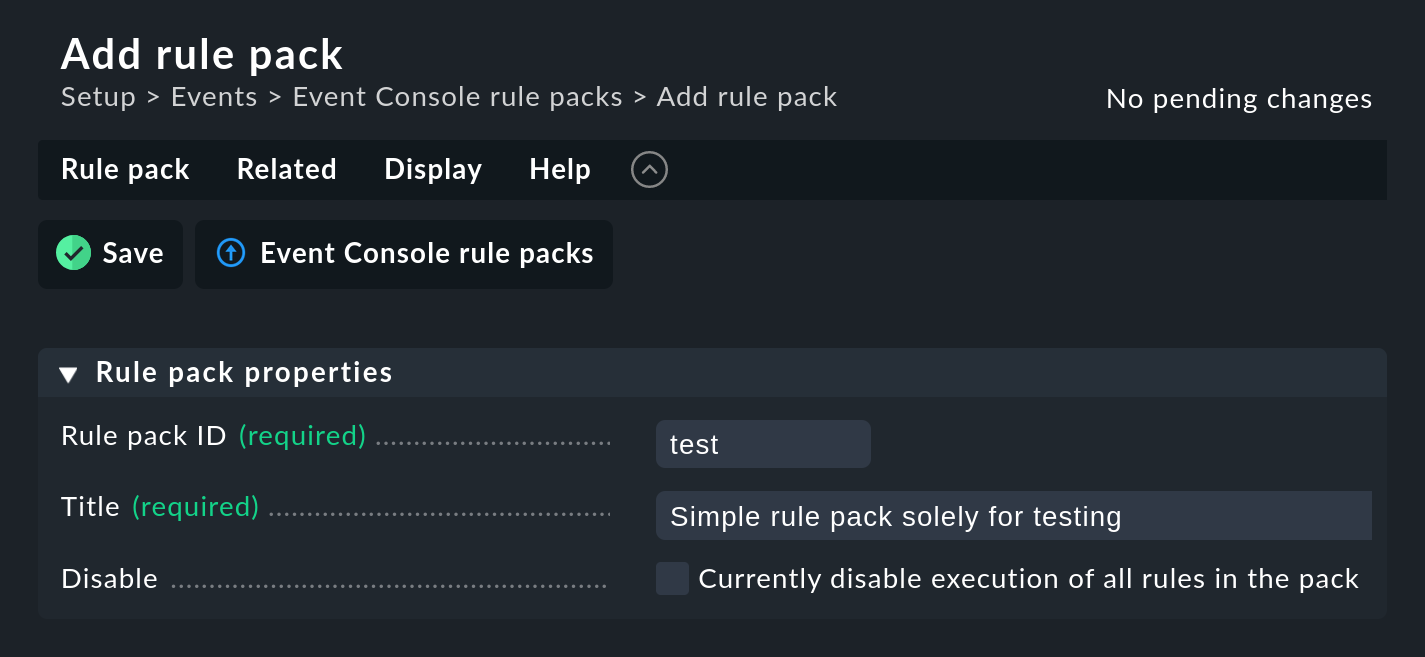
Comme toujours, l'ID est une référence interne et ne peut être modifié ultérieurement. Après avoir sauvegardé, vous trouverez le nouvel élément dans la liste de vos paquets de règles :
Vous pouvez maintenant passer au paquet de règles encore vide avec et créer une nouvelle règle avec Add rule. Remplissez uniquement la première case avec l'intitulé Rule Properties:
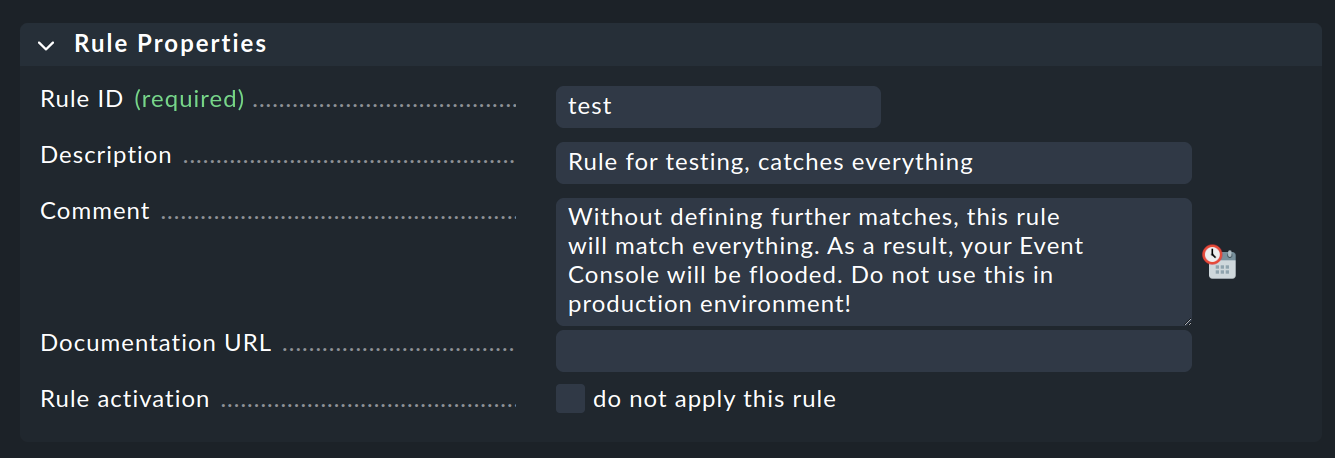
La seule chose nécessaire est un identifiant unique Rule ID. Cet identifiant sera retrouvé plus tard dans les fichiers journaux, et il sera stocké avec les événements générés. Il est donc judicieux d'attribuer systématiquement des noms significatifs aux identifiants. Toutes les autres cases sont facultatives. C'est particulièrement vrai pour les conditions.
Important : cette nouvelle règle n'est qu'un exemple pour les tests et s'appliquera à tous les événements. Il est donc également important que vous la supprimiez ultérieurement ou que vous la désactiviez au moins, sinon votre Event Console sera inondée de tous les messages inutiles imaginables et ne servira pratiquement à rien !
Activer les modifications
Comme toujours dans Checkmk, vous devez d'abord activer les modifications pour qu'elles prennent effet. Ce n'est pas un inconvénient, car de cette façon, pour les modifications qui affectent plusieurs règles liées, vous pouvez spécifier exactement quand les règles doivent être mises en ligne. Et avant cela, vous pouvez utiliser le site Event Simulator pour tester si tout va comme prévu.
Tout d'abord, cliquez sur le nombre de modifications accumulées en haut à droite de la page.
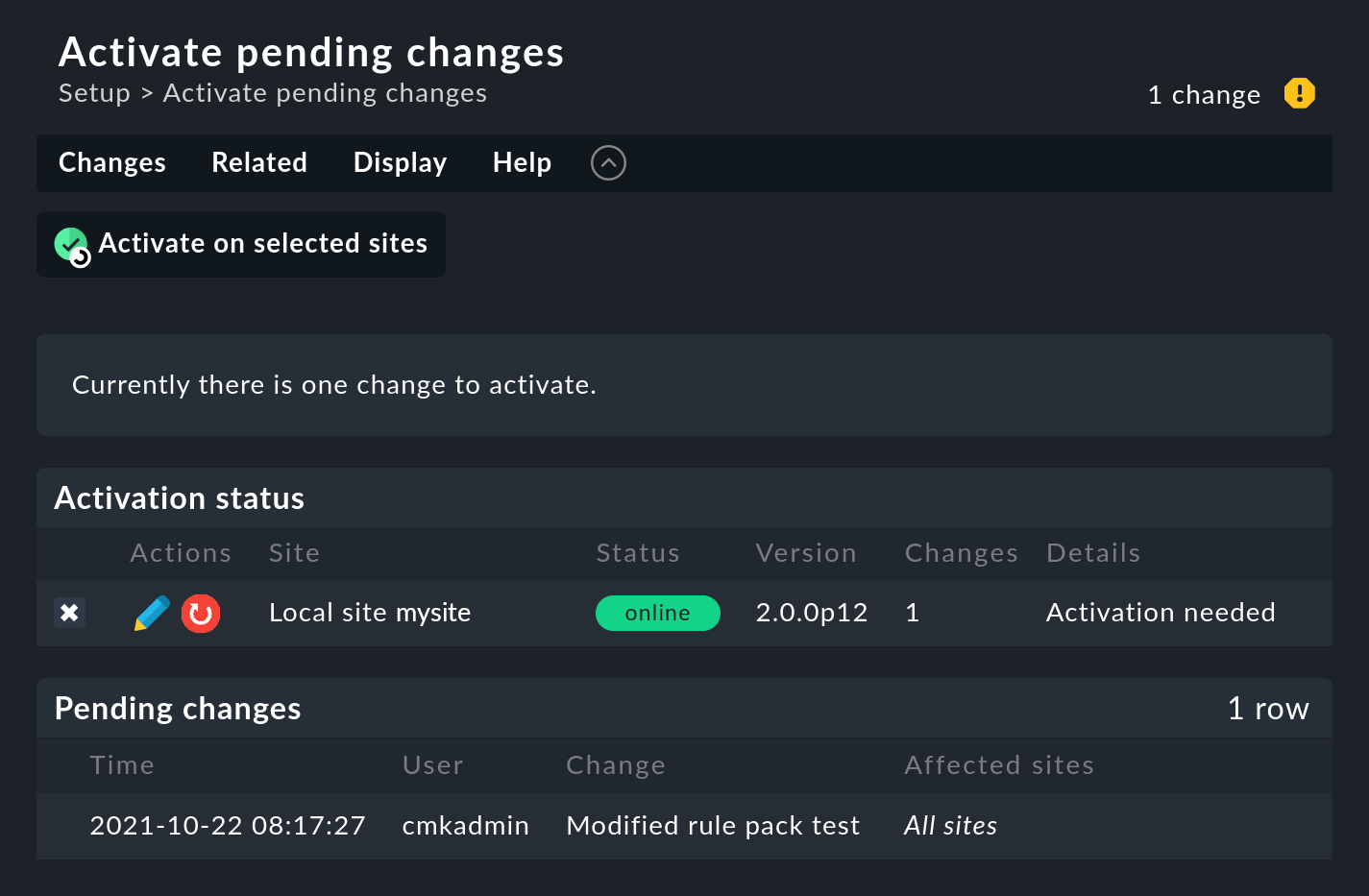
Cliquez ensuite sur Activate on selected sites pour activer les modifications. L'Event Console est conçue de manière à ce que cette action se déroule sans interruption. La réception des messages entrants est assurée à tout moment, de sorte qu'aucun message ne peut être perdu au cours du processus.
Seuls les administrateurs sont autorisés à activer les modifications dans la CE, ce qui est contrôlé par l'autorisation Activate changes for event console.
Test de la nouvelle règle
Pour les tests, vous pourriez bien sûr envoyer des messages via Syslog ou SNMP. Vous devriez également le faire plus tard. Mais pour un premier test, l'adresse Event Simulator intégrée à la CE est plus pratique :
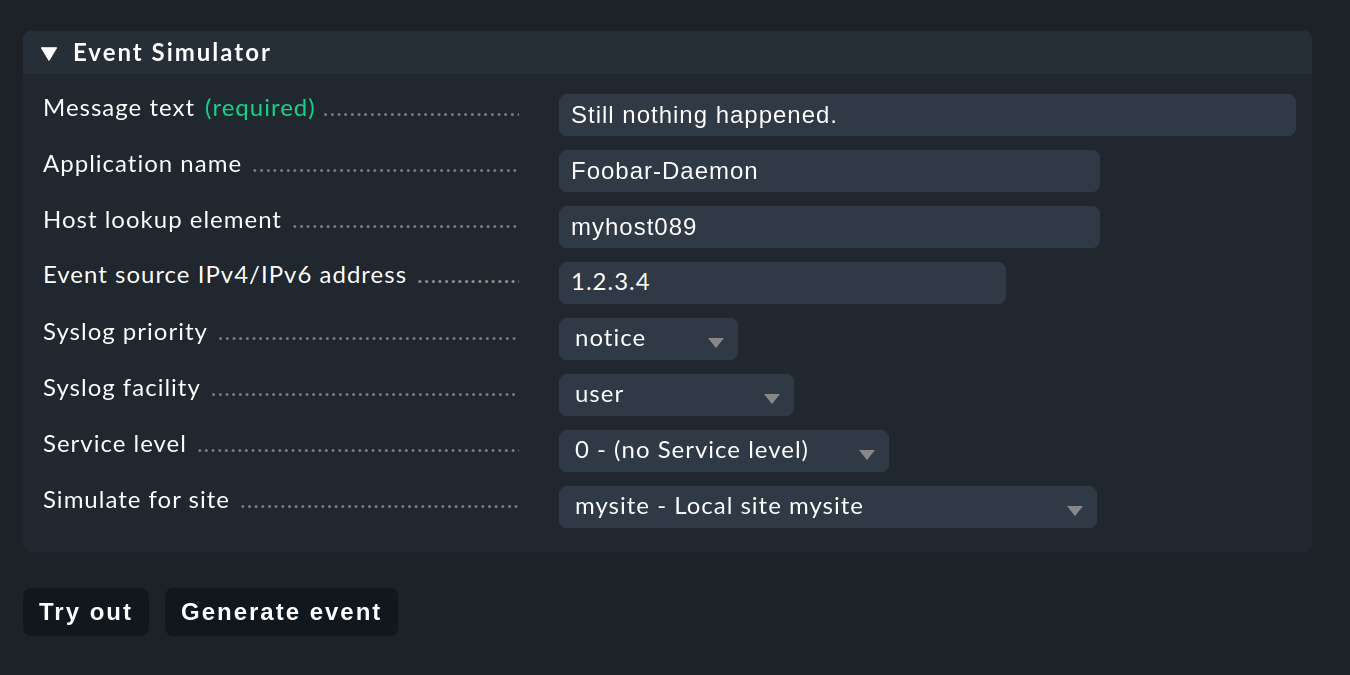
Ici, vous avez deux options :Try out évalue, sur la base du message simulé, laquelle des règles pourrait être saisie. Si vous vous trouvez au niveau supérieur de l'interface graphique de configuration du CE, les ensembles de règles sont mis en évidence. Si vous vous trouvez à l'intérieur d'un ensemble de règles, les règles individuelles sont mises en évidence. Chaque ensemble ou règle est marqué par l'un des trois symboles suivants :
Cette règle est la première à prendre effet sur le message et détermine donc son sort. |
|
Cette règle prendrait effet, mais le message a déjà été traité par une règle antérieure. |
|
Cette règle ne prend pas effet. Très pratique : Si vous passez la souris sur la boule grise, vous obtenez une explication sur la raison pour laquelle la règle ne s'applique pas. |
En cliquant sur Generate event, vous obtenez à peu près le même résultat que sur Try out, à ceci près que le message est effectivement généré.Toutes les actions définies sont exécutées. L'événement apparaît alors également dans les événements ouverts de la surveillance. Vous pouvez voir le code source du message généré dans la confirmation :

L'événement généré apparaît dans le menu Monitor sous Event Console > Events:

Génération manuelle de messages pour les tests
Pour un premier test réel sur le réseau, vous pouvez facilement envoyer un message syslog à partir d'un autre ordinateur Linux à la main. Puisque le protocole est si simple, vous n'avez même pas besoin d'un programme spécial, vous pouvez simplement envoyer les données via netcat ou nc en utilisant UDP. Le contenu du paquet UDP consiste en une seule ligne de texte. Si cela est conforme à une structure spécifique, l'Event Console décompose les composants proprement :
user@host:~$ echo '<78>Dec 18 10:40:00 myserver123 MyApplication: It happened again.' | nc -w 0 -u 10.1.1.94 514Mais vous pouvez aussi simplement envoyer n'importe quoi. La CE l'acceptera alors de toute façon et l'évaluera simplement comme un texte de message. Des informations supplémentaires telles que l'application, la priorité, etc. seront bien sûr manquantes. Pour des raisons de sécurité, l'état CRIT sera supposé :
user@host:~$ echo 'This is no syslog message' | nc -w 0 -u 10.1.1.94 514Dans l'instance Checkmk qui exécute la CE, il existe un tuyau nommé, dans lequel vous pouvez écrire des messages texte localement via echo. Il s'agit d'une méthode très simple pour connecter une application locale et également d'un moyen de tester le traitement des messages :
OMD[mysite]:~$ echo 'Local application says hello' > tmp/run/mkeventd/eventsD'ailleurs, il est également possible d'envoyer des messages au format syslog, de sorte que tous les champs des données d'événement soient remplis proprement.
3.3. Paramètres de l'Event Console
L'Event Console possède ses propres paramètres globaux, qui ne se trouvent pas avec ceux des autres modules, mais plutôt sous Setup > Events > Event Console avec le bouton Settings.
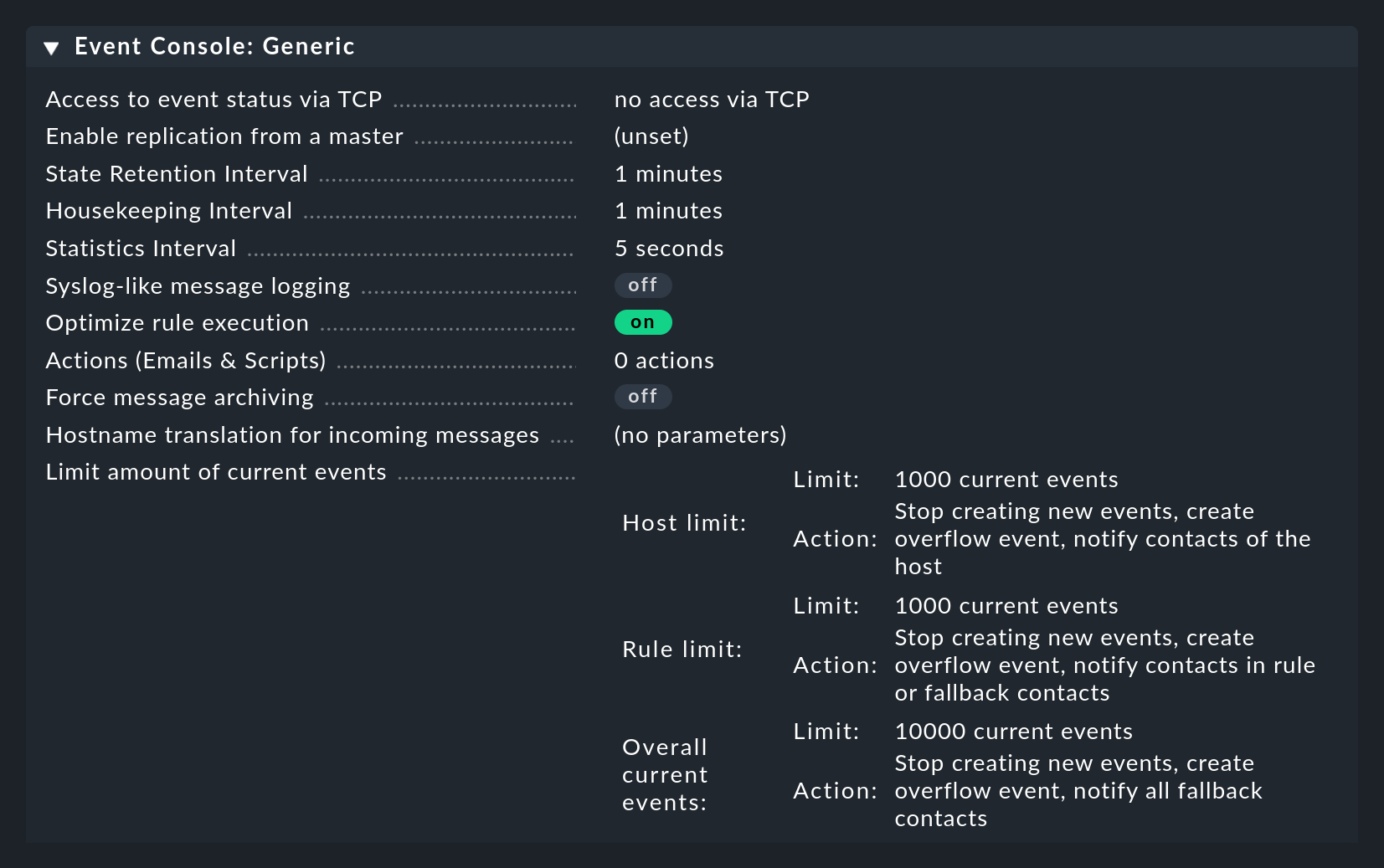
Comme toujours, vous trouverez des explications sur les différents paramètres dans l'aide en ligne et aux endroits appropriés de cet article.
L'accès aux paramètres est possible via l'autorisation Configuration of Event Console, qui par défaut n'est disponible que dans le rôle admin.
3.4. Autorisations
L'Event Console possède également sa propre section pour les rôles et les autorisations:
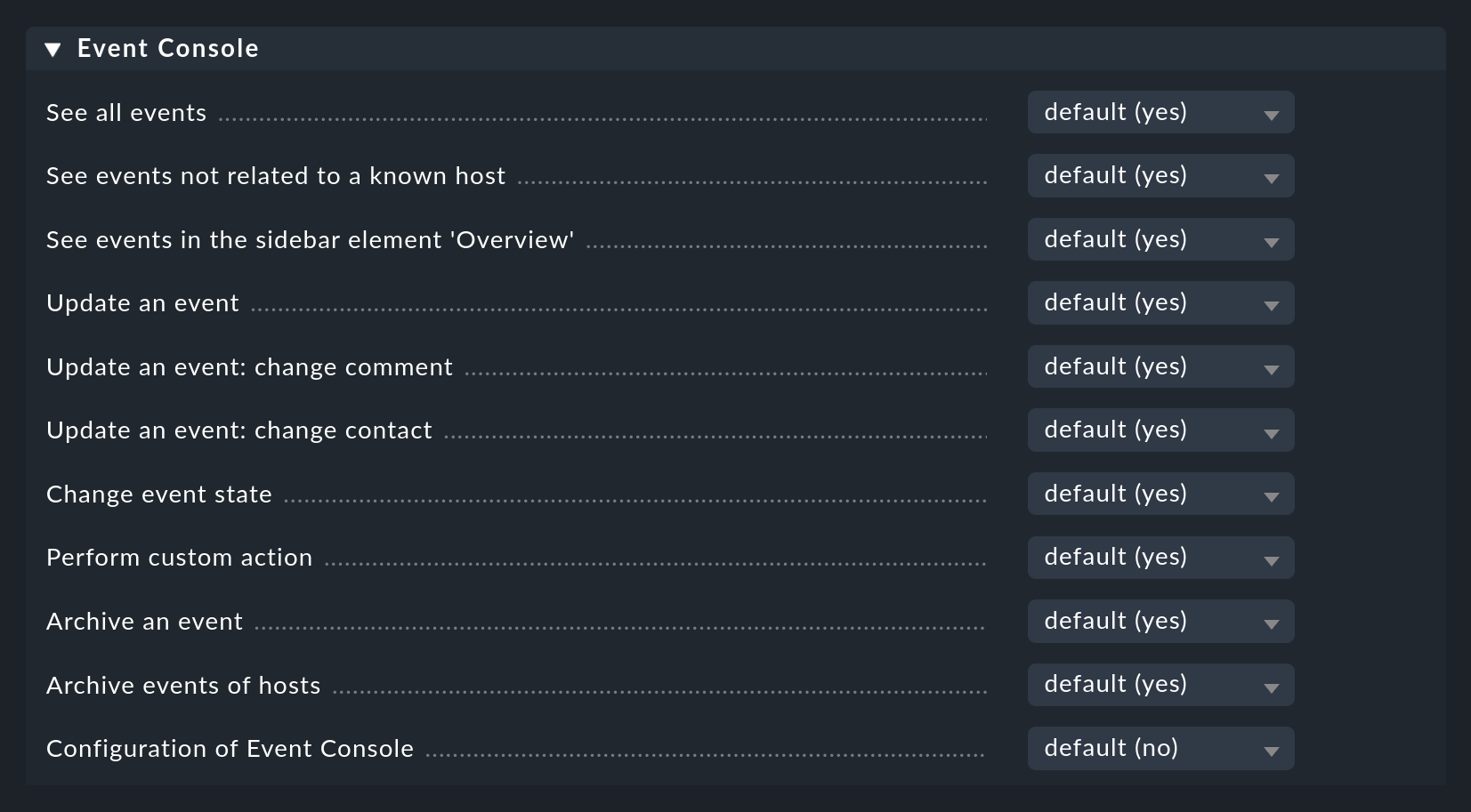
Nous aborderons certaines de ces autorisations plus en détail à des endroits appropriés de cet article.
3.5. Attribution d'un hôte dans l'Event Console
La particularité de l'Event Console est que, contrairement à la surveillance basée sur l'état, les hôtes ne sont pas au centre de l'attention. Les événements peuvent se produire sans affectation explicite d'un hôte, ce qui est d'ailleurs souvent souhaité. Cependant, une affectation devrait être possible pour les hôtes qui sont déjà en surveillance active, afin d'accéder rapidement à l'aperçu de l'état lorsqu'un événement se produit. Ou au plus tard, si les événements doivent être convertis en états, une affectation correcte est essentielle.
La règle fondamentale pour les messages reçus via syslog est que le nom d'hôte dans le message doit correspondre au nom d'hôte dans la surveillance. Pour ce faire, vous devez utiliser le nom de domaine entièrement qualifié (FQDN) / le nom d'hôte entièrement qualifié (FQHN), tant dans votre configuration syslog que dans le nom d'hôte dans Checkmk. Dans Rsyslog, vous pouvez y parvenir en utilisant la directive globale $PreserveFQDN on.
Checkmk tente de saisir au mieux les noms d'hôte des événements dans la surveillance active. Outre le nom d'hôte, l'alias de l'hôte est également pris en compte. Si le nom court est transmis par syslog, l'affectation est correcte.
Une résolution en amont de l'adresse IP n'aurait pas beaucoup de sens ici, car des serveurs log intermédiaires sont souvent utilisés. Si la conversion des noms d'hôte en FQDN/FQHN ou la réintroduction de nombreux alias prend trop de temps, vous pouvez utiliser le paramètre Hostname translation for incoming messages de l'Event Console pour traduire les noms d'hôte directement lors de la réception des messages. Vous disposez ainsi de nombreuses possibilités :
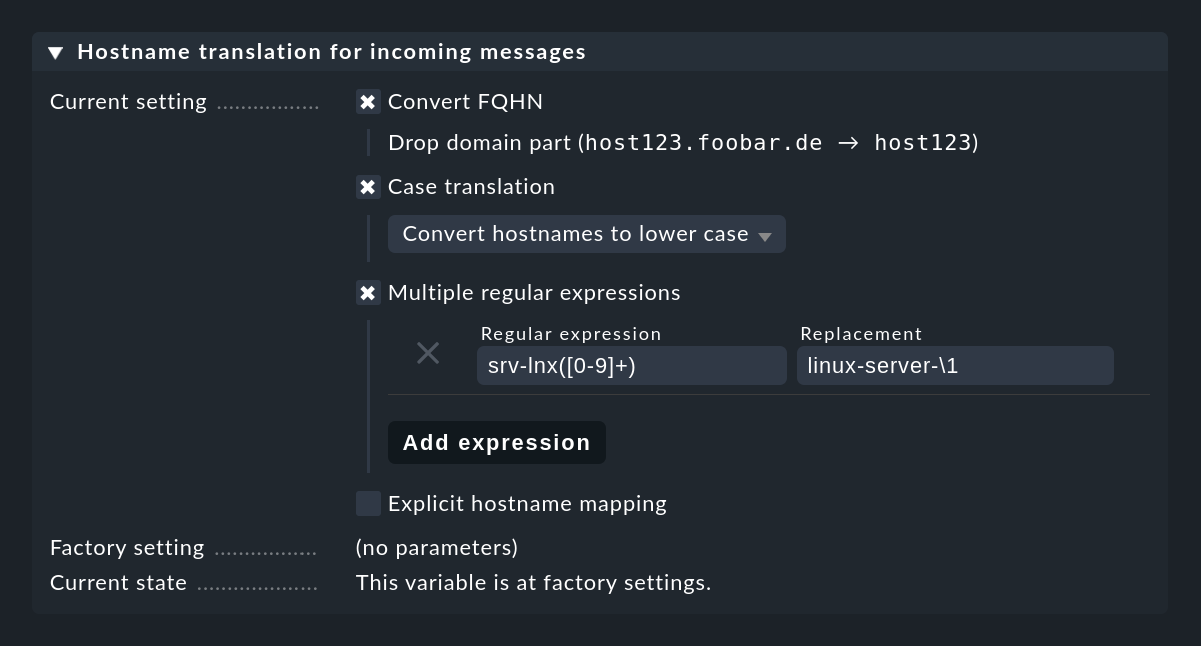
La méthode la plus souple consiste à utiliser des expressions régulières, qui permettent une recherche et un remplacement intelligents dans les noms d'hôtes. En particulier, si les noms d'hôtes sont explicites, mais que seule la partie du domaine utilisée dans Checkmk est manquante, une simple règle permet d'y remédier : (.*) devient \1.mydomain.test. Dans les cas où cela ne suffit pas, vous pouvez toujours utiliser Explicit hostname mapping pour spécifier un tableau de noms individuels et leurs traductions respectives.
Important : une conversion de nom est effectuée avant le check des conditions de la règle et donc bien avant une éventuelle réécriture du nom de l'hôte par l'action de la règle Rewrite hostname dans la réécriture automatique du texte.
L'affectation est un peu plus simple avec SNMP: l'adresse IP de l'expéditeur est comparée aux adresses IP cachées des hôtes dans la surveillance - c'est-à-dire que dès que des checks actifs réguliers sont disponibles, tels que le check d'accessibilité du port Telnet ou SSH d'un switch, les messages de statut de cet appareil envoyés via SNMP seront affectés à l'hôte correct.
4. L'Event Console dans la surveillance
4.1. Vues de tables d'événements
Les événements générés par l'Event Console sont affichés de manière analogue aux hôtes et aux services dans l'environnement de surveillance. Vous trouverez le point d'entrée pour cela dans le menu Monitor sous Event Console > Events:
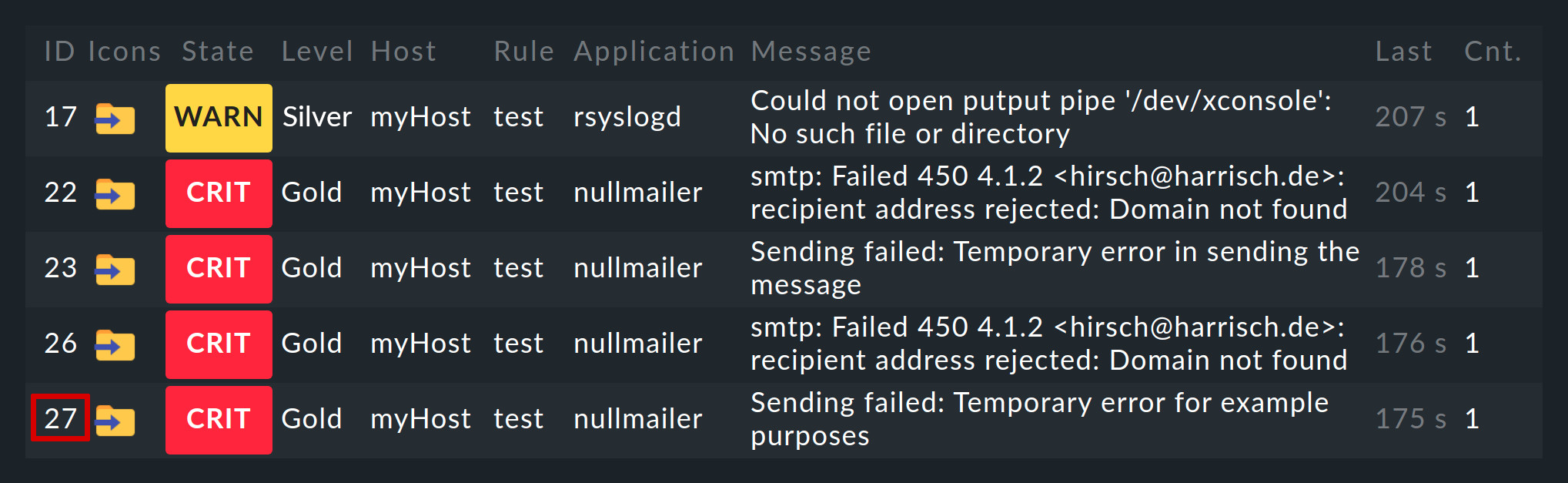
Vous pouvez personnaliser la vue Events comme n'importe quelle autre vue. Vous pouvez filtrer les événements affichés, exécuter des instructions, etc. Pour plus de détails, consultez l'article sur les vues. Lorsque vous créez de nouvelles vues d'événements, les événements et l'historique des événements sont disponibles en tant que sources de données.
Un clic sur l'ID de l'événement (ici, par exemple, 27) permet d'afficher ses détails :
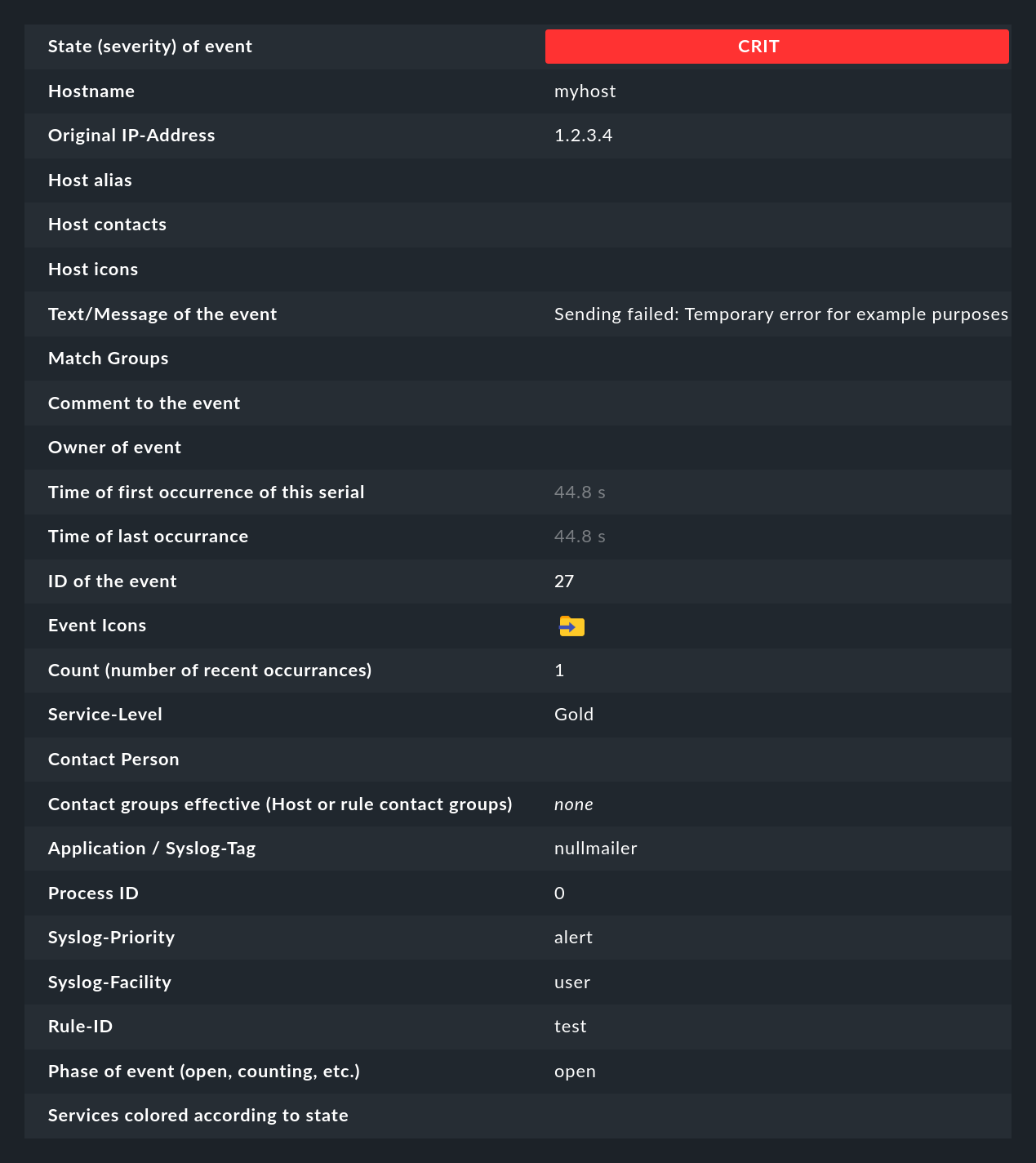
Comme vous pouvez le constater, un événement comporte un certain nombre de champs de données, dont nous expliquerons la signification petit à petit dans cet article. Les champs les plus importants doivent néanmoins être brièvement mentionnés ici :
| Champ | Signification |
|---|---|
State (severity) of event |
Comme indiqué dans l'introduction, chaque événement est classé comme OK, WARN, CRIT ou UNKNOWN. Les événements de statut OK sont plutôt inhabituels. En effet, la CE est précisément conçue pour ne filtrer que les problèmes. Cependant, dans certaines situations, un événement OK peut avoir du sens. |
Text/Message of the event |
Le contenu de l'événement : Un message texte. |
Hostname |
Le nom de l'hôte qui a envoyé le message. Il ne doit pas nécessairement s'agir d'un hôte activement surveillé par Checkmk. Cependant, si un hôte de ce nom existe dans la surveillance, le CE créera automatiquement un lien. Dans ce cas, les champs Host alias, Host contacts et Host icons seront également remplis et l'hôte apparaîtra dans la même notation que dans la surveillance active. |
Rule-ID |
L'ID de la règle qui a créé cet événement. En cliquant sur cet ID, vous accéderez directement aux détails de la règle. Par ailleurs, l'ID est conservé même si la règle n'existe plus entre-temps. |
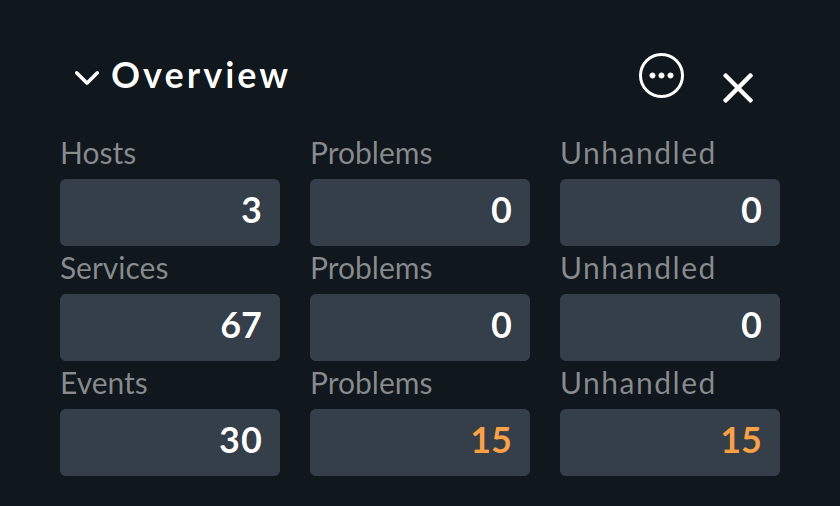
Comme indiqué au début, les événements sont affichés directement sur le site Overview de la barre latérale :
Vous y verrez trois chiffres :
Events- tous les événements ouverts et confirmés (correspond à la vue de Event Console > Events ).
Problems- dont seulement ceux avec un état WARN / CRIT / UNKNOWN
Unhandled- parmi ces derniers, seuls ceux qui n'ont pas encore été confirmés (plus d'informations à ce sujet dans un instant).
4.2. Instructions et flux de travail des événements
Comme pour les hôtes et les services, un flux de travail simple est mis en place pour les événements. Comme d'habitude, cela se fait via des commandes, qui peuvent être trouvées dans le menu Commands. En affichant et en sélectionnant avec des cases à cocher, vous pouvez exécuter une instruction sur plusieurs événements simultanément. Comme caractéristique spéciale, il y a l'archivage fréquemment utilisé d'un seul événement directement via l'icône.
Pour chacune des instructions, il existe une autorisation que vous pouvez utiliser pour contrôler pour quel rôle l'exécution de l'instruction est autorisée. Par défaut, toutes les instructions sont autorisées pour les détenteurs des rôles admin et user.
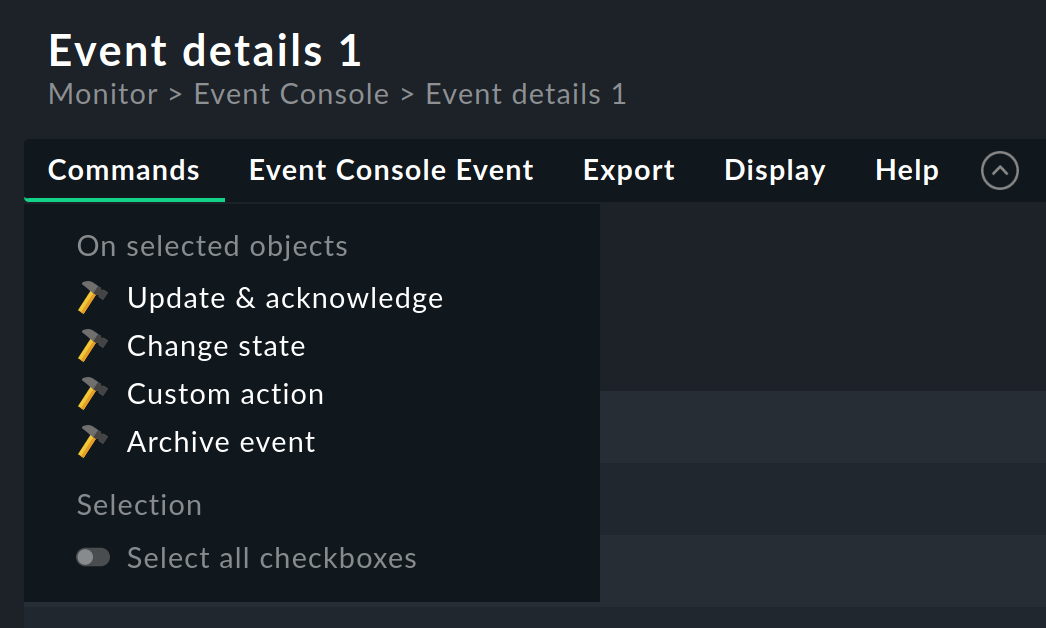
Les instructions suivantes sont disponibles :
Mise à jour et confirmation
L'instruction Update & Acknowledge affiche la zone suivante au-dessus de la liste des événements :
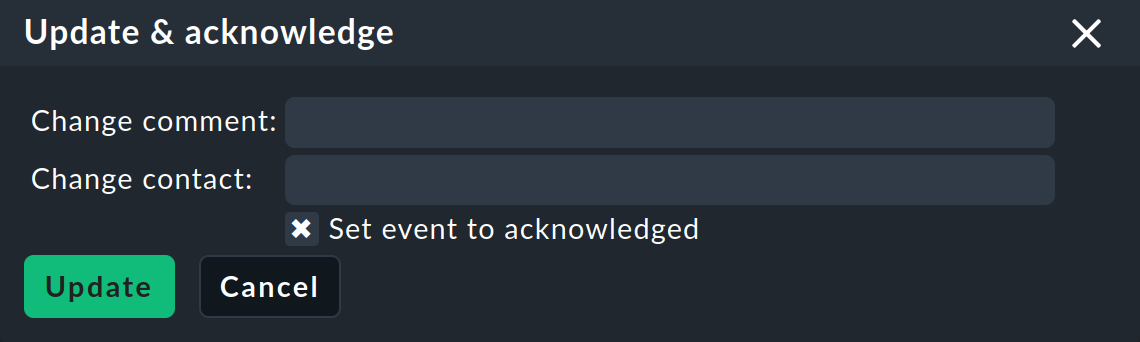
Le bouton Update vous permet, en une seule action, d'ajouter un commentaire à l'événement, d'ajouter une personne de contact et de confirmer l'événement. Le champ Change contact est intentionnellement en texte libre. Vous pouvez y saisir des éléments tels que des numéros de téléphone. En particulier, ce champ n'a aucune influence sur la visibilité de l'événement dans l'interface graphique - il s'agit purement d'un champ de commentaire.
La case à cocher Set event to acknowledged permet à l'événement de passer de la phase open à la phase acknowledged et d'être désormais affiché sous la forme handled, ce qui correspond à la confirmation des problèmes d'hôte et de service.
L'invocation ultérieure de l'instruction avec la case à cocher décochée supprime la confirmation.
Changement d'état
L'instruction Change State permet de modifier manuellement l'état d'un événement, par exemple de CRIT à WARN.
Action personnalisée
L'instruction Custom Action permet d'exécuter des actions librement définies sur les événements. Au départ, seule l'action Send monitoring notification est disponible. Elle envoie une notification Checkmk qui sera traitée de la même manière qu'une notification provenant d'un service activement surveillé. Cette notification passe par les règles de notification et peut générer des courriers électroniques, un SMS ou tout autre élément que vous avez configuré en conséquence. Voir ci-dessous pour plus de détails sur la notification par le CE.
Archiver un événement
Le bouton Archive Event supprime définitivement un événement de la liste des événements ouverts. Étant donné que toutes les actions sur les événements - y compris cette suppression - sont également enregistrées dans l'archive, vous pourrez toujours accéder ultérieurement à toutes les informations relatives à l'événement. C'est pourquoi nous ne parlons pas de suppression, mais plutôt d'archivage.
Vous pouvez également archiver confortablement des événements individuels à partir de la liste des événements à l'aide de .
4.3. Visibilité des événements
Le "problème" de la visibilité
Pour assurer la visibilité des hôtes et des services dans la surveillance pour les utilisateurs normaux, Checkmk utilise des groupes de contacts. Ces groupes sont assignés aux hôtes et aux services via l'interface graphique, la configuration des règles ou des dossiers.
Dans le cas de l'Event Console, une telle affectation d'événements à des groupes de contacts n'existe pas. En effet, on ne sait tout simplement pas à l'avance quels messages seront effectivement reçus. Même la liste des hôtes n'est pas connue, car les sockets pour Syslog et SNMP sont accessibles de partout. C'est pourquoi l'Event Console comprend quelques fonctions spéciales pour définir la visibilité.
Au départ, tout le monde peut tout voir
Tout d'abord, lors de la configuration des rôles d'utilisateur, il y a l'autorisation Event Console > See all events. Elle est active par défaut, de sorte que les utilisateurs normaux sont autorisés à voir tous les événements !Ceci est délibérément mis en place pour s'assurer que les messages d'erreur importants ne tombent pas à côté en raison d'une configuration incorrecte. La première étape pour une visibilité plus précise est de supprimer cette autorisation du rôle user.
Affectation aux ordinateurs hôtes
Pour que la visibilité des événements soit aussi cohérente que possible avec le reste de la surveillance, l'Event Console essaie autant que possible de saisir les hôtes dont elle reçoit les événements en fonction des hôtes configurés via l'interface graphique de configuration. Ce qui semble simple est délicat dans les détails. Parfois, un nom d'hôte manque dans l'événement et seule l'adresse IP est connue. Dans d'autres cas, le nom d'hôte est orthographié différemment de ce qui est indiqué dans l'interface graphique de configuration.
L'attribution se fait comme suit :
Si aucun nom d'hôte n'est trouvé dans l'événement, son adresse IP est utilisée comme nom d'hôte.
Le nom d'hôte figurant dans l'événement est ensuite comparé, sans tenir compte de la casse, à tous les noms de domaine, adresses d'hôte et adresses IP des hôtes dans la surveillance.
Si un hôte est trouvé de cette manière, ses groupes de contact sont utilisés pour l'événement, ce qui permet de contrôler la visibilité.
Si l'hôte n' est pas trouvé, les groupes de contact - s'ils sont configurés à cet endroit- sont repris de la règle qui a créé l'événement.
Si aucun groupe n'est stocké à cet endroit, l'utilisateur ne peut voir l'événement que s'il dispose de l'autorisation Event Console > See events not related to a known host.
Vous pouvez influencer l'affectation à un moment donné : si des groupes de contacts sont définis dans la règle et que l'hôte peut être affecté, l'affectation a généralement la priorité. Vous pouvez modifier cela dans une règle à l'aide de l'option Precedence of contact groups:
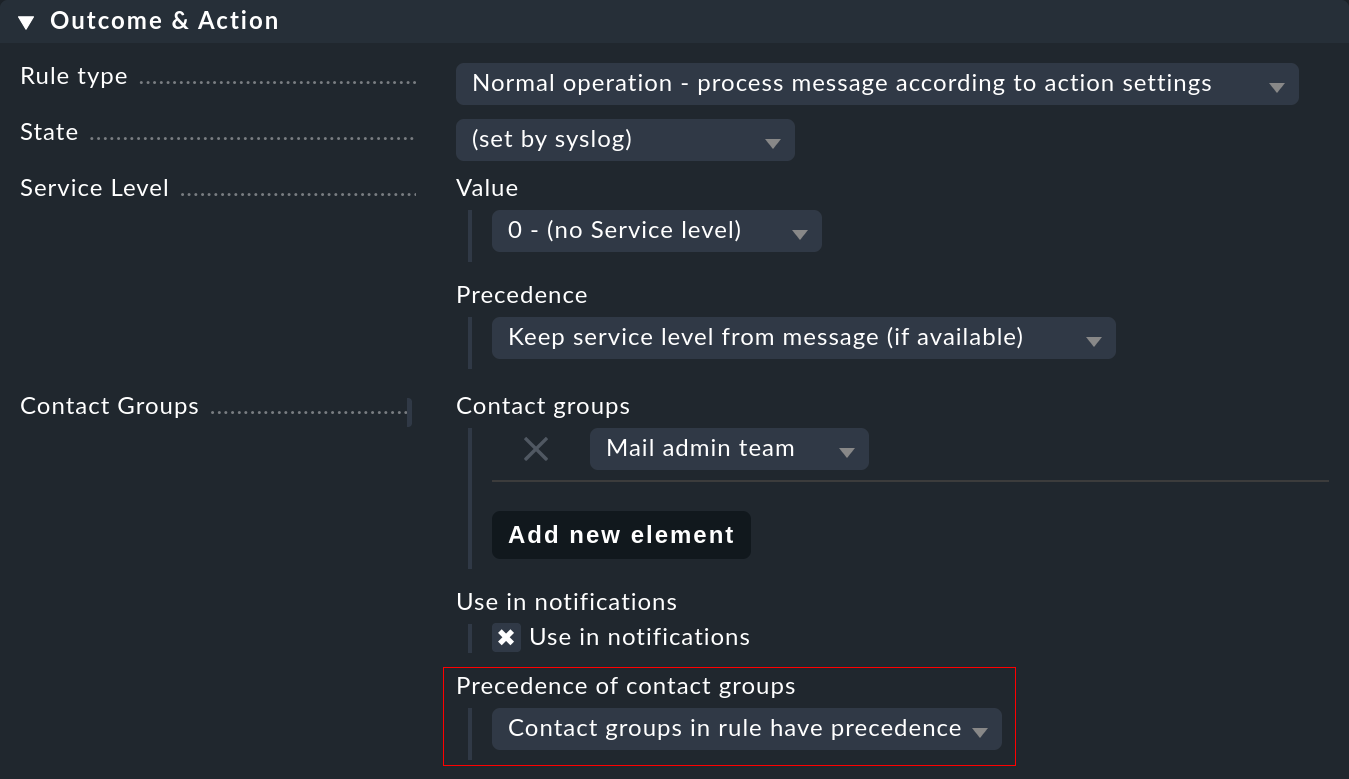
En outre, vous pouvez effectuer des réglages directement dans la règle de notification, ce qui permet de donner la priorité au type d'événement par rapport aux responsabilités habituelles d'un hôte.
4.4. Résolution des problèmes
Quelle règle s'applique et à quelle fréquence ?
Tant pour les ensembles de règles ...
... que pour les règles individuelles ...

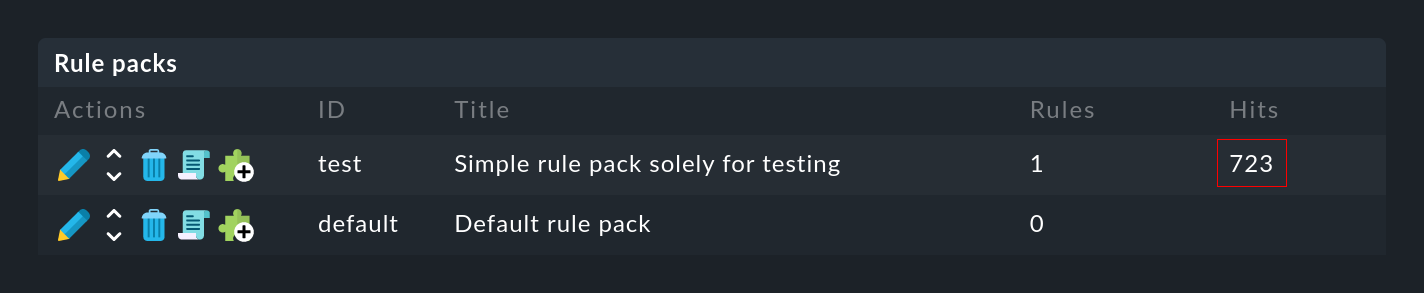
... dans la colonne Hits, vous trouverez des informations sur le nombre de fois que le paquet ou la règle a déjà saisi un message. Cela vous aide à éliminer ou à réparer les règles inefficaces. Mais cela peut également être intéressant pour les règles qui saisissent très souvent un message. Pour une performance optimale du CE, ces règles devraient se trouver au début de la chaîne de règles. De cette façon, vous pouvez réduire le nombre de règles que le CE doit saisir pour chaque message.
Vous pouvez remettre les compteurs à zéro à tout moment à l'aide de l'élément de menu Event Console > Reset counters.
Débogage de l'évaluation des règles
Lors du test d'une règle, vous avez déjà vu comment vous pouvez utiliser Event Simulator pour vérifier les évaluations de vos règles. Vous pouvez obtenir des informations similaires au moment de l'exécution pour tous les messages, si dans les paramètres de l'Event Console vous définissez la valeur de Debug rule execution à on.
Le fichier journal de l'Event Console se trouve à l'adresse var/log/mkeventd.log, dans lequel vous trouverez la raison exacte pour laquelle une règle qui a été checkée n'a pas pris effet :
[1481020022.001612] Processing message from ('10.40.21.11', 57123): '<22>Dec 6 11:27:02 myserver123 exim[1468]: Delivery complete, 4 message(s) remain.'
[1481020022.001664] Parsed message:
application: exim
facility: 2
host: myserver123
ipaddress: 10.40.21.11
pid: 1468
priority: 6
text: Delivery complete, 4 message(s) remain.
time: 1481020022.0
[1481020022.001679] Trying rule test/myrule01...
[1481020022.001688] Text: Delivery complete, 4 message(s) remain.
[1481020022.001698] Syslog: 2.6
[1481020022.001705] Host: myserver123
[1481020022.001725] did not match because of wrong application 'exim' (need 'security')
[1481020022.001733] Trying rule test/myrule02n...
[1481020022.001739] Text: Delivery complete, 4 message(s) remain.
[1481020022.001746] Syslog: 2.6
[1481020022.001751] Host: myserver123
[1481020022.001764] did not match because of wrong textIl va sans dire que vous ne devriez utiliser cette journalisation intensive qu'en cas de besoin et avec prudence. Dans un environnement à peine plus complexe, d'énormes volumes de données seront générés !
5. Le plein pouvoir des règles
5.1. Les conditions
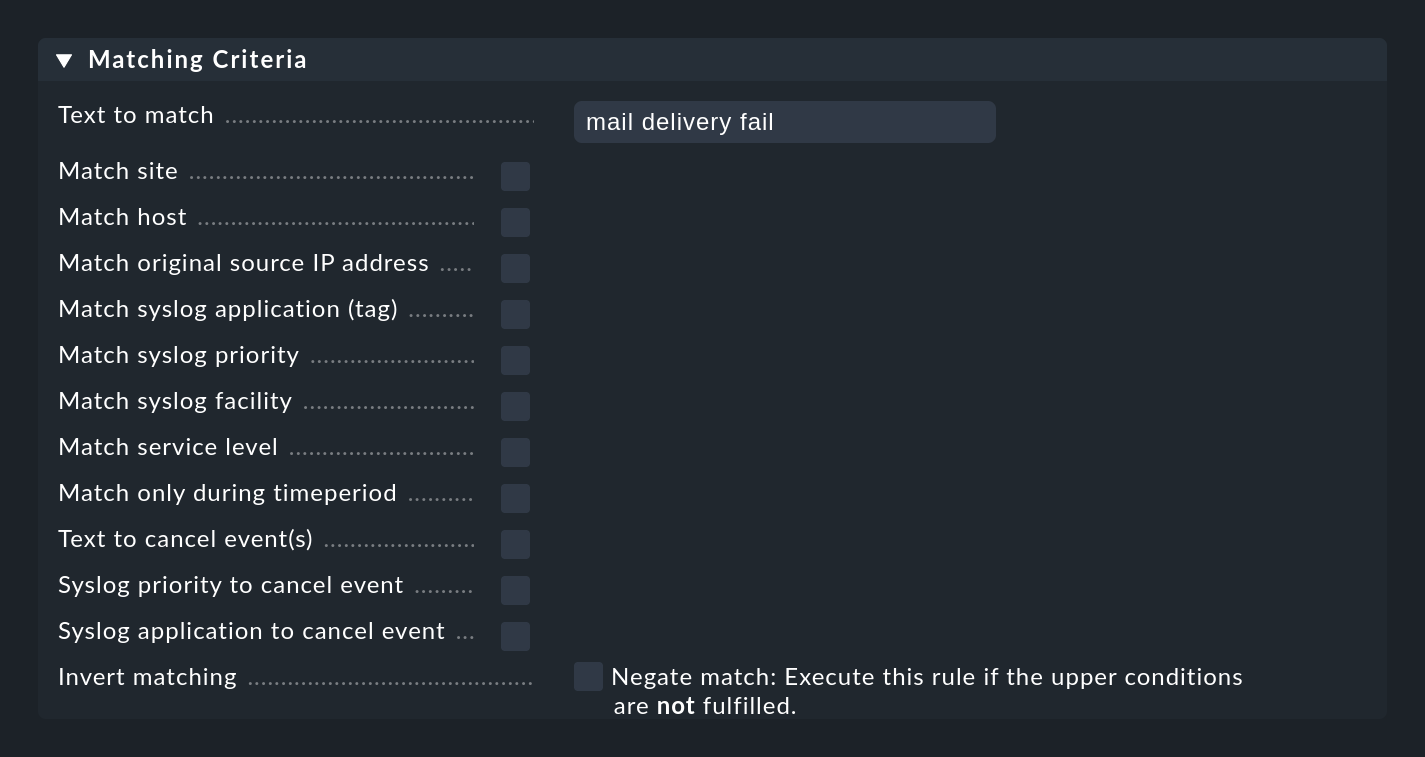
La partie la plus importante d'une règle EC est bien sûr la condition (Matching Criteria). Ce n'est que si un message remplit toutes les conditions enregistrées dans la règle que les actions définies dans la règle sont exécutées et que l'évaluation du message est ainsi terminée.
Informations générales sur les comparaisons de texte
Pour toutes les conditions impliquant des champs de texte, le texte de comparaison est toujours traité comme une expression régulière. La comparaison s'effectue toujours en ignorant les majuscules et les minuscules. Il s'agit d'une exception aux conventions de Checkmk dans d'autres modules. Toutefois, cela rend la formulation des règles plus robuste, notamment parce que les noms d'hôte dans les événements ne sont pas nécessairement cohérents dans leur orthographe s'ils ont été configurés sur chaque hôte localement plutôt que de manière centralisée. Cette exception est donc très utile dans ce cas.
En outre, une correspondance d'infixe s'applique toujours - c'est-à-dire un check pour un contenu du texte de recherche. Vous pouvez donc saisir une .* au début ou à la fin du texte de recherche.
Il existe toutefois une exception: si aucune expression régulière n' est utilisée dans la correspondance avec le nom de l'hôte, mais qu'un nom d'hôte explicite est utilisé, il sera saisi pour une correspondance exacte et non pour son contenu.
Attention : Si le texte de recherche contient un point (.), il sera considéré comme une expression régulière et la recherche infixe s'appliquera, par exemple myhost.com saisira également notmyhostide!
Groupes de correspondance
Le concept de groupes de correspondance dans le champ Text to match est très important et utile. Il s'agit des sections de texte qui saisissent des expressions entre parenthèses dans l'expression régulière.
Supposons que vous souhaitiez surveiller le type de message suivant dans le fichier journal d'une base de données :
Database instance WP41 has failedLe champ WP41 est bien entendu variable et vous ne souhaitez certainement pas formuler une règle distincte pour chaque cas différent. C'est pourquoi vous utilisez .* dans l'expression rationnelle, qui représente n'importe quelle chaîne de caractères :
Database instance .* has failed
Si vous mettez maintenant la partie variable entre crochets, l'Event Console mémorisera(capturera) la valeur réelle pour toute action future :
Database instance (.*) has failed
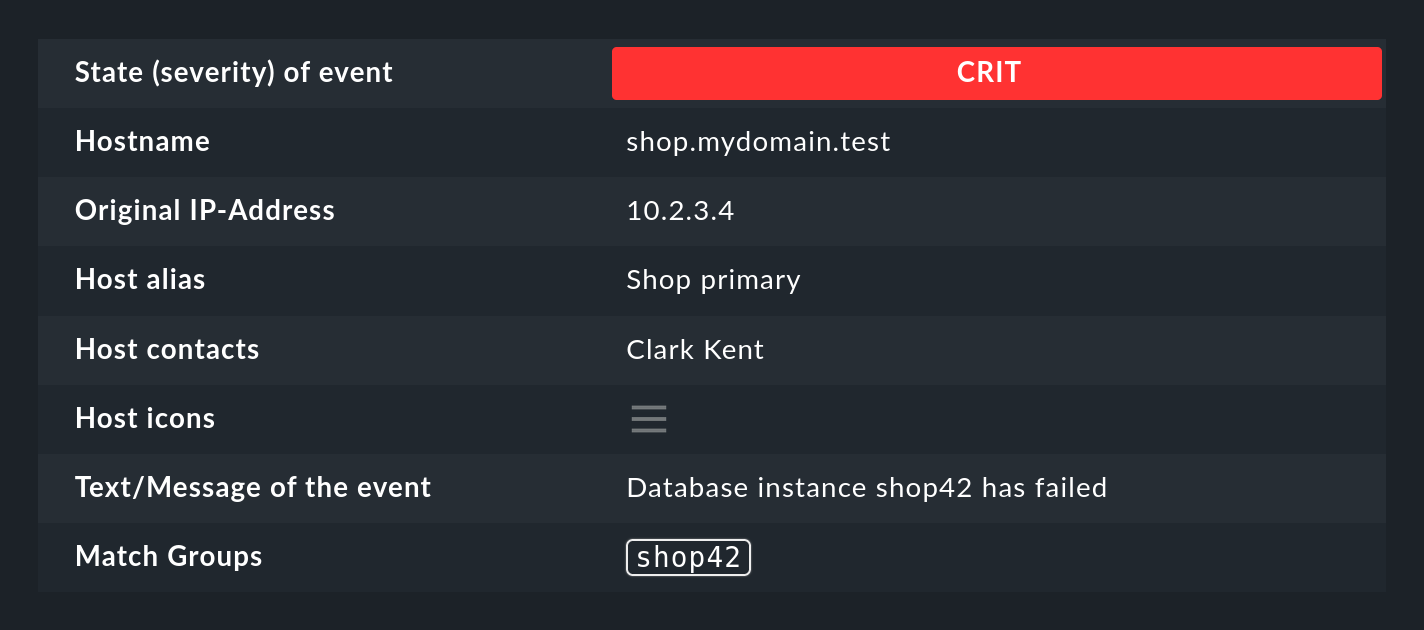
Lorsque la règle a été saisie avec succès, le premier groupe de correspondance est maintenant défini sur la valeur WP41 (ou sur l'instance qui a produit l'erreur).
Vous pouvez saisir ces groupes de correspondance sur le site Event Simulator en plaçant le curseur sur la boule verte :

Vous pouvez également voir les groupes dans les détails de l'événement généré :
Les groupes de correspondance sont notamment utilisés pour :
laréécriture d' événements
L'annulation automatique des événements
Le comptage des messages
A ce stade, un conseil : dans certaines situations, vous devez grouper quelque chose dans l'expression régulière mais vous ne voulez pas créer de groupe de correspondance. Vous pouvez le faire en plaçant un ?: directement après la parenthèse ouvrante. Exemple : L'expression one (.*) two (?:.*) three ne saisit pour one 123 two 456 three que le seul groupe de correspondance 123.
Adresse IP
Dans le champ Match original source IP address, vous pouvez saisir l'adresse IPv4 de l'expéditeur du message. Indiquez soit une adresse exacte, soit un réseau dans la notation X.X.X.X/Y, par exemple 192.168.8.0/24 pour saisir toutes les adresses du réseau 192.168.8.X.
Notez que la correspondance sur l'adresse IP ne fonctionne que si les systèmes surveillés envoient directement à l'Event Console. Si un autre serveur syslog intermédiaire connecté transmet les messages, son adresse apparaîtra comme celle de l'expéditeur dans le message.
Priorité et facilité syslog
Les champs Match syslog priority et Match syslog facility sont des informations standardisées, définies à l'origine par les informations Syslog. En interne, un champ de 8 bits est divisé en 5 bits pour la facilité (32 possibilités) et 3 bits pour la priorité (8 possibilités).
Les 32 facilités prédéfinies étaient autrefois destinées à quelque chose comme une application, mais la sélection n'a pas été faite de manière très prospective à l'époque. L'une des facilités est uucp- un protocole qui, au début des années 90 du dernier millénaire, était déjà presque obsolète.
Mais il est un fait que chaque message qui arrive via syslog porte l'une de ces facilités. Dans certains cas, vous pouvez également les attribuer librement lors de l'envoi du message, afin de pouvoir les filtrer ultérieurement. C'est très utile.
L'utilisation de la facilité et de la priorité a également un aspect performant. Si vous définissez une règle qui ne s'applique de toute façon qu'aux messages qui ont tous la même facilité ou priorité, vous devez définir ces dernières en plus dans les filtres de la règle. L'Event Console peut alors contourner ces règles de manière très efficace lorsqu'un message avec des valeurs différentes est reçu. Plus il y a de règles avec ces filtres définis, moins il y a de comparaisons de règles nécessaires.
Inversion d'une saisie
La case à cocher Negate match: Execute this rule if the upper conditions are not fulfilled. fait en sorte que la règle ne prenne effet que lorsqu'aucune des conditions n' est remplie. En fait, cela n'est utile que dans le contexte de deux types de règles (Rule type dans la case Outcome & Action de la règle) :
Do not perform any action, drop this message, stop processing.
Skip this rule pack, continue rule execution with next pack
Vous pouvez en savoir plus sur les ensembles de règles ci-dessous.
5.2. Effet de la règle
Type de règle : Annuler ou créer un événement
Lorsqu'une règle est saisie, elle précise ce qu'il doit advenir du message, ce qui est fait dans la case Outcome & Action:
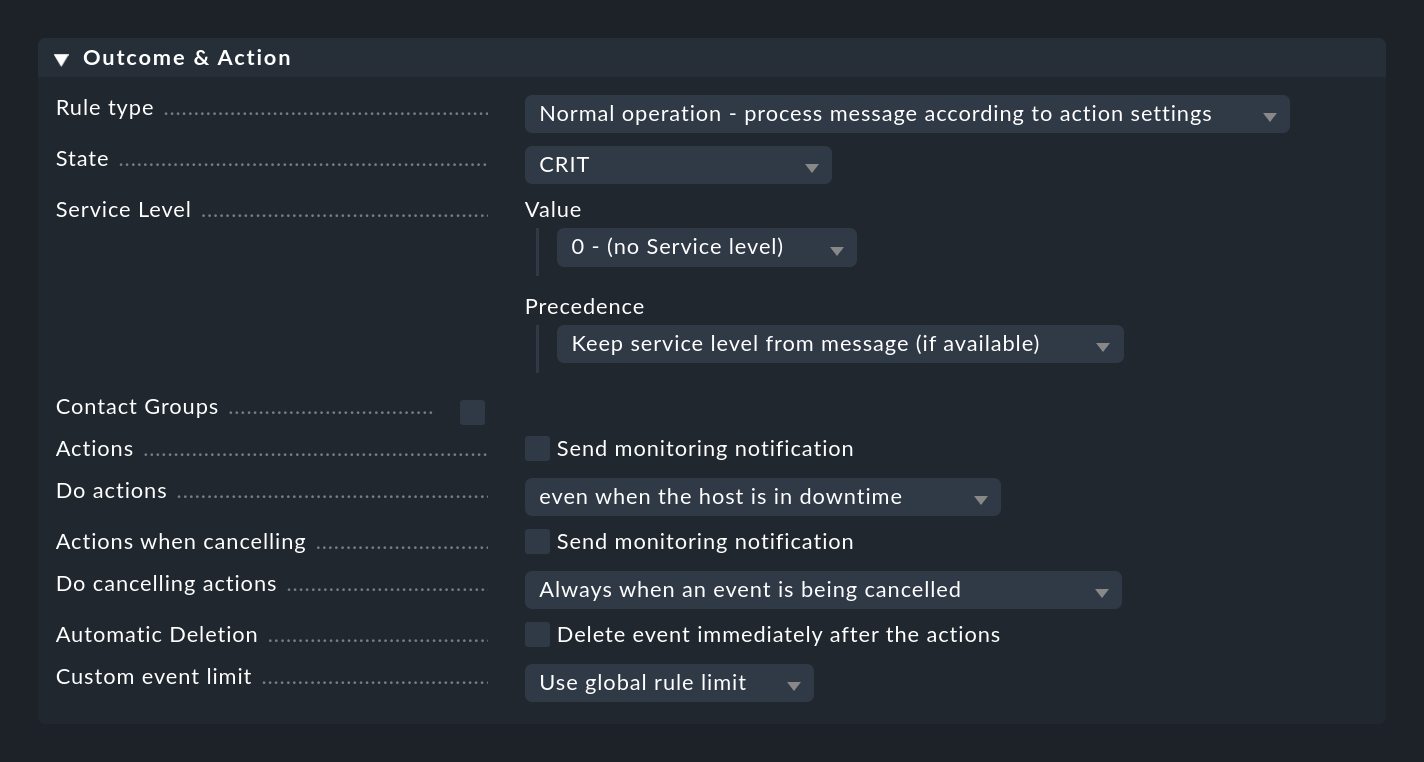
L'adresse Rule type peut être utilisée pour interrompre l'évaluation à ce point entièrement ou pour le paquet de règles actuel. La première option en particulier devrait être utilisée pour se débarrasser de la plupart des "bruits" inutiles en utilisant quelques règles spécifiques au tout début. Ce n'est qu'avec les règles "normales" que les autres options de cette case sont réellement évaluées.
Définition de l'état
Avec State, la règle définit le statut de l'événement dans la surveillance. Dans la règle, cet état sera WARN ou CRIT. Les règles qui génèrent des événements OK peuvent être intéressantes dans les exceptions pour représenter certains événements de manière purement informative. Dans un tel cas, une combinaison avec une expiration automatique de ces événements est alors intéressante.
Outre la définition d'un état explicite, il existe deux autres options dynamiques. Le paramètre (set by syslog) prend en charge la classification sur la base de la priorité syslog. Cela ne fonctionne que si le message a déjà été classifié de manière utilisable par l'expéditeur. Les messages reçus directement par syslog contiendront l'une des huit priorités RFC, qui sont mises en correspondance comme suit :
| Priorité | ID | État | Définition selon syslog |
|---|---|---|---|
|
0 |
CRIT |
le système est inutilisable |
|
1 |
CRIT |
action immédiate requise |
|
2 |
CRIT |
condition critique |
|
3 |
CRIT |
erreur |
|
4 |
WARN |
avertissement |
|
5 |
OK |
normal, mais informations importantes |
|
6 |
OK |
purement informatif |
|
7 |
OK |
message de débogage |
Outre les messages syslog, les messages provenant du journal des événements de Windows et les messages provenant de fichiers texte qui ont déjà été classés avec le plugin Checkmk Logwatch sur le système cible, fournissent des états prêts à l'emploi. Pour les trap SNMP, cela n'est malheureusement pas disponible.
Une méthode complètement différente consiste à classer le message sur la base du texte lui-même, ce qui peut être fait à l'aide du paramètre (set by message text):
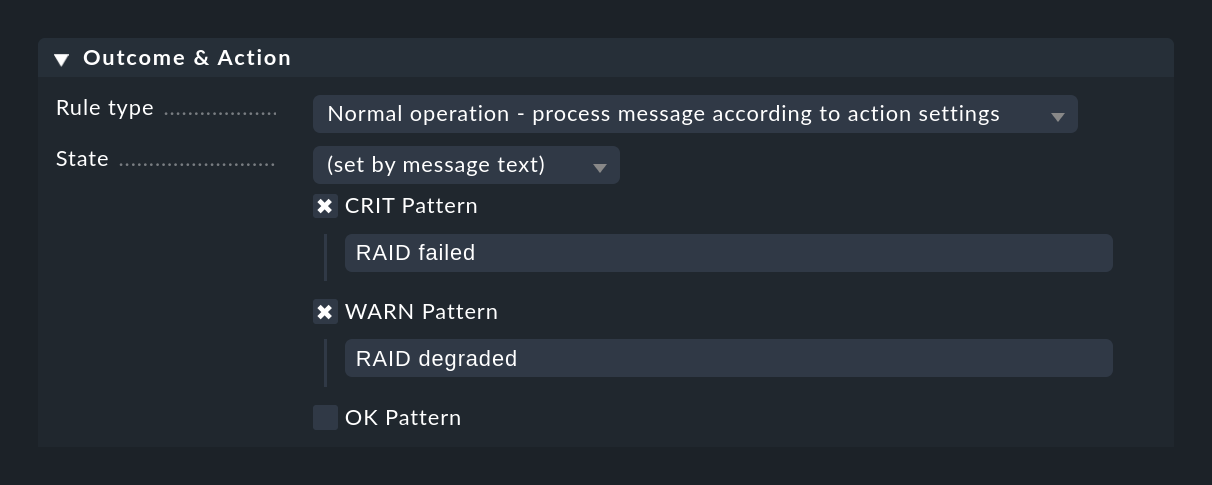
La saisie des textes configurés ici n'a lieu qu'après la vérification de Text to match et des autres conditions de la règle, de sorte que vous n'avez pas à répéter ces vérifications.
Si aucun des modèles configurés n'est trouvé, l'événement retourne à l'état UNKNOWN.
Niveaux de service
L'idée derrière le champ Service Level est que chaque hôte et chaque service dans une organisation a un certain niveau d'importance. Cela peut être associé à un accord de service spécifique pour l'hôte ou le service. Dans Checkmk, vous pouvez utiliser des règles pour assigner de tels niveaux de service à vos hôtes et services et ensuite, par exemple, faire en sorte que la notification ou les tableaux de bord auto-définis en dépendent.
Comme les événements ne sont pas nécessairement en corrélation avec les hôtes ou les services, l'Event Console vous permet d'attribuer un niveau de service à un événement à l'aide d'une règle. Vous pouvez ensuite filtrer les vues de l'événement à l'aide de ce niveau.
Par défaut, Checkmk définit quatre niveaux : 0 (aucun niveau), 10 (argent), 20 (or) et 30 (platine). Vous pouvez modifier cette sélection en fonction de vos besoins sur le site Global settings > Notifications > Service Levels. Les chiffres désignant les niveaux sont décisifs, car les niveaux sont triés en fonction de ces chiffres et comparés en fonction de leur importance relative.
Groupes de contacts
Les groupes de contacts utilisés pour la visibilité sont également utilisés pour la notification des événements. Vous pouvez utiliser des règles pour affecter explicitement des groupes de contacts aux événements. Vous trouverez plus de détails à ce sujet dans le chapitre sur la surveillance.
Actions
Les actions sont très similaires aux gestionnaires d'alertes pour les hôtes et les services. Ici, vous pouvez avoir un script auto-défini exécuté lorsqu'un événement est ouvert. Tous les détails décrivant les actions peuvent être trouvés ci-dessous dans une section séparée.
Suppression automatique (archivage)
La suppression automatique (= archivage), que vous pouvez définir avec Delete event immediately after the actions, garantit qu'un événement n'est pas du tout visible dans la surveillance. C'est utile si vous voulez seulement déclencher certaines actions automatiquement ou si vous voulez seulement archiver certains événements afin de pouvoir les rechercher plus tard.
5.3. Réécriture automatisée de textes
La fonction Rewriting permet à une règle CE de réécrire automatiquement les champs de texte d'un message et d'y ajouter des annotations. Cette fonction est configurée dans une case séparée :
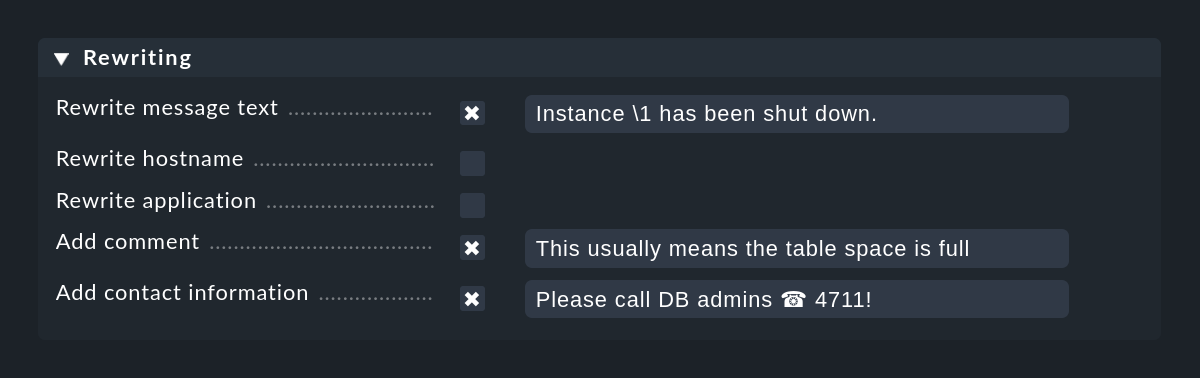
Lors de la réécriture, les groupes de correspondance sont particulièrement importants. Ils vous permettent d'inclure des parties du message d'origine dans le nouveau texte. Vous pouvez accéder aux groupes lors de la réécriture de la manière suivante :
|
Sera remplacé par le premier groupe de correspondance saisi dans le message original. |
|
Sera remplacé par le deuxième groupe de correspondance du message original (etc.). |
|
Sera remplacé par le message original complet. |
Dans la capture d'écran ci-dessus, le texte du nouveau message sera codé comme suit : Instance \1 has been shut down.Bien entendu, cela ne fonctionne que si le Text to match dans la même règle de l'expression de recherche régulière comporte également au moins une expression entre parenthèses. Un exemple de cela serait par ex :

Quelques remarques supplémentaires sur la réécriture :
La réécriture se fait après la saisie et avant l' exécution des actions.
La saisie, la réécriture et les actions sont toujours effectuées dans la même règle. Il n'est pas possible de réécrire un message et de le traiter ensuite avec une règle ultérieure.
Les expressions
\1,\2etc. peuvent être utilisées dans tous les champs de texte, et pas seulement dans Rewrite message text.
5.4. Annulation automatisée d'événements
Certaines applications ou certains appareils ont la gentillesse d'envoyer ultérieurement un message OK approprié dès que le problème a été résolu. Vous pouvez configurer le CE de manière à ce que, dans un tel cas, l'événement ouvert par l'erreur soit automatiquement fermé. C'est ce qu'on appelle l'annulation.
La figure suivante montre une règle avec laquelle les messages contenant le texte database instance (.*) has failed sont recherchés. L'expression (.*) représente une chaîne arbitraire qui est saisie dans un groupe de correspondance. L'expression database instance (.*) recovery in progress, qui se trouve dans le champ Text to cancel event(s) de la même règle, fermera automatiquement les événements créés avec cette règle lorsqu'un message correspondant sera reçu :
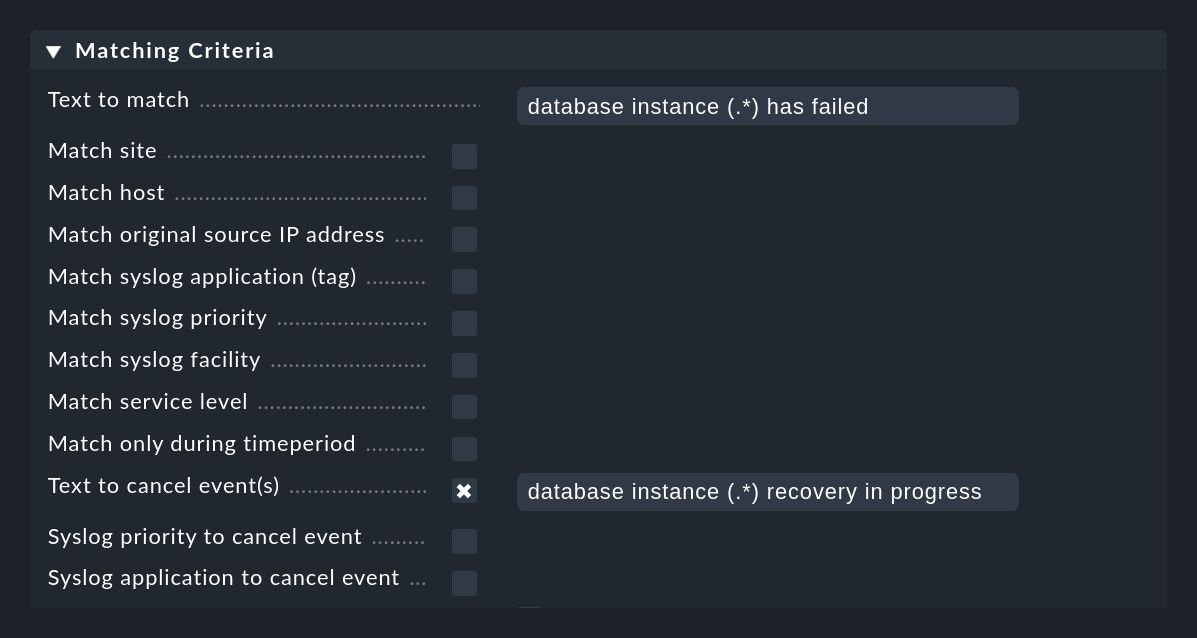
L'annulation automatique fonctionne tant que
un message dont le texte saisit Text to cancel event(s) est reçu,
la valeur saisie ici dans le groupe
(.*)est identique au groupe de correspondance du message original,les deux messages proviennent du même hôte, et
il s'agit de la même application (le champ Syslog application to cancel event ).
Le principe du groupe de correspondance est très important ici. Après tout, il ne serait pas très logique que le message database instance TEST recovery in progress annule un événement généré par le message database instance PROD has failed, n'est-ce pas ?
Ne commettez pas l'erreur d'utiliser le caractère générique \1 dans Text to cancel events(s). Cela ne fonctionne pas! Ces caractères génériques ne fonctionnent que pour la réécriture.
Dans certains cas, il arrive qu'un texte soit utilisé à la fois pour créer et pour annuler un événement. Dans ce cas, l'annulation est prioritaire.
Exécuter des actions lors de l'annulation
Vous pouvez également faire en sorte que des actions soient exécutées automatiquement lorsqu'un événement est annulé. Il est important de savoir que lorsqu'un événement est annulé, un certain nombre de champs de données de l'événement sont remplacés par les valeurs du message OK avant que toute action ne soit exécutée. Ainsi, les données complètes du message OK sont disponibles dans le script d'action. En outre, pendant cette phase, l'état de l'événement est marqué comme OK. De cette manière, un script d'action peut détecter une annulation et vous pouvez utiliser le même script pour les messages d'erreur et les messages OK (par exemple, lors d'une connexion à un système de tickets).
Les champs suivants sont remplacés par les données du message OK :
Le texte du message
L'horodatage
L'heure de la dernière occurrence
La priorité syslog
Tous les autres champs restent inchangés, y compris l'identifiant de l'événement.
Annulation en combinaison avec la réécriture
Si vous utilisez la réécriture et l'annulation dans la même règle, vous devez faire attention lorsque vous réécrivez le nom d'hôte ou l'application. Lorsque vous annulez un événement, la console d'événements vérifie toujours si le message d'annulation saisit le nom d'hôte et l'application de l'événement ouvert. Mais si ces éléments sont réécrits, l'annulation ne fonctionnera jamais.
C'est pourquoi, avant d'annuler l'événement, l'Event Console simule une réécriture du nom de l'hôte et de l'application afin de comparer les textes pertinents, ce qui correspond probablement à ce que vous attendez.
Vous pouvez également tirer parti de ce comportement si le champ de l'application dans le message d'erreur et le message OK ultérieur ne se saisissent pas. Dans ce cas, il suffit de réécrire le champ de l'application en lui attribuant une valeur fixe connue, ce qui aboutit en fait au résultat suivant : ce champ sera ignoré.
Annulation en fonction de la priorité du syslog
Il existe (malheureusement) des situations où le texte des messages d'erreur et OK est absolument identique. Dans la plupart des cas, l'état réel n'est pas codé dans le texte, mais dans la priorité syslog.
Pour ce faire, il existe l'option Syslog priority to cancel event. Entrez ici la plage debug... notice par exemple. Toutes les priorités dans cette plage sont normalement considérées comme ayant un statut OK. Lorsque vous utilisez cette option, vous devez toujours entrer un texte approprié dans le champ Text to cancel event(s), sinon la règle saisira tous les messages OK qui affectent la même application.
5.5. Comptage des messages
Dans la case Counting & Timing, vous trouverez des options permettant de compter les messages similaires. L'idée est que certains messages ne sont pertinents que s'ils se produisent trop fréquemment ou trop rarement au cours de périodes de temps données.
Messages trop fréquents
Vous pouvez activer le check des messages trop fréquents avec l'option Count messages in interval:
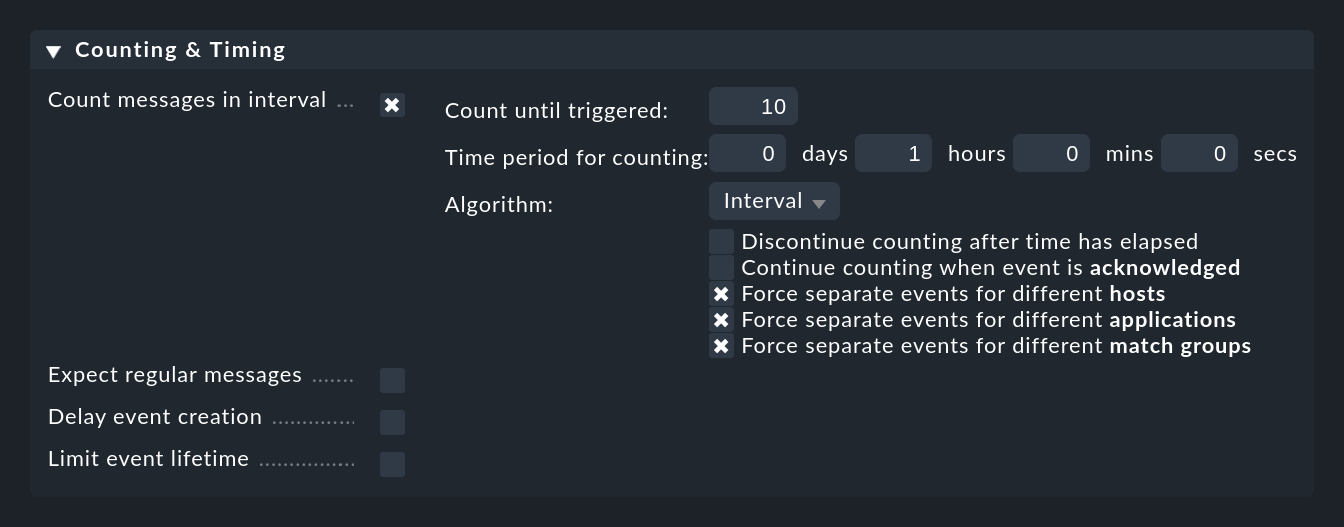
Dans ce cas, vous devez d'abord spécifier une période à l'adresse Time period for counting et le nombre de messages qui doivent entraîner l'ouverture d'un événement à l'adresse Count until triggered. Dans l'exemple ci-dessus, ce nombre est fixé à 10 messages par heure. Bien entendu, il ne s'agit pas de 10 messages arbitraires, mais bien de messages saisis par la règle.
Normalement, il est logique de ne pas compter tous les messages correspondants globalement, mais seulement ceux qui se réfèrent à la même "cause". Pour contrôler cela, il y a les trois cases à cocher pour les options préfixées par Force separate events for different …. Elles sont préréglées de telle sorte que les messages ne sont comptés ensemble que s'ils saisissent la même chose :
l'ordinateur hôte
l'application
Cela vous permet de formuler des règles telles que "Si plus de 10 messages sont reçus par heure en provenance du même hôte, de la même application et de la même instance, alors...". En raison de la règle, plusieurs événements différents peuvent être générés.
Si, par exemple, vous désélectionnez les trois cases à cocher, le comptage ne se fera que globalement et la règle ne pourra générer qu'un seul événement au total !
D'ailleurs, il peut être judicieux d'indiquer 1 comme valeur de comptage, ce qui vous permet de contrôler efficacement les "tempêtes d'événements". Si, par exemple, 100 messages du même type sont reçus dans un court laps de temps, un seul événement sera créé. Vous verrez alors dans les détails de l'événement
l'heure à laquelle le premier message a été reçu,
l'heure à laquelle le message le plus récent a été reçu, et
le nombre total de messages combinés dans cet événement.
Lorsque l'affaire est ensuite clôturée, deux cases à cocher vous permettent de définir quand un nouvel événement doit être ouvert. Normalement, une confirmation de l'événement crée une situation dans laquelle, si d'autres messages sont reçus, un nouveau décompte est lancé et un nouvel événement est déclenché. Vous pouvez désactiver cette fonction à l'aide de l'option Continue counting when event is acknowledged.
L'option Discontinue counting after time has elapsed garantit qu'un événement distinct est toujours ouvert pour chaque période de comparaison. Dans l'exemple ci-dessus, un seuil de 10 messages par heure a été spécifié. Si cette option est activée, un maximum de 10 messages d'une heure sera ajouté à un événement déjà ouvert. Dès que l'heure s'est écoulée, si un nombre suffisant de messages a été reçu, un nouvel événement sera ouvert.
Par exemple, si vous fixez le nombre à 1 et l'intervalle de temps à un jour, vous ne verrez qu'un événement maximum de ce type de message par jour.
Le paramètre Algorithm peut surprendre à première vue. Mais soyons réalistes : qu'entendez-vous par "10 messages par heure" ?De quelle heure s'agit-il ? Toujours des heures entières de la journée ? Il se peut que neuf messages soient reçus dans la dernière minute d'une heure et neuf autres dans la première minute de l'heure suivante. Cela fait alors 18 messages en seulement deux minutes de temps écoulé, mais toujours moins de 10 par heure, et la règle ne s'appliquerait donc pas. Cela ne semble pas très raisonnable...
Comme il n'existe pas de solution unique à ce problème, Checkmk propose trois définitions différentes de la notion de "10 messages par heure":
| Algorithme | Fonctionnalité |
|---|---|
Interval |
L'intervalle de comptage commence au premier message saisissant. Un événement est généré dans la phase counting. Si le temps spécifié s'écoule avant que le décompte ne soit atteint, l'événement est supprimé silencieusement. En revanche, si le décompte est atteint avant l'expiration du délai, l'événement est ouvert immédiatement (et toutes les actions configurées sont déclenchées). |
Token Bucket |
Cet algorithme ne fonctionne pas avec des intervalles de temps fixes, mais met en œuvre une méthode souvent utilisée dans les réseaux pour la mise en forme du trafic. Supposons que vous ayez configuré 10 messages par heure. Cela correspond à une moyenne d'un message toutes les 6 minutes. La première fois qu'un message correspondant est saisi, un événement est généré dans la phase counting et le compte est fixé à 1. Pour chaque message suivant, le compteur est augmenté de 1. Et toutes les 6 minutes, le compteur est à nouveau diminué de 1 - qu'un message soit arrivé ou non. Si le compteur tombe à nouveau à 0, l'événement est supprimé. Le déclencheur est donc activé lorsque le nombre moyen de messages dépasse en permanence 10 par heure. |
Dynamic Token Bucket |
Il s'agit d'une variante de l'algorithme Token Bucket, où plus le compteur est petit à un moment donné, plus il diminue lentement. Dans l'exemple ci-dessus, si le compteur était de 5, il ne diminuerait que toutes les 12 minutes au lieu de toutes les 6 minutes. L'effet global est que les taux de notification juste au-dessus du taux autorisé ouvriront un événement (et seront donc notifiés) beaucoup plus rapidement. |
Quel algorithme choisir ?
Interval est le plus simple à comprendre et le plus facile à suivre si vous souhaitez par la suite effectuer un décompte exact dans votre archive syslog.
Token Bucket est plus intelligent et plus "doux". Il y a moins d'anomalies aux limites des intervalles.
Dynamic Token Bucket rend le système plus réactif et génère des notifications plus rapidement.
Les événements qui n'ont pas encore atteint le nombre fixé sont latents mais ne sont pas automatiquement visibles par l'opérateur. Ils se trouvent dans la phase counting. Vous pouvez rendre ces événements visibles à l'aide du filtre phase dans la vue de la table des événements :
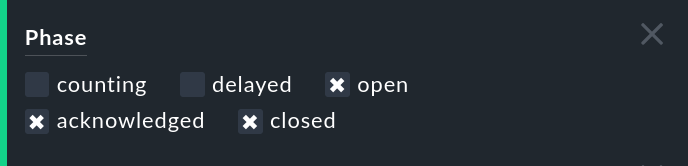
Messages trop rares ou manquants
Tout comme l'arrivée d'un message particulier peut être synonyme de problème, l'absence de message peut également l'être. Vous pouvez vous attendre à recevoir au moins un message par jour de la part d'un travail particulier. Si ce message n'arrive pas, le travail ne fonctionne probablement pas et doit être réparé de toute urgence.
Vous pouvez configurer quelque chose comme cela sous Counting & Timing > Expect regular messages:
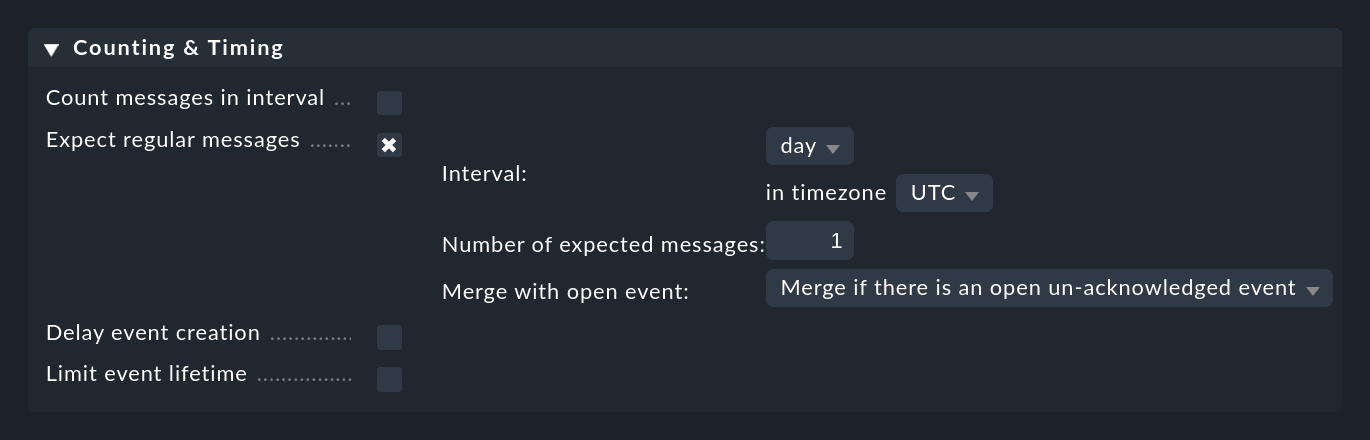
Comme pour le comptage, vous devez spécifier une période de temps au cours de laquelle vous vous attendez à ce que le(s) message(s) apparaisse(nt). Ici, cependant, un algorithme complètement différent est utilisé, ce qui est beaucoup plus logique à ce stade. La période de temps est toujours alignée exactement sur des positions définies. Par exemple, l'intervalle hour commence toujours à la minute et à la seconde zéro. Vous disposez des options suivantes :
| Intervalle | Alignement |
|---|---|
10 seconds |
Sur un nombre de secondes divisible par 10 |
minute |
Sur la minute entière |
5 minutes |
À 0:00, 0:05, 0:10, etc. |
15 minutes |
À 0:00, 0:15, 0:30, 0:45, etc. |
hour |
Au début de chaque heure complète |
day |
Exactement à 00:00, mais dans un fuseau horaire configurable. Cela vous permet également de dire que vous attendez un message entre 12:00 et 12:00 le lendemain. Par exemple, si vous vous trouvez dans le fuseau horaire UTC +1, indiquez UTC -11 hours. |
two days |
Au début d'une heure complète. Vous pouvez spécifier ici un décalage de fuseau horaire de 0 à 47, en référence à 1970-01-01 00:00:00 UTC. |
week |
À 00:00 le jeudi matin dans le fuseau horaire UTC plus le décalage, que vous pouvez exprimer en heures. Jeudi parce que le 1/1/1970 - le début de l'"époque" - était un jeudi. |
Pourquoi est-ce si compliqué ? C'est pour éviter les fausses alertes. Vous attendez-vous à recevoir un message d'une sauvegarde par jour, par exemple ? Il y aura certainement de légères différences dans la durée d'exécution de la sauvegarde, de sorte que les messages ne seront pas reçus à 24 heures d'intervalle. Par exemple, si vous vous attendez à ce que le message arrive vers minuit, à une heure ou deux près, un intervalle de 12:00 à 12:00 sera beaucoup plus réaliste qu'un intervalle de 00:00 à 00:00. Toutefois, si le message n'apparaît pas, vous ne recevrez une notification qu'à 12:00 à midi.
Plusieurs occurrences du même problème
L'option Merge with open event est prédéfinie de telle sorte qu'en cas d'apparition répétée du même message, l'événement existant sera mis à jour. Vous pouvez modifier cette option de manière à ce qu'un nouvel événement soit ouvert à chaque fois.
5.6. Calendrier
Sous Counting & Timing, deux options affectent l'ouverture et/ou la fermeture automatique des événements.
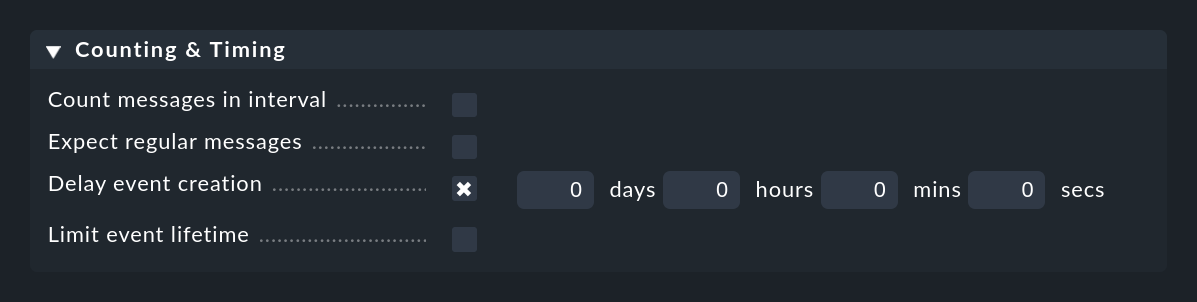
L'option Delay event creation est utile si vous travaillez avec l'annulation automatique d' événements. Définissez par exemple un délai de 5 minutes ; en cas de message d'erreur, l'événement créé restera dans l'état delayed pendant 5 minutes - dans l'espoir que le message OK arrivera dans ce délai. Si c'est le cas, l'événement est fermé automatiquement et sans problème, et n'apparaît pas dans la surveillance. Si le délai expire, cependant, l'événement sera ouvert et l'une de ses actions éventuellement définies sera exécutée :
Limit event lifetime permet de faire plus ou moins l'inverse et de fermer automatiquement les événements après un certain temps. C'est utile, par exemple, pour les événements informatifs avec un statut OK que vous souhaitez afficher, mais pour lesquels vous ne voulez pas que la surveillance génère d'activité. En "éteignant" automatiquement ces messages, vous vous épargnez la suppression manuelle de ces messages :
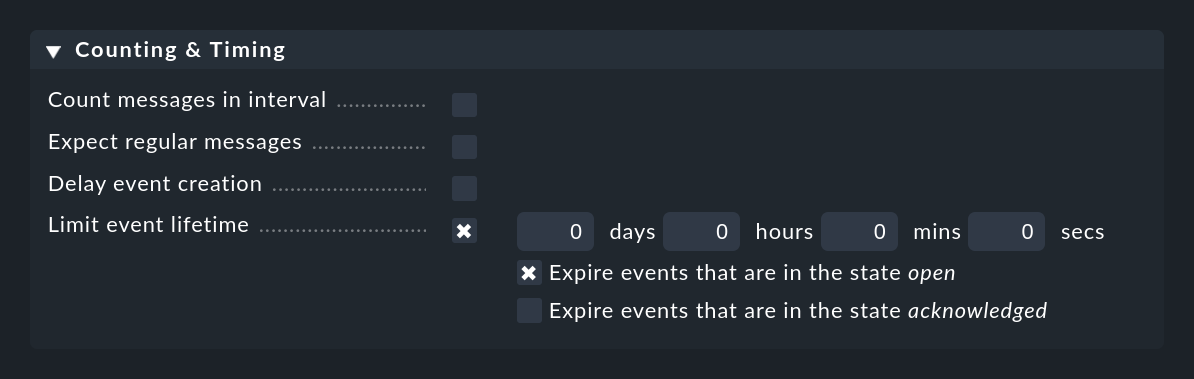
Vous pouvez contrôler ce comportement à l'aide des deux cases à cocher.
5.7. Paquets de règles
Les packs de règles ont non seulement l'avantage de rendre les choses plus gérables, mais ils peuvent également simplifier la configuration de plusieurs règles similaires tout en accélérant l'évaluation.
Supposons que vous ayez un jeu de 20 règles qui tournent toutes autour du journal des événements Windows Security. Toutes ces règles ont en commun de checker la condition pour un certain texte dans le champ d'application (le nom de ce fichier journal est utilisé dans les messages du CE comme Application). Dans un tel cas, procédez comme suit :
Créez votre propre paquet de règles.
Créez les 20 règles pour Security dans ce paquet ou déplacez-les (liste de sélection Move to pack… sur le côté droit du tableau des règles).
Supprimez la condition relative à la demande de toutes ces règles.
Créez comme première règle du paquet une règle en vertu de laquelle les messages quittent immédiatement le paquet si l'application n'est pas Security.
Cette règle d'exclusion est structurée comme suit :
Matching Criteria > Match syslog application (tag) sur
Security.Matching Criteria > Invert matching sur Negate match: Execute this rule if the upper conditions are not fulfilled.
Outcome & Action > Rule type on Skip this rule pack, continue rule execution with next rule pack
Tout message qui ne provient pas du journal de sécurité sera "rejeté" par la première règle de ce paquet. Cela simplifie non seulement les autres règles du paquet, mais accélère également le processus, puisque dans la plupart des cas, les autres règles ne doivent pas être vérifiées du tout.
6. Actions
6.1. Types d'actions
L'Event Console comprend trois types d'actions, que vous pouvez exécuter soit manuellement, soit lorsque vous ouvrez ou annulez des événements :
Exécution de scripts shell auto-écrits.
Envoi de courriers électroniques personnalisés.
Génération de notifications Checkmk.
6.2. Scripts shell et courriers électroniques
Vous devez d'abord définir les courriers électroniques et les scripts dans les paramètres de l'Event Console, sous l'entrée Actions (Emails & Scripts):
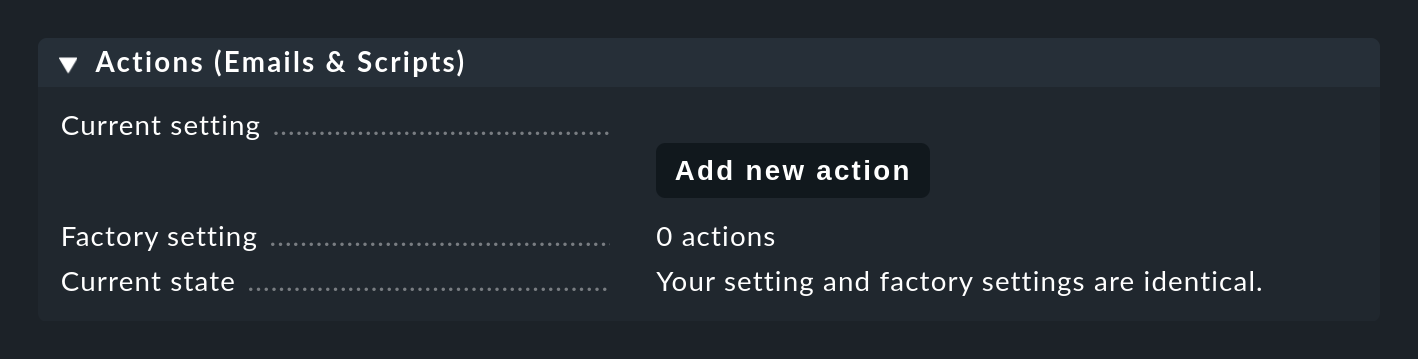
Exécution de scripts shell
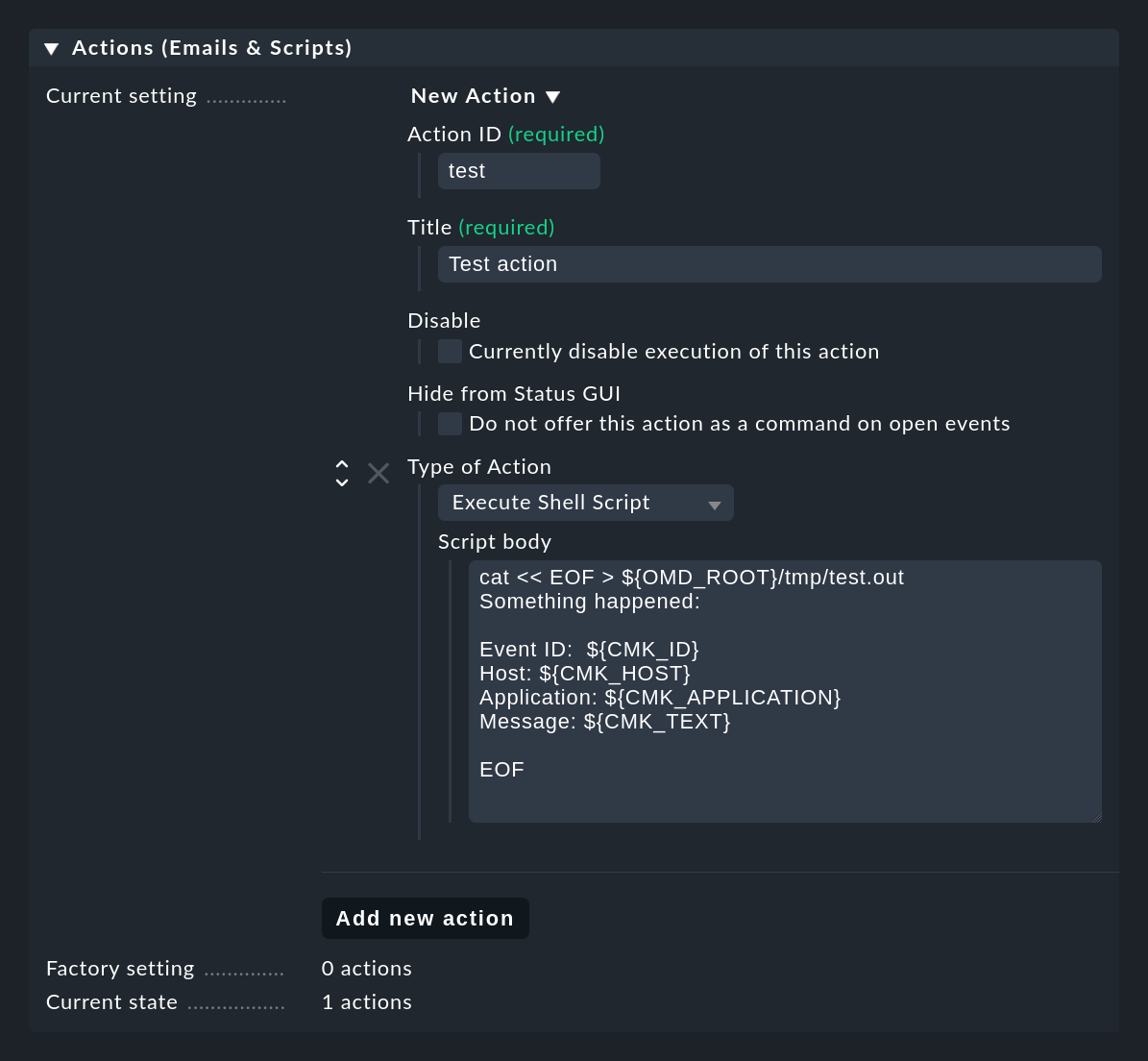
Le bouton Add new action vous permet de créer une nouvelle action. L'exemple suivant montre comment créer un script shell simple en tant qu'action de type Execute Shell Script. Les détails des événements sont disponibles pour le script via les variables d'environnement, par exemple le $CMK_ID de l'événement, le $CMK_HOST, le texte intégral $CMK_TEXT ou le premier groupe de correspondance en tant que $CMK_MATCH_GROUP_1. Pour une liste complète des variables d'environnement disponibles, consultez l'aide en ligne.
Les anciennes versions de Checkmk autorisaient les variables d'environnement ainsi que les macros telles que $TEXT$ qui étaient remplacées avant l'exécution du script. En raison du risque qu'un attaquant puisse injecter des instructions par le biais d'un paquet UDP spécialement conçu qui est exécuté avec les privilèges du processus Checkmk, vous ne devriez pas utiliser de macros. Les macros sont actuellement toujours prises en charge pour des raisons de compatibilité, mais nous nous réservons le droit de les supprimer dans une future version de Checkmk.
L'exemple de script présenté dans la capture d'écran crée le fichier tmp/test.out dans le répertoire d'instances, dans lequel il écrit un texte contenant les valeurs concrètes des variables pour le dernier événement correspondant :
cat << EOF > ${OMD_ROOT}/tmp/test.out
Something happened:
Event-ID: $CMK_ID
Host: $CMK_HOST
Application: $CMK_APPLICATION
Message: $CMK_TEXT
EOFLes scripts sont exécutés dans l'environnement suivant :
/bin/bashest utilisé comme interprète.Le script s'exécute en tant qu'utilisateur de l'instance dans le répertoire personnel de l'instance (par exemple
/omd/sites/mysite).Pendant l'exécution du script, le processus des autres événements est interrompu !
Si votre script contient éventuellement des temps d'attente, vous pouvez l'exécuter de manière asynchrone à l'aide du spooler Linux at. Pour ce faire, créez le script dans un fichier local/bin/myaction distinct et lancez-le à l'aide de l'instruction at, par exemple :
echo "$OMD_ROOT/local/bin/myaction '$HOST$' '$TEXT$' | at nowEnvoi de courrier électronique
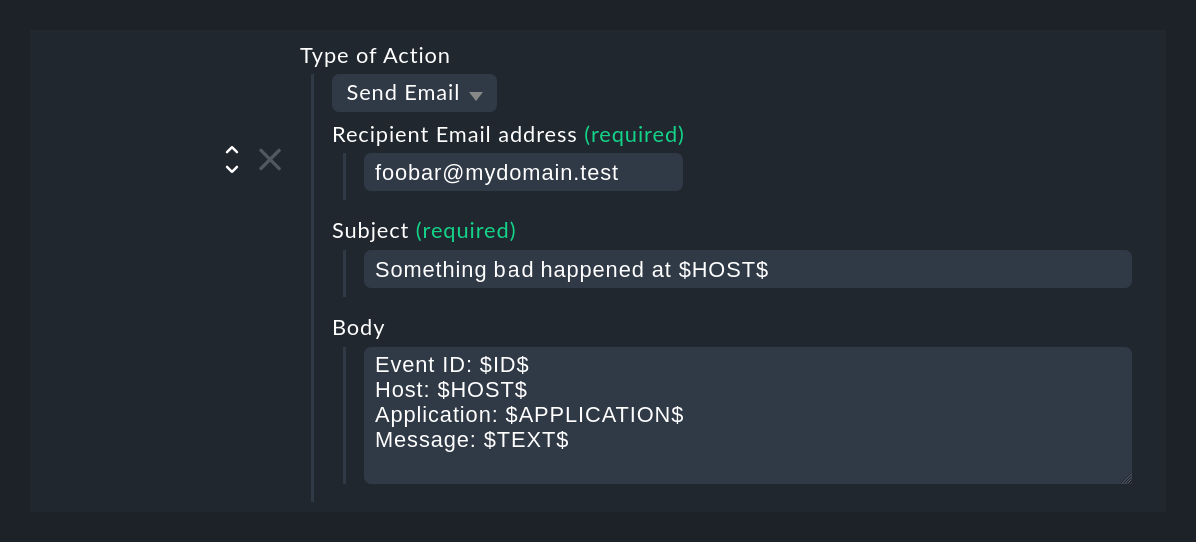
Le type d'action Send Email envoie un simple courrier électronique textuel. En fait, vous pourriez aussi le faire avec un script, par exemple en utilisant l'instruction en ligne de commande mail. Mais de cette façon, c'est plus pratique. Veuillez noter que les caractères génériques sont également autorisés dans les champs Recipient email address et Subject.
6.3. Notifications via Checkmk
Outre l'exécution de scripts et l'envoi de courriers électroniques (simples), le CE dispose d'un troisième type d'action : l'envoi de notifications via le système de notification Checkmk. Les notifications peuvent être générées par le CE de la même manière que les notifications d'hôte et de service issues de la surveillance active. Les avantages par rapport aux simples courriers électroniques décrits ci-dessus sont évidents :
La notification est configurée pour la surveillance active et la surveillance basée sur les événements ensemble dans un emplacement central.
Des fonctionnalités telles que les notifications groupées, les courriers électroniques HTML et d'autres fonctions utiles sont disponibles.
Les règles de notification définies par utilisateur, la désactivation des notifications, etc. fonctionnent comme d'habitude.
Le type d'action Send monitoring notification se déroule toujours automatiquement et ne doit pas être configuré.
Comme les événements diffèrent quelque peu des hôtes ou services 'normaux', leurs notifications présentent quelques particularités que vous découvrirez plus en détail dans la section suivante.
Assignation à des ordinateurs hôtes existants
Les événements peuvent provenir de n'importe quel hôte, qu'il soit ou non configuré dans la surveillance active. En effet, les ports syslog et SNMP sont ouverts à tous les hôtes du réseau. Par conséquent, les attributs d'hôte étendus tels que l'alias, les balises d'hôte, les contacts, etc. ne sont pas disponibles au départ. C'est notamment la raison pour laquelle les conditions des règles de notification ne fonctionnent pas nécessairement comme vous l'auriez souhaité.
Par exemple, lors de la notification, le CE tente de trouver un ordinateur dans la surveillance active qui saisit l'événement. Pour ce faire, il utilise la même procédure que pour la visibilité des événements. Si un tel ordinateur est trouvé, les données suivantes sont extraites de cet ordinateur :
L'orthographe correcte du nom de l'ordinateur.
L'alias de l'ordinateur hôte.
L'adresse IP primaire configurée dans Checkmk.
Les balises de l'hôte
Le dossier dans l'interface graphique de configuration.
La liste des contacts et des groupes de contacts.
Par conséquent, le nom de l'hôte dans la notification traitée peut ne pas correspondre exactement au nom de l'hôte dans le message original. Le codage de textes de notification conformes à ceux de la surveillance active simplifie toutefois la formulation de règles de notification uniformes qui comprennent des conditions s'appliquant au nom de l'hôte.
Le mappage est effectué en temps réel en envoyant une requête Livestatus au noyau de surveillance qui fonctionne sur le même site que le CE qui a reçu le message. Bien entendu, cela ne fonctionne que si les messages syslog, les traps SNMP, etc. sont toujours envoyés au site Checkmk sur lequel l'hôte est activement surveillé !
Si la requête ne fonctionne pas ou si l'hôte est introuvable, des données de substitution seront acceptées :
Nom de l'ordinateur hôte |
Le nom de l'ordinateur hôte de l'événement. |
Alias de l'ordinateur hôte |
Le nom de l'hôte sera utilisé comme alias. |
Adresse IP |
Le champ adresse IP contient l'adresse de l'expéditeur initial du message. |
Balise de l'hôte |
L'hôte ne recevra pas de balise hôte. Si vous avez des groupes de balises hôtes avec des balises vides, l'hôte adopte ces balises, mais sinon il n'a aucune balise du groupe. Gardez cela à l'esprit lorsque vous définissez des conditions relatives aux balises hôte dans les règles de notification. |
Dossier de l'interface graphique de configuration |
Pas de dossier. Toutes les conditions qui se rapportent à un dossier spécifique sont donc irréalisables - même dans le cas du dossier principal. |
Contacts |
La liste des contacts est vide. Si des contacts de repli sont présents, ils seront saisis. |
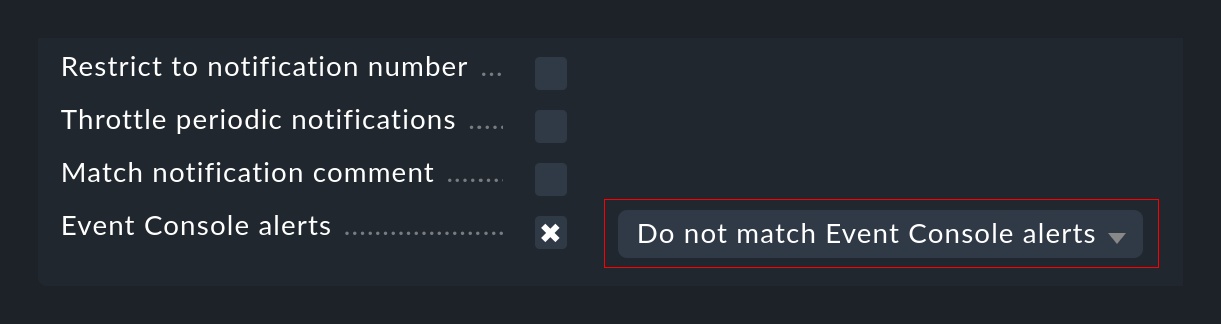
Si l'hôte ne peut pas être attribué dans la surveillance active, cela peut bien sûr entraîner des problèmes au niveau des notifications, d'une part en raison des conditions, qui peuvent alors ne plus s'appliquer, et d'autre part en raison de la sélection des contacts. Dans ce cas, vous pouvez modifier vos règles de notification de manière à ce que les notifications provenant de l'Event Console soient traitées spécifiquement à l'aide de leurs propres règles. Pour ce faire, il existe une condition distincte avec laquelle vous pouvez soit saisir positivement uniquement les notifications de l'EC, soit les exclure à l'inverse :
Autres champs de notification
Pour que les notifications de la CE puissent passer par le système de notification de la surveillance active, la CE doit être adaptée pour se conformer à son schéma. Au cours de ce processus, les champs de données typiques d'une notification sont remplis le plus efficacement possible. Nous venons de décrire comment les données de l'hôte sont déterminées. Les champs restants sont les suivants :
Type de notification |
Les notifications de la CE sont toujours considérées comme des messages de service. |
Description du service |
Il s'agit du contenu du champ Application de l'événement. Si ce champ est vide, |
Numéro de la notification |
Il est fixé à |
Date/Heure |
Pour les événements qui sont comptabilisés, il s'agit de l'heure de la dernière occurrence d'un message associé à l'événement. |
Sortie du plugin |
Le contenu textuel de l'événement. |
État du service |
État de l'événement, c'est-à-dire OK, WARN, CRIT ou UNKNOWN. |
État précédent |
Comme les événements n'ont pas d'état précédent, OK est toujours saisi ici pour les événements normaux, et CRIT est toujours saisi ici lorsque l'on annule un événement. Cette règle est la plus proche de ce qui est nécessaire pour les règles de notification qui ont une condition sur le changement d'état exact. |
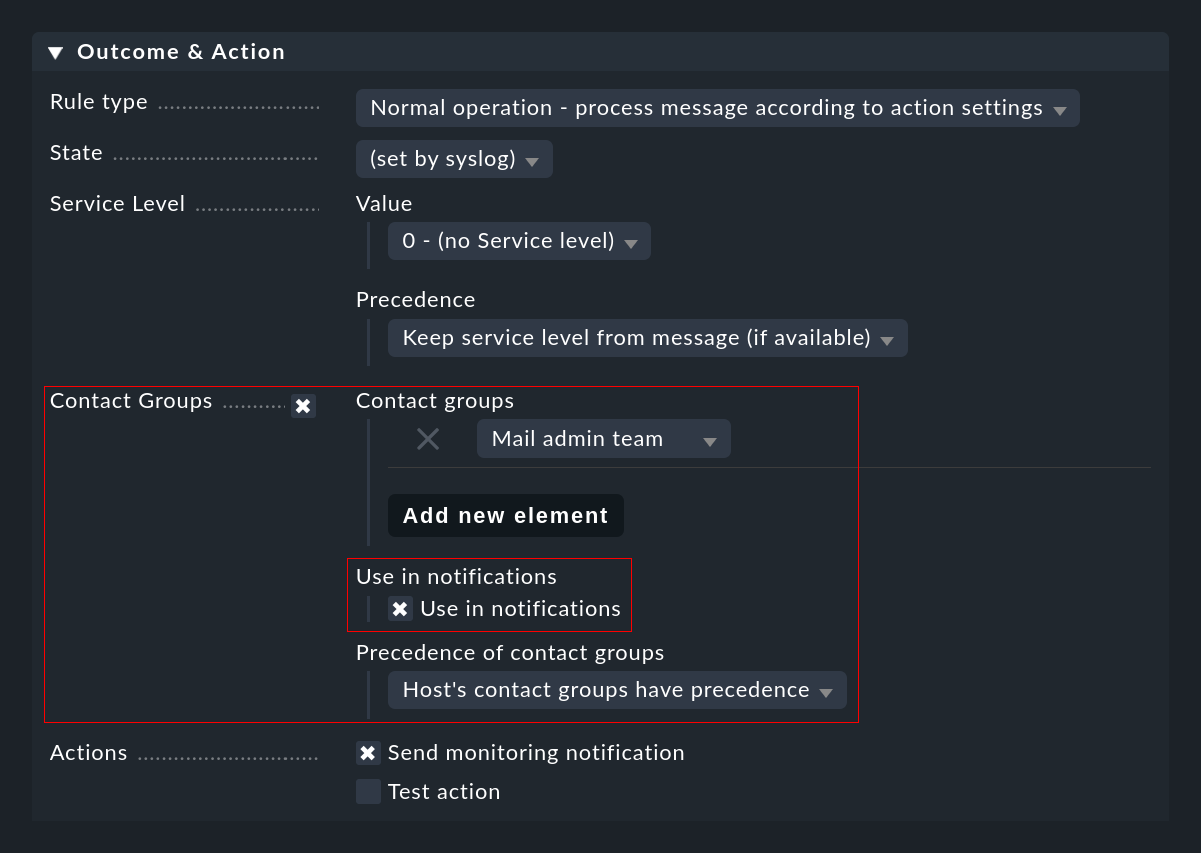
Définition manuelle de groupes de contacts
Comme décrit ci-dessus, il se peut qu'il ne soit pas possible de déterminer automatiquement les contacts pour un événement. Dans ce cas, vous pouvez spécifier des groupes de contacts directement dans la règle CE qui doit être utilisée pour la notification. Il est important que vous n'oubliiez pas de checker la case Use in notifications:
Commutateur central pour les notifications
Il existe un commutateur central pour les notifications dans le snap-in Master control. Ceci s'applique également aux notifications transmises par le CE :

Tout comme pour l'attribution d'un hôte, l'interrogation du commutateur par le CE nécessite un accès Livestatus au commutateur de surveillance local. Une interrogation réussie est visible dans le fichier journal de la console d'événements :
[1482142567.147669] Notifications are currently disabled. Skipped notification for event 44Périodes de maintenance programmées des ordinateurs hôtes
L'Event Console est capable de détecter les hôtes qui sont actuellement dans une période de maintenance programmée et n'envoie pas de notifications dans de telles situations. Dans le fichier journal, cela se présentera comme suit :
[1482144021.310723] Host myserver123 is currently in scheduled downtime. Skipping notification of event 433.Bien entendu, il faut pour cela que l'hôte soit trouvé dans la surveillance active. En cas d'échec, on suppose que l'hôte n' est pas en période de maintenance et une notification est générée dans tous les cas.
Macros supplémentaires
Lorsque vous écrivez vos propres scripts de notification, en particulier pour les notifications provenant de l'Event Console, vous disposez d'un certain nombre de variables supplémentaires qui décrivent l'événement d'origine (accessibles comme d'habitude avec le préfixe NOTIFY_) :
|
ID de l'événement. |
|
ID de la règle qui a créé l'événement. |
|
Priorité syslog sous la forme d'un nombre allant de |
|
Facilité syslog - également sous la forme d'un nombre. La plage de valeurs va de |
|
Phase de l'événement. Étant donné que seuls les événements en cours déclenchent des actions, cette valeur devrait être |
|
Le champ commentaire de l'événement. |
|
Le champ Owner. |
|
Le champ de commentaire avec les informations de contact spécifiques à l'événement. |
|
L'ID du processus qui a envoyé le message (pour les événements syslog). |
|
Les groupes de correspondance des messages saisis dans la règle. |
|
Les groupes de contacts facultatifs définis manuellement dans la règle. |
6.4. Exécution des actions
Dans la section Commandes, vous avez déjà entendu parler de l'exécution manuelle d'actions par l'opérateur. L'exécution automatique d'actions, que vous pouvez configurer à l'aide de règles CE dans la section Outcome & Action, est plus intéressante :
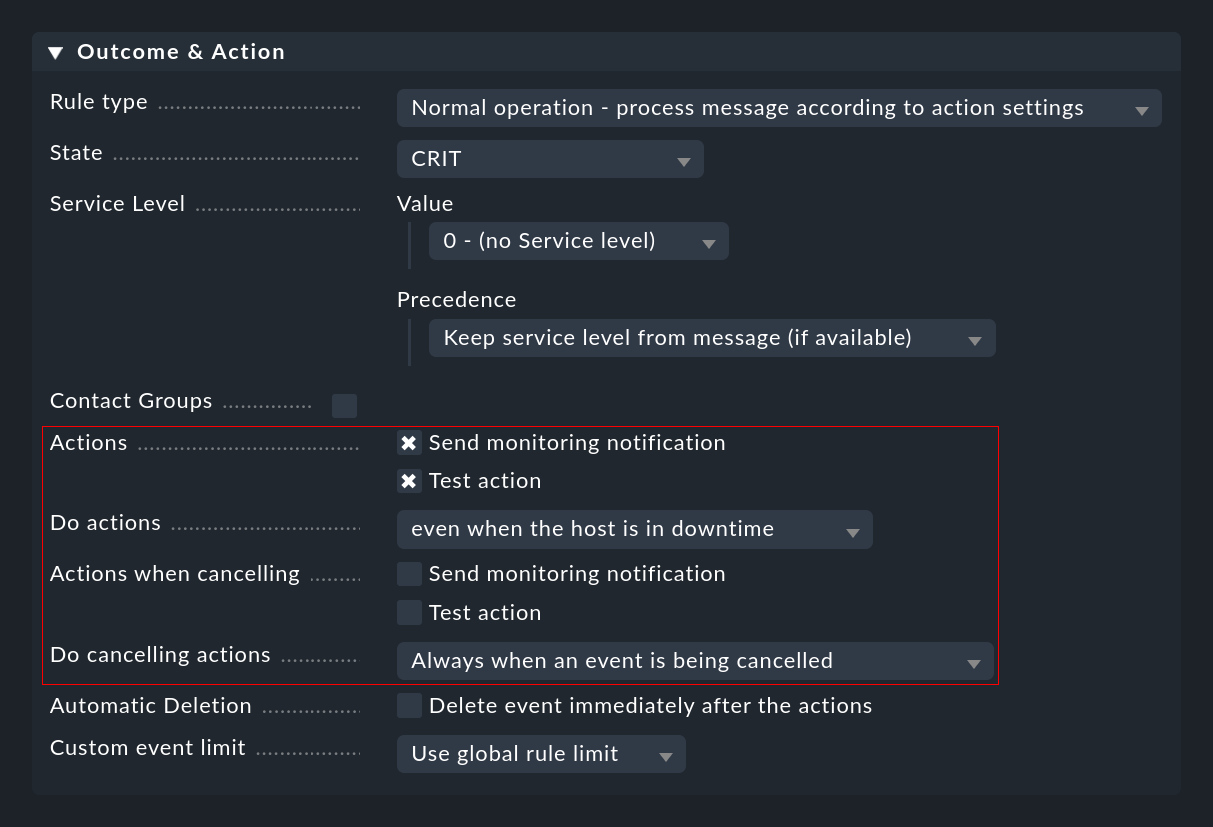
Vous pouvez y sélectionner une ou plusieurs actions qui seront exécutées chaque fois qu'un événement est ouvert ou annulé en fonction de la règle. Pour cette dernière, vous pouvez utiliser la liste Do cancelling actions pour spécifier si l'action ne doit être exécutée que si l'événement annulé a déjà atteint la phase open. Lorsque vous utilisez le comptage ou le délai, il peut arriver que des événements qui sont toujours en attente et qui ne sont pas encore visibles pour l'utilisateur soient annulés.
L'exécution des actions est enregistrée dans le fichier journal var/log/mkeventd.log:
[1481120419.712534] Executing command: ACTION;1;cmkadmin;test
[1481120419.718173] Exitcode: 0Elles sont également écrites dans l'archive.
7. Traps SNMP
7.1. Configuration de la réception des trap SNMP
Comme l'Event Console dispose de son propre moteur SNMP intégré, la configuration de la réception des trap SNMP est très simple. Vous n'avez pas besoin de snmptrapd du système d'exploitation ! Si celui-ci est déjà en cours d'exécution, veuillez l'arrêter.
Comme décrit dans la section sur la configuration de l'Event Console, utilisez omd config pour activer le récepteur de traps sur cette instance :
Étant donné que sur chaque serveur, le port UDP pour les traps ne peut être utilisé que par un seul processus, cette opération ne peut être effectuée que dans un seul site Checkmk par ordinateur. Lorsque vous démarrez l'instance, vous pouvez vérifier dans la ligne contenant mkeventd si la réception des traps a été activée :
OMD[mysite]:~$ omd start
Creating temporary filesystem /omd/sites/mysite/tmp...OK
Starting mkeventd (builtin: snmptrap)...OK
Starting liveproxyd...OK
Starting mknotifyd...OK
Starting rrdcached...OK
Starting cmc...OK
Starting apache...OK
Starting dcd...OK
Starting redis...OK
Initializing Crontab...OKPour que les trap SNMP fonctionnent, l'expéditeur et le destinataire doivent s'accorder sur certaines credentials. Dans le cas de SNMP v1 et v2c, il s'agit d'un simple mot de passe, connu sous le nom de "communauté". Avec la version 3, vous avez besoin de quelques informations d'identification supplémentaires. Vous configurez ces informations d'identification dans les paramètres de l'Event Console sous Credentials for processing SNMP traps. Vous pouvez utiliser le bouton Add new element pour configurer plusieurs informations d'identification différentes, qui peuvent être utilisées comme alternatives par les périphériques :
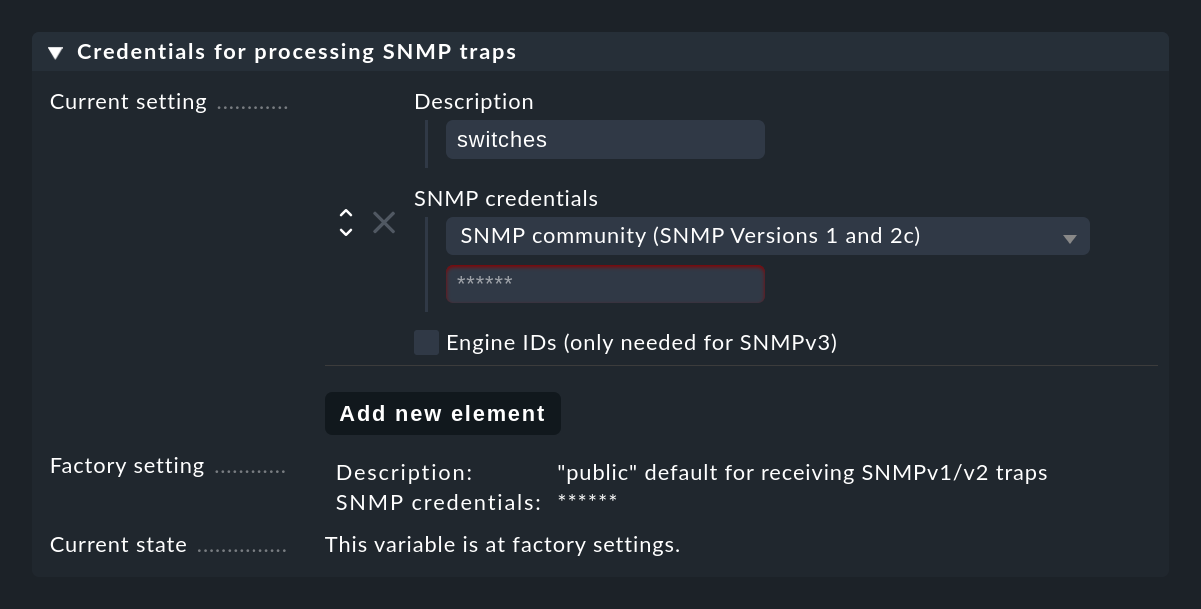
La partie la plus complexe consiste maintenant, bien sûr, à spécifier l'adresse cible pour tous les dispositifs qui doivent être surveillés et à configurer les informations d'identification à cet endroit ainsi que les informations d'identification.
7.2. Les tests
Malheureusement, très peu de dispositifs offrent des capacités de test significatives. Au moins, vous pouvez facilement tester la réception des trappes manuellement à l'aide de l'Event Console elle-même en envoyant une trappe de test - de préférence à partir d'un autre système Linux. Cela peut se faire avec l'instruction snmptrap. L'exemple suivant envoie une trappe à 192.168.178.11. Le nom d'hôte de l'expéditeur est spécifié après .1.3.6.1 et doit pouvoir être résolu ou être spécifié en tant qu'adresse IP (ici 192.168.178.30) :
user@host:~$ snmptrap -v 1 -c public 192.168.178.11 .1.3.6.1 192.168.178.30 6 17 '' .1.3.6.1 s "Just kidding"Si vous avez défini Log level à Verbose logging dans les paramètres, vous pourrez voir la réception et l'évaluation des pièges dans le fichier journal du CE :
[1482387549.481439] Trap received from 192.168.178.30:56772. Checking for acceptance now.
[1482387549.485096] Trap accepted from 192.168.178.30 (ContextEngineId "0x80004fb8054b6c617070666973636816893b00", ContextName "")
[1482387549.485136] 1.3.6.1.2.1.1.3.0 = 329887
[1482387549.485146] 1.3.6.1.6.3.1.1.4.1.0 = 1.3.6.1.0.17
[1482387549.485186] 1.3.6.1.6.3.18.1.3.0 = 192.168.178.30
[1482387549.485219] 1.3.6.1.6.3.18.1.4.0 =
[1482387549.485238] 1.3.6.1.6.3.1.1.4.3.0 = 1.3.6.1
[1482387549.485258] 1.3.6.1 = Just kiddingEn cas d'identifiants incorrects, vous ne verrez qu'une seule ligne :
[1482387556.477364] Trap received from 192.168.178.30:56772. Checking for acceptance now.Et voici à quoi ressemble un événement généré par un tel piège :

7.3. Transformer les chiffres en texte : Traduire les pièges
Le SNMP est un protocole binaire et il est très avare en descriptions textuelles des messages. Le type de piège est communiqué en interne par une séquence de nombres dans ce que l'on appelle les OID. Ceux-ci sont affichés sous la forme de séquences de nombres séparés par des points (par exemple, 1.3.6.1.6.3.18.1.3.0).
À l'aide des fichiers MIB, l'Event Console peut traduire ces séquences numériques en textes, par exemple, 1.3.6.1.6.3.18.1.3.0 devient le texte SNMPv2-MIB::sysUpTime.0.
La traduction des pièges peut être activée dans les paramètres de l'Event Console :

Le piège test ci-dessus génère maintenant un événement légèrement différent :

Si vous avez activé l'option Add OID descriptions, l'ensemble devient beaucoup plus détaillé - et plus confus. Cela permet toutefois de mieux comprendre ce que fait réellement un piège :

7.4. Téléchargement de vos propres MIB
Malheureusement, les avantages de l'open source ne se sont pas encore étendus aux auteurs de fichiers MIB, et c'est pourquoi le projet Checkmk n'est malheureusement pas en mesure de fournir des fichiers MIB spécifiques aux fournisseurs. Seule une petite collection de MIB de base gratuits est préinstallée, qui prévoit par exemple une traduction de sysUpTime. Vous pouvez toutefois ajouter ces fichiers à la base de données de Checkmk.
Vous pouvez toutefois ajouter ces fichiers à la Event Console dans le module SNMP MIBs for trap translation via l'entrée de menu Add one or multiple MIBs pour télécharger vos propres fichiers MIB, comme c'est le cas ci-dessous avec certains MIB de Netgear Smart Switches:
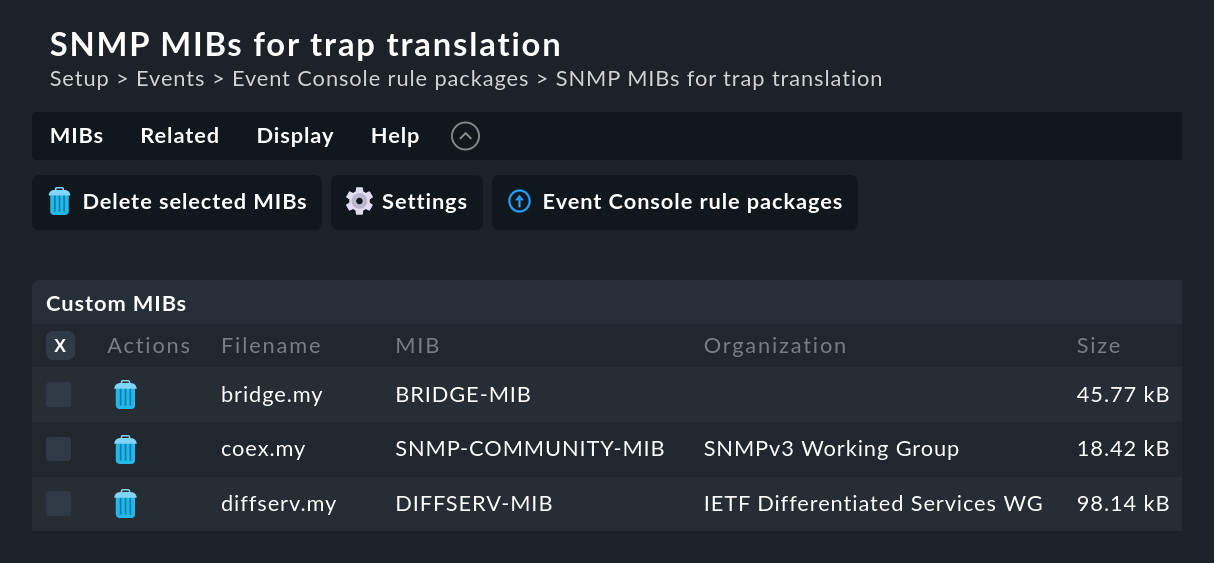
Notes on the MIBs :
Les fichiers téléchargés sont stockés sous
local/share/snmp/mibs. Vous pouvez également les y stocker manuellement si la méthode via l'interface graphique est trop lourde pour vous.Au lieu de fichiers individuels, vous pouvez également télécharger des fichiers ZIP contenant des collections de MIB en une seule action.
Les MIB sont dépendantes les unes des autres. Les MIB manquantes vous seront indiquées par Checkmk.
Les MIB téléchargées sont également utilisées en ligne d'instruction par
cmk --snmptranslate.
8. Surveillance des fichiers journaux
L'agent Checkmk est en mesure d'analyser les fichiers journaux via le plugin Logwatch. Ce plugin assure tout d'abord sa propre surveillance des fichiers journaux indépendamment de la console d'événements - y compris la possibilité d'accuser réception des messages directement dans la surveillance. Il est également possible de transférer les messages trouvés par le plugin 1:1 dans l'Event Console.
Dans l'agent Windows, la surveillance des fichiers journaux est intégrée en permanence - sous la forme d'un plugin pour l'évaluation des fichiers texte et d'un autre pour l'évaluation des journaux d'événements Windows. Le plugin codé en Python mk_logwatch est disponible pour Linux et Unix. Tous les trois sont accessibles via l'Agent Bakery pour leur installation ou leur configuration. Utilisez les jeux de règles suivants pour ce faire :
Text logfiles (Linux, Solaris, Windows)
Finetune Windows Eventlog monitoring
La configuration précise du plugin Logwatch n'est pas le sujet de cet article, mais il est important que vous effectuiez toujours le meilleur pré-filtrage possible des messages dans le plugin Logwatch lui-même et que vous ne vous contentiez pas d'envoyer le contenu complet des fichiers texte à l'Event Console.
Ne confondez pas ceci avec la reclassification ultérieure via le jeu de règles Logfile patterns, qui ne peut que modifier le statut des messages déjà envoyés par l'agent. Toutefois, si vous avez déjà configuré ces modèles et que vous souhaitez simplement passer de Logwatch à l'Event Console, vous pouvez conserver les modèles. À cette fin, les règles de transfert (Logwatch Event Console Forwarding) comprennent l'option Reclassify messages before forwarding them to the EC.
Dans ce cas, tous les messages passent par trois chaînes de règles au total : sur l'agent, par la reclassification et dans l'Event Console !
Modifiez maintenant Logwatch de manière à ce que les messages trouvés par les plugins ne soient plus surveillés par le check normal de Logwatch, mais simplement transmis 1:1 à l'Event Console et y soient traités. Cela se fait avec le jeu de règles Logwatch Event Console Forwarding:
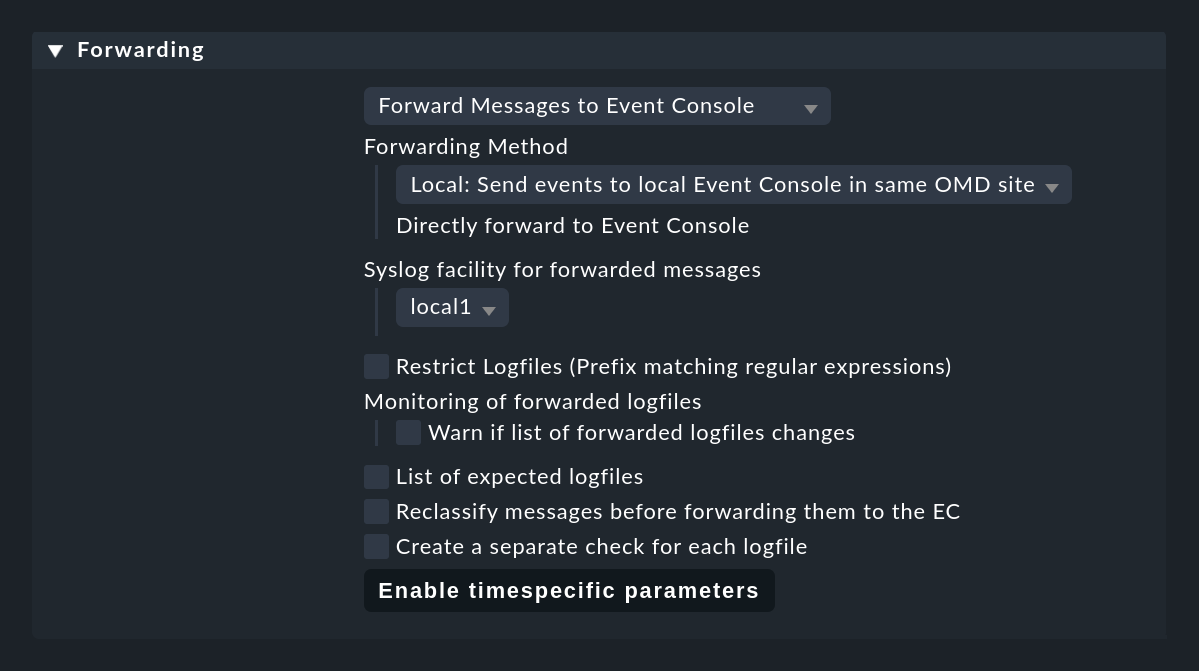
Quelques remarques à ce sujet :
Si vous disposez d'un environnement distribué dans lequel chaque site ne dispose pas de sa propre Event Console, les sites distants doivent transmettre leurs messages au site central via syslog. Le protocole par défaut est UDP, mais il ne s'agit pas d'un protocole sécurisé. Une meilleure solution consiste à utiliser syslog via TCP, mais vous devez l'activer sur l'instance centrale (omd config).
Lors du transfert, indiquez n'importe quel Syslog facility, ce qui vous permettra de reconnaître facilement les messages transférés dans le CE. Les adresses local0 et local7 sont particulièrement adaptées à cette fin.
Avec List of expected logfiles, vous pouvez surveiller la liste des fichiers journaux attendus et être averti si certains fichiers ne sont pas trouvés comme prévu.
Important : L'enregistrement de la règle ne sert à rien. Cette règle n'est activée que lors d'une identification de service. Ce n'est que lorsque vous l'exécutez à nouveau que les services Logwatch précédents sont supprimés et qu'un nouveau service, nommé Log Forwarding, est créé pour chaque hôte.

Ce check vous indiquera également plus tard si des problèmes surviennent lors de la transmission vers l'Event Console.
8.1. Niveau de service et priorités syslog
Étant donné que les fichiers journaux transférés manquent souvent de classification syslog en fonction du format utilisé, vous pouvez définir la reclassification dans le jeu de règles Logwatch Event Console Forwarding sous Log Forwarding. En outre, dans les jeux de règles que vous définissez dans le cadre de Rule packs, il est toujours possible de définir le statut et les niveaux de service individuellement.
9. État des événements dans la surveillance active
Si vous souhaitez également voir quels hôtes de la surveillance active ont des événements problématiques ouverts, vous pouvez ajouter un check actif pour chaque hôte qui résume le statut de l'événement actuel de l'hôte. Pour un hôte qui n'a pas d'événement ouvert, cela se présentera comme suit :

S'il n'y a que des événements dans l'état OK, le check indique leur nombre, mais reste vert :

Voici un exemple de cas avec des événements ouverts dans l'état CRIT:

Vous créez ce check actif à l'aide d'une règle dans le jeu de règles Check event state in Event Console. Vous pouvez également spécifier si les événements qui ont déjà fait l'objet d'un accusé de réception doivent toujours contribuer au statut :
L'option Application (regular expression) vous permet de limiter le contrôle aux événements dont le champ d'application contient un texte spécifique. Dans ce cas, il peut être judicieux de disposer de plusieurs contrôles d'événements sur un hôte et de séparer les contrôles par application. Pour les distinguer par leur nom, vous avez également besoin de l'option Item (used in service description), qui ajoute un texte que vous spécifiez au nom du service.
Si votre Event Console ne fonctionne pas sur le même site Checkmk que celui qui surveille également l'hôte, vous devez configurer Access to Event Console pour un accès à distance via TCP :
Pour que cela fonctionne, l'Event Console doit autoriser l'accès via TCP, ce que vous pouvez configurer dans les paramètres de l'Event Console à laquelle il faut accéder :
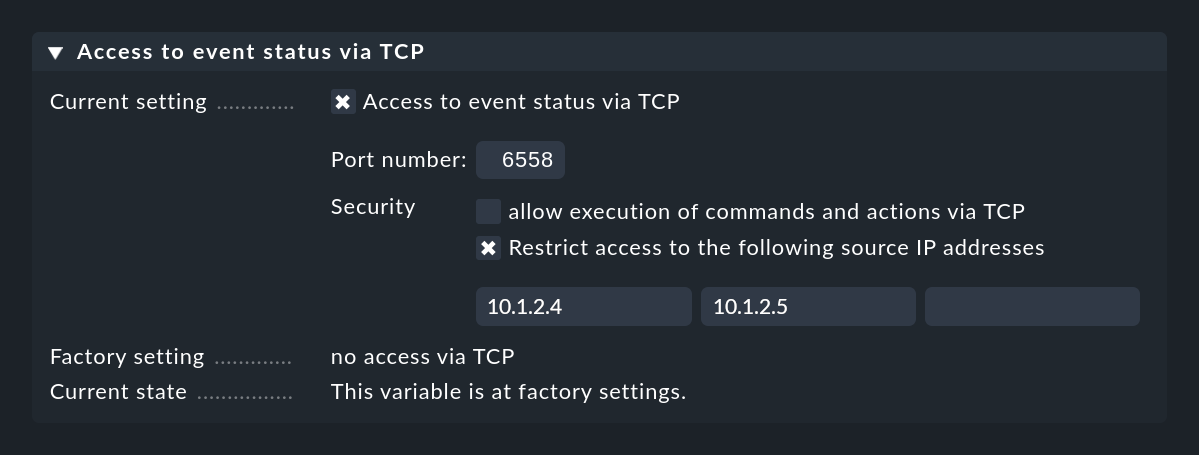
10. Les archives
10.1. Fonctionnement de l'archive
L'Event Console conserve un journal de tous les changements subis par un événement. Ce journal peut être consulté de deux manières :
Dans la vue globale Recent event history, que vous trouverez à l'adresse Monitor > Event Console.
Dans les détails d'un événement via l'élément de menu Event Console Event > History of Event.
La vue globale comporte un filtre qui n'affiche que les événements des dernières 24 heures, mais, comme d'habitude, vous pouvez personnaliser les filtres.
La figure suivante montre l'historique de l'événement 33, qui a subi au total quatre modifications : l'événement a d'abord été créé (NEW), puis l'état a été modifié manuellement de OK à WARN (CHANGESTATE), puis confirmé avec un commentaire ajouté (UPDATE), et enfin l'événement a été archivé/supprimé (DELETE) :

L'archive contient les types d'action suivants, qui sont affichés dans la colonne Action:
| Type d'action | Description de l'action |
|---|---|
|
L'événement a été nouvellement créé (en raison d'un message reçu ou d'une règle attendant un message qui n'est pas apparu). |
|
L'événement a été édité par l'opérateur (modification du commentaire, des coordonnées, de la confirmation). |
|
L'événement a été archivé. |
|
L'événement a été automatiquement annulé par un message OK. |
|
L'état de l'événement a été modifié par l'opérateur. |
|
L'événement a été automatiquement archivé parce qu'aucune règle n'a été appliquée et que Force message archiving a été activé dans les paramètres globaux. |
|
L'événement a été automatiquement archivé car, alors qu'il se trouvait dans la phase counting, la règle qui lui était associée a été supprimée. |
|
L'événement a été déplacé de counting à open parce que le nombre de messages configuré a été atteint. |
|
L'événement a été automatiquement archivé parce que le nombre de messages requis n'a pas été atteint dans counting. |
|
L'événement a été automatiquement archivé parce que, alors qu'il se trouvait dans la phase counting, la règle qui lui était associée a été remplacée par "do not count" (ne pas compter). |
|
L'événement a été ouvert parce que le délai configuré dans la règle a expiré. |
|
L'événement a été automatiquement archivé parce que sa durée de vie configurée a expiré. |
|
Un courrier électronique a été envoyé. |
|
Une action automatique (script) a été exécutée. |
|
L'événement a été automatiquement archivé immédiatement après son ouverture, car cela a été configuré dans la règle correspondante. |
10.2. Emplacement de l'archive
Comme indiqué ci-dessus, l'archive de l'Event Console n'a pas été conçue comme une archive syslog à part entière. Pour simplifier au maximum la mise en œuvre et surtout l'administration, on a renoncé à un backend de base de données. Au lieu de cela, l'archive est écrite dans de simples fichiers texte. Chaque entrée consiste en une ligne de texte, qui contient des colonnes séparées par des onglets. Vous pouvez trouver les fichiers à l'adresse ~/var/mkeventd/history:
OMD[mysite]:~$ ll var/mkeventd/history/
total 1328
-rw-rw-r-- 1 stable stable 131 Dec 4 23:59 1480633200.log
-rw-rw-r-- 1 stable stable 1123368 Dec 5 23:39 1480892400.log
-rw-rw-r-- 1 stable stable 219812 Dec 6 09:46 1480978800.logPar défaut, un nouveau fichier est lancé automatiquement chaque jour. Dans les paramètres de l'Event Console, vous pouvez personnaliser la rotation du fichier. Le paramètre Event history logfile rotation vous permet de passer à une rotation hebdomadaire.
Les noms des fichiers sont conformes à l'heure Unix de création du fichier (secondes depuis le 1/1/1970 UTC).
Les fichiers sont conservés pendant 365 jours, sauf si vous modifiez cette durée dans le paramètre Event history lifetime. En outre, les fichiers sont également enregistrés par la gestion centrale de l'espace disque de Checkmk, qui peut être configurée dans les paramètres globaux sous Site management. Dans ce cas, la limite de temps la plus courte fixée dans chaque cas s'applique. La gestion globale présente l'avantage de supprimer automatiquement les données historiques de Checkmk de manière cohérente, en commençant par les plus anciennes, si l'espace disque disponible devient marginal.
Si vous rencontrez des problèmes d'espace, vous pouvez aussi simplement supprimer manuellement les fichiers du répertoire ou les échanger. Ne mettez pas de fichiers zippés ou d'autres fichiers dans ce répertoire.
10.3. Archivage automatique
Malgré les limites des fichiers texte, il est théoriquement possible d'archiver un grand nombre de messages dans l'Event Console. L'écriture dans les fichiers texte de l'archive est très performante - mais au prix d'une recherche ultérieure moins efficace. Comme les fichiers n'ont pour index que la période de la requête, pour toute requête, tous les fichiers pertinents doivent être lus et faire l'objet d'une recherche complète.
Normalement, le CE n'écrira dans les archives que les messages pour lesquels un événement a effectivement été ouvert. Vous pouvez procéder de deux manières différentes pour étendre ce principe à tous les événements :
Vous créez une règle qui saisit tous les événements (ultérieurs) et activez l'option Delete event immediately after the actions dans Outcome & actions.
Vous activez l'option Force message archiving dans les paramètres de l'Event Console.
Cette dernière méthode garantit que les messages qui ne sont soumis à aucune règle sont néanmoins enregistrés dans l'archive (type d'action ARCHIVED).
11. Performances et réglages
11.1. Traitement des messages
Même à l'époque où les serveurs disposent de 64 cœurs et de 2 To de mémoire principale, la performance des logiciels joue encore un rôle. Dans des situations extrêmes, les messages entrants peuvent être perdus, en particulier lors du traitement des événements.
La raison en est qu'aucun des protocoles utilisés (Syslog, traps SNMP, etc.) ne prévoit de contrôle de flux. Si des milliers d'hôtes envoient simultanément des messages chaque seconde, le récepteur n'a aucune chance de les ralentir.
C'est pourquoi, dans des environnements un peu plus vastes, il est important que vous surveilliez les temps de processus des messages, qui dépendent du nombre de règles que vous avez définies et de la manière dont elles sont structurées.
Mesurer les performances
Pour mesurer vos performances, vous disposez d'un snap-in séparé dans la barre latérale, appelé Event Console Performance. Vous pouvez l'inclure comme d'habitude avec :
Les valeurs affichées ici sont des moyennes sur la dernière minute environ. Une tempête d'événements qui ne dure que quelques secondes ne peut pas être lue directement ici, mais les chiffres ont été quelque peu lissés et sont donc plus faciles à lire.
Pour tester les performances maximales, vous pouvez générer artificiellement une tempête de messages non classifiés (uniquement dans le système de test, s'il vous plaît !), par exemple, dans une boucle de shell en écrivant continuellement le contenu d'un fichier texte dans le tuyau d'événements.
OMD[mysite]:~$ while true ; do cat /etc/services > tmp/run/mkeventd/events ; doneLes lectures les plus importantes du snap-in ont la signification suivante :
| Valeur | Signification |
|---|---|
Received messages |
Nombre de messages actuellement reçus par seconde. |
Rule tries |
Nombre de règles essayées. Ce paramètre fournit des informations précieuses sur l'efficacité de la chaîne de règles - en particulier avec le paramètre suivant. |
Rule hits |
Nombre de règles par seconde qui sont actuellement frappées. Il peut également s'agir de règles qui rejettent des messages ou qui se contentent de compter. Par conséquent, chaque règle frappée ne donne pas lieu à un événement. |
Rule hit ratio |
Le rapport entre Rule tries et Rule hits. En d'autres termes : Combien de règles le CE doit-il essayer avant qu'une ne prenne (enfin) effet. Dans l'exemple de la capture d'écran, le taux est alarmant. |
Created events |
Nombre de nouveaux événements créés par seconde. Étant donné que l'Event Console ne doit afficher que les problèmes pertinents (comparables aux problèmes d'hôte et de service issus de la surveillance), le nombre |
Processing time per message |
Vous pouvez lire ici combien de temps a duré le processus de traitement d'un message. Attention : En général, il ne s'agit pas de l'inverse de Received messages. En effet, les périodes pendant lesquelles l'Event Console n'a rien eu à faire sont toujours manquantes, tout simplement parce qu'aucun message n'est arrivé. Ici, vous mesurez vraiment le temps écoulé purement réel entre l'arrivée d'un message et l'achèvement final du processus. Vous pouvez voir approximativement combien de messages la CE peut traiter dans un temps donné. Notez également qu'il ne s'agit pas de temps CPU, mais de temps réel. Sur un système disposant de suffisamment d'unités centrales libres, ces temps sont à peu près identiques. Mais dès que le système est tellement sous charge que tous les processus n'obtiennent pas toujours un CPU, le temps réel peut devenir beaucoup plus élevé. |
Conseils de réglage
Vous pouvez voir combien de messages l'Event Console peut traiter par seconde à partir de Processing time per message. Ce temps est généralement lié au nombre de règles qui doivent être essayées avant qu'un message ne soit traité. Vous disposez de plusieurs options d'optimisation à cet égard :
Les règles qui excluent de très nombreux messages doivent être placées autant que possible au début de la chaîne de règles.
Utilisez des ensembles de règles pour regrouper des jeux de règles connexes. La première règle de chaque ensemble doit quitter l'ensemble immédiatement si la condition de base commune n'est pas remplie.
Pour chaque combinaison de priorité et de facilité, une chaîne de règles distincte est créée en interne, dans laquelle seules les règles pertinentes pour les messages de cette combinaison sont incluses.
Chaque règle qui contient une condition sur la priorité, la facilité ou de préférence les deux, ne sera pas incluse dans toutes ces chaînes de règles, mais de préférence dans une seule. Cela signifie que la règle n'a pas besoin d'être checkée pour les messages avec une classification syslog différente.
Après un redémarrage, vous trouverez à l'adresse ~/var/log/mkeventd.log un aperçu des chaînes de règles optimisées :
[8488808306.233330] kern : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233343] user : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233355] mail : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233367] daemon : emerg(120) alert(89) crit(89) err(89) warning(89) notice(89) info(89) debug(89)
[8488808306.233378] auth : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233389] syslog : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233408] lpr : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233482] news : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233424] uucp : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233435] cron : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233446] authpriv : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233457] ftp : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233469] (unused 12) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233480] (unused 13) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233498] (unused 13) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233502] (unused 14) : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233589] local0 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233538] local1 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233542] local2 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233552] local3 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233563] local4 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233574] local5 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233585] local6 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233595] local7 : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)
[8488808306.233654] snmptrap : emerg(112) alert(67) crit(67) err(67) warning(67) notice(67) info(67) debug(67)Dans l'exemple ci-dessus, vous pouvez voir que 67 règles doivent être vérifiées dans tous les cas. Pour les messages provenant de l'installation daemon, 89 règles sont pertinentes, et seulement pour la combinaison daemon/emerg, 120 règles doivent être vérifiées. Chaque règle qui reçoit une condition sur la priorité ou l'installation réduit encore le nombre de 67.
Bien entendu, vous ne pouvez définir ces conditions que si vous êtes sûr qu'elles sont remplies par les messages concernés !
11.2. Le nombre d'événements en cours
Le nombre d'événements en cours peut également affecter les performances de la CE - c'est-à-dire lorsqu'elle devient sérieusement incontrôlable. Comme indiqué précédemment, la CE ne doit pas être considérée comme un substitut à une archive syslog, mais uniquement comme un moyen d'afficher les "problèmes en cours". L'Event Console peut certainement traiter plusieurs milliers de problèmes, mais ce n'est pas son véritable objectif.
Dès que le nombre d'événements en cours dépasse environ 5 000, les performances commencent à se dégrader sensiblement. D'une part, cela se voit dans l'interface graphique, qui réagit plus lentement aux demandes. D'autre part, le processus devient également plus lent, car dans certaines situations, les messages doivent être comparés à tous les événements en cours. Les exigences en matière de mémoire peuvent également devenir problématiques.
Pour des raisons de performance, l'Event Console conserve toujours tous les événements en cours dans la mémoire vive. Ceux-ci sont écrits dans le fichier ~/var/mkeventd/status une fois par minute (réglable) et lorsque le traitement est terminé. Si ce fichier devient très volumineux (plus de 50 mégaoctets, par exemple), ce processus devient également de plus en plus lent. Vous pouvez vérifier rapidement la taille actuelle avec ll. (alias de ls -alF) :
OMD[mysite]:~$ ll -h var/mkeventd/status
-rw-r--r-- 1 mysite mysite 386K Dez 14 13:46 var/mkeventd/statusSi vous avez trop d'événements en cours en raison d'une règle maladroite (par exemple, une règle qui saisit tout), une suppression manuelle via l'interface graphique n'est pas raisonnablement possible. Dans ce cas, il suffit de supprimer le fichier d'état :
OMD[mysite]:~$ omd stop mkeventd
Stopping mkeventd...killing 17436......OK
OMD[mysite]:~$ rm var/mkeventd/status
OMD[mysite]:~$ omd start mkeventd
Starting mkeventd (builtin: syslog-udp)...OKAttention : Bien entendu, tous les événements en cours seront perdus, de même que le compteur enregistré et les autres états. En particulier, les nouveaux événements recommenceront avec l'ID 1.
Protection automatique contre les débordements
L'Event Console dispose d'une protection automatique contre les débordements, qui limite le nombre d'événements en cours par hôte, par règle et globalement. Sont pris en compte non seulement les événements ouverts, mais aussi les événements se trouvant dans d'autres phases, telles que delayed ou counting. Les événements archivés ne sont pas pris en compte.
Cela vous protège dans les situations où, en raison d'un problème systématique sur votre réseau, des milliers d'événements critiques affluent et l'Event Console "s'arrête". D'une part, cela évite une dégradation des performances de l'Event Console, qui devrait contenir trop d'événements dans sa mémoire principale. D'autre part, l'aperçu pour l'opérateur est (quelque peu) protégé et les événements qui ne font pas partie de l'orage restent visibles.
Lorsqu'une limite est atteinte, l'une des actions suivantes se produit :
La création de nouveaux événements est arrêtée (pour cet hôte, cette règle ou globalement).
La même chose, mais en plus un "événement de débordement" est créé.
La même chose, mais en plus les contacts appropriés sont notifiés.
En alternative aux trois variantes ci-dessus, vous pouvez également supprimer l'événement le plus ancien pour faire de la place au nouveau.
Les limites ainsi que l'effet associé lorsqu'elles sont atteintes sont définis dans les paramètres de l'Event Console à l'aide de Limit amount of current events. L'illustration suivante montre le paramètre par défaut :
Si vous avez activé une valeur avec …create overflow event, lorsque la limite est atteinte, un événement artificiel unique sera créé, informant l'opérateur de la situation d'erreur :
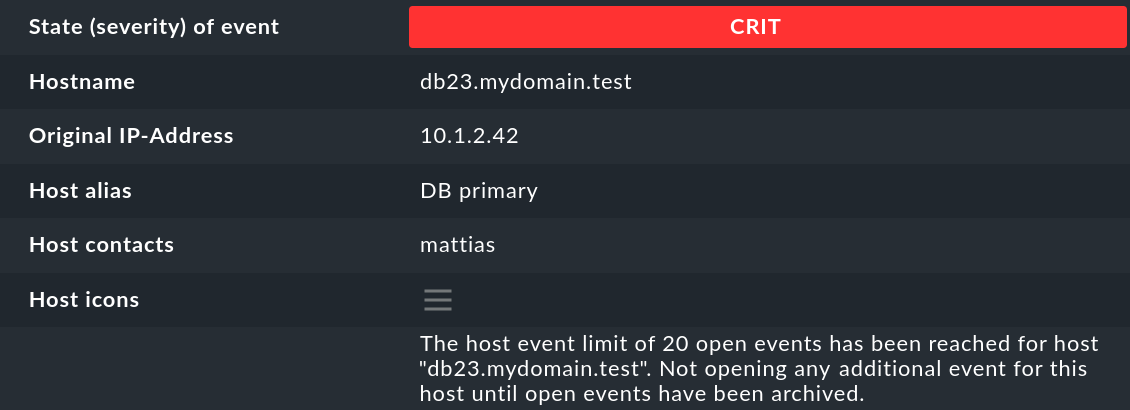
Si vous avez en outre activé une valeur avec …notify contacts, les contacts appropriés seront avertis par notification Checkmk. Cette notification passera par les règles de notification Checkmk. Ces règles ne doivent pas nécessairement suivre la sélection des contacts de l'Event Console, mais peuvent la modifier. Le tableau suivant montre quels contacts sont sélectionnés si vous avez défini Notify all contacts of the notified host or service (ce qui est le cas par défaut) :
| Limite | Sélection de contact |
|---|---|
par ordinateur hôte |
Les contacts de l'hôte, qui sont déterminés de la même manière que pour la notification d'événements via Checkmk. |
par règle |
Laissez le champ du nom de l'ordinateur vide. Si des groupes de contacts sont définis dans la règle, ils seront sélectionnés, sinon les contacts de repli s'appliqueront. |
Global |
Les contacts de repli. |
11.3. Archives trop volumineuses
Comme indiqué ci-dessus, l'Event Console dispose d'une archive de tous les événements et de leurs processus de traitement. Cette archive est stockée dans des fichiers texte pour faciliter la mise en œuvre et l'administration.
Les fichiers texte sont difficiles à battre en termes de performance lors de l'écriture de données - en utilisant des bases de données, par exemple, seulement avec un énorme effort d'optimisation. Cela est dû, entre autres, à l'optimisation de ce type d'accès par Linux et à la hiérarchie complète de la mémoire des disques et des SAN. Cependant, cela se fait au détriment des accès en lecture. Comme les fichiers texte n'ont pas d'index, une lecture complète est nécessaire pour effectuer une recherche dans les fichiers.
Dans sa version la plus simple, l'Event Console utilise les noms des fichiers journaux comme index pour la période des événements. Plus vous limitez la période d'interrogation, plus la recherche est rapide.
Néanmoins, il est très important que votre archive ne devienne pas trop volumineuse. Si vous n'utilisez l'Event Console que pour traiter des messages d'erreur réels, cela ne peut pas vraiment se produire. Si vous essayez d'utiliser l'EC en remplacement d'une véritable archive syslog, cela peut conduire à des fichiers très volumineux.
Si votre archive devient trop volumineuse, vous pouvez simplement supprimer les anciens fichiers dans ~/var/mkeventd/history/. En outre, dans Event history lifetime, vous pouvez généralement limiter la durée de vie des données afin que la suppression soit la règle par défaut à l'avenir. Par défaut, 365 jours sont stockés. Vous pouvez peut-être vous contenter d'une durée nettement inférieure.
11.4. Mesurer les performances dans le temps
Checkmk démarre automatiquement un service pour chaque instance de l'Event Console, qui enregistre ses données de performance sous forme de courbes et vous avertit également en cas de débordement.
Pour autant que vous ayez installé un agent Linux sur le serveur de surveillance, le check sera automatiquement trouvé et configuré comme d'habitude :

Le check est livré avec de nombreux types de mesures intéressantes, par exemple le nombre de messages entrants pour chaque période de temps et combien d'entre eux ont été rejetés :
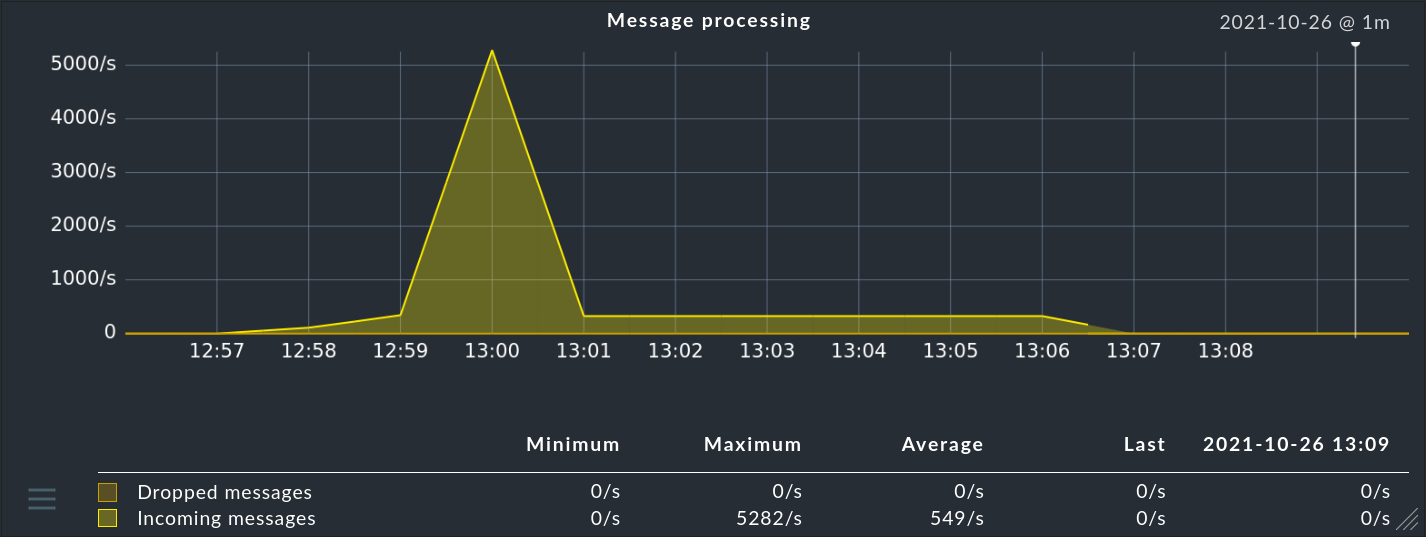
L'efficacité de votre chaîne de règles est représentée par une comparaison entre les règles testées et celles qui ont fonctionné :
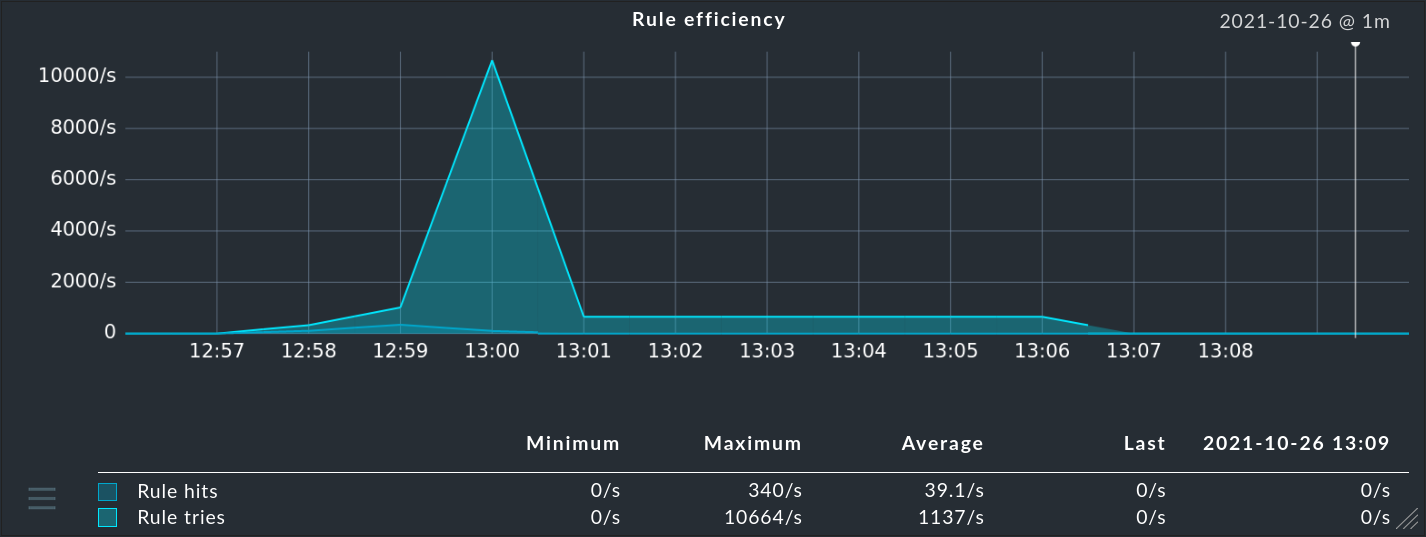
Ce graphique montre le temps moyen de traitement d'un message :
Il y a aussi pas mal de graphiques supplémentaires.
12. Surveillance distribuée
Pour savoir comment utiliser l'Event Console dans une installation comportant plusieurs instances Checkmk, consultez l'article sur la surveillance distribuée.
13. L'interface d'état
L'Event Console, via la socket Unix ~/tmp/run/mkeventd/status, permet d'accéder à l'état interne et d'exécuter des instructions. Le protocole utilisé ici est un sous-ensemble très restreint de Livestatus. Le noyau de surveillance accède à cette interface et transmet les données à l'interface graphique afin d'assurer une surveillance distribuée pour l'Event Console également.
Les restrictions suivantes s'appliquent au Livestatus simplifié de l'Event Console :
Les seuls en-têtes autorisés sont
Filter:etOutputFormat:.Par conséquent, aucun KeepAlive n'est possible, une seule demande peut être faite par connexion.
Les tableaux suivants sont disponibles :
|
Liste de tous les événements en cours. |
|
Accès aux archives. Une requête sur cette table permet d'accéder aux fichiers texte de l'archive. Veillez à utiliser un filtre sur l'heure de l'entrée afin d'éviter un accès complet à tous les fichiers. |
|
Valeurs d'état et de performance de la CE. Ce tableau comporte toujours une seule ligne. |
Les instructions peuvent être écrites dans la socket en utilisant unixcat avec une syntaxe très simple :
OMD[mysite]:~$ echo "COMMAND RELOAD" | unixcat tmp/run/mkeventd/statusLes instructions suivantes sont disponibles :
|
Archiver un événement. Arguments : ID de l'événement et abréviation de l'utilisateur. |
|
Recharge la configuration. |
|
Quitte l'Event Console. |
|
Rouvre le fichier journal. Cette instruction est requise par la rotation du fichier journal. |
|
Supprime tous les événements actuels et archivés. |
|
Lance une mise à jour immédiate du fichier |
|
Réinitialise les compteurs d'occurrences des règles (correspond à l'élément de menu Event Console > Reset counters dans l'interface graphique). |
|
Exécute une mise à jour à partir d'un événement. Les arguments sont, dans l'ordre, l'identifiant de l'événement, l'abréviation de l'utilisateur, la confirmation (0/1), le commentaire et les coordonnées du contact. |
|
Modifie les états OK / WARN / CRIT / UNKNOWN d'un événement. Les arguments sont l'ID de l'événement, l'abréviation de l'utilisateur et le chiffre d'état ( |
|
Exécute une action définie par l'utilisateur sur un événement. Les arguments sont l'ID de l'événement, l'abréviation de l'utilisateur et l'ID de l'action. L'ID spécial |
14. Fichiers et répertoires
| Chemin d'accès du fichier | Description du fichier |
|---|---|
|
Répertoire de travail du daemon d'événements. |
|
État actuel complet de l'Event Console. Il s'agit principalement de tous les événements actuellement ouverts (et de ceux qui sont en phase de transition, comme counting, etc.). Dans le cas d'une mauvaise configuration entraînant un grand nombre d'événements ouverts, ce fichier peut devenir énorme et réduire considérablement les performances de la CE. Dans une telle situation, vous pouvez arrêter le service |
|
Emplacement du fichier de l'archive. |
|
Fichier journal de l'Event Console. |
|
Les paramètres globaux de l'Event Console en syntaxe Python. |
|
Tous vos paquets de règles et règles configurés en syntaxe Python. |
|
Un tuyau nommé où vous pouvez écrire des messages directement avec |
|
Une socket Unix qui fait le même travail que le pipe, mais qui permet à plusieurs applications d'y écrire simultanément. Pour y écrire, vous devez utiliser l'instruction |
|
L'identifiant du processus en cours du daemon d'événements lorsqu'il est en marche. |
|
Une socket Unix qui permet d'interroger l'état actuel et d'envoyer des instructions. Les requêtes de l'interface graphique vont d'abord au noyau de surveillance, qui accède ensuite à cette socket. |
|
Les fichiers MIB que vous avez téléchargés pour la traduction des trap SNMP. |